
こんにちは、JS2IIUです。DataFrameの一部分要素を取り出して操作することはPandasを使うにあたって必要となってきます。使い方を把握して、使いこなせるようにしていきましょう。今回もよろしくお願いします。
はじめに
Pandasは、Pythonでデータ分析や処理を行う際の必須ライブラリです。その基本構造であるDataFrameは、行と列のラベル付きデータを格納する2次元のデータ構造で、多くの場面で利用されています。データに効率的にアクセスすることは、データ分析の基本スキルです。
この記事では、DataFrameの要素にアクセスする方法を詳しく解説します。特に以下のトピックを中心に扱います。
- ラベルベースのアクセス方法(
.loc)とインデックスベースのアクセス方法(.iloc) - カラムや行への個別アクセスと条件に基づくフィルタリング
- 高速な要素アクセスを可能にする
.atと.iat
これらを正確に使い分けることで、効率的かつ柔軟にデータを操作できるようになります。
DataFrameの要素アクセス方法
Pandasには、さまざまな方法でDataFrameの要素へアクセスできます。それぞれの使い方と特長を理解しておくと、状況に応じた適切な選択が可能になります。
1. .loc(ラベルベースのアクセス)
- 概要: 行や列の「ラベル」を使用してアクセスします。
- 用途: 行名や列名が分かっている場合に便利です。スライスや条件式によるフィルタリングも可能です。

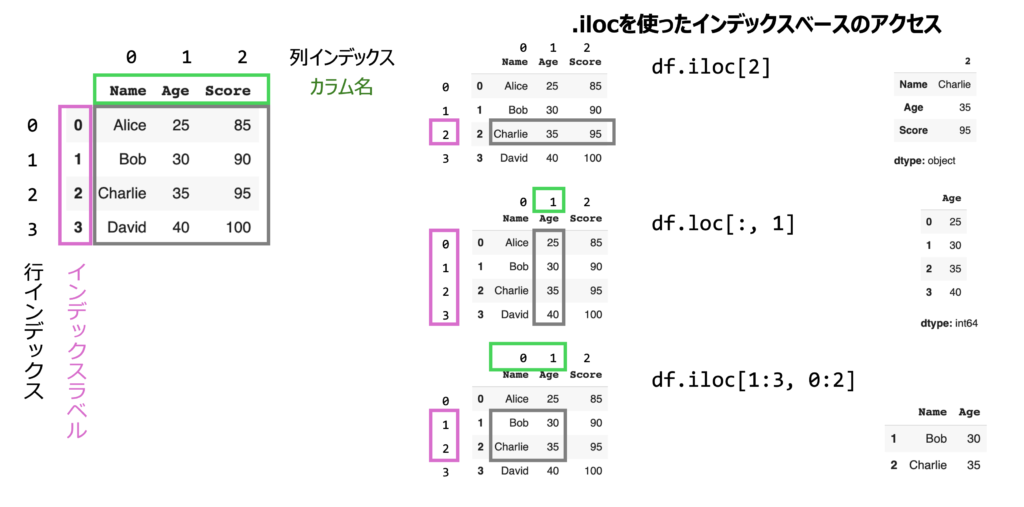
2. .iloc(インデックスベースのアクセス)
- 概要: 行や列の「位置」を使用してアクセスします(0から始まる整数インデックス)。
- 用途: ラベルが不明でも、行・列の番号が分かっている場合に使用します。
3. .at(単一要素への高速アクセス)
- 概要: 行と列のラベルを指定して1つの要素に高速にアクセスします。
- 用途: ラベル指定で、頻繁に単一要素を参照・更新する場合。

4. .iat(インデックスベースの高速アクセス)
- 概要: 行と列の位置を指定して1つの要素に高速にアクセスします。
- 用途: インデックス指定で、頻繁に単一要素を参照・更新する場合。
サンプルコード
以下は、さまざまな要素アクセス方法を使った例です。
import pandas as pd
# サンプルデータを作成
data = {
"Name": ["Alice", "Bob", "Charlie", "David"],
"Age": [25, 30, 35, 40],
"Score": [85, 90, 95, 100]
}
df = pd.DataFrame(data)
# 1. .loc を使ったラベルベースのアクセス
row_by_label = df.loc[1] # ラベル(行名)で行を取得
col_by_label = df.loc[:, "Age"] # ラベルで列を取得
filtered_by_condition = df.loc[df["Score"] > 90] # 条件フィルタリング
# 2. .iloc を使ったインデックスベースのアクセス
row_by_index = df.iloc[2] # 行インデックスで取得
col_by_index = df.iloc[:, 1] # 列インデックスで取得
sliced_data = df.iloc[1:3, 0:2] # スライスで部分取得
# 3. .at を使った単一要素へのアクセス
single_value_at = df.at[0, "Name"] # ラベルでアクセス
# 4. .iat を使った単一要素へのアクセス
single_value_iat = df.iat[2, 2] # インデックスでアクセス
# 結果を表示
print("DataFrame:\n", df)
print("\n.locでラベルベースの行取得:\n", row_by_label)
print("\n.locでラベルベースの列取得:\n", col_by_label)
print("\n.locで条件フィルタリング:\n", filtered_by_condition)
print("\n.ilocでインデックスベースの行取得:\n", row_by_index)
print("\n.ilocでスライス取得:\n", sliced_data)
print("\n.atで単一要素取得:", single_value_at)
print("\n.iatで単一要素取得:", single_value_iat)
コードの解説
サンプルデータの作成
pd.DataFrameを使って、名前・年齢・スコアを含むデータを作成します。
.locの使用
df.loc[1]でラベル1に該当する行を取得します。df.loc[:, "Age"]でAge列全体を取得します。df.loc[df["Score"] > 90]で、Scoreが90より大きい行をフィルタリングします。
.ilocの使用
df.iloc[2]で3番目の行(インデックス2)を取得します。df.iloc[:, 1]で2番目の列(インデックス1)を取得します。df.iloc[1:3, 0:2]で特定範囲の部分データを取得します。
.atと.iatの使用
.atはラベルを使って単一の要素に高速アクセスします(例:df.at[0, "Name"])。.iatはインデックスを使って単一の要素に高速アクセスします(例:df.iat[2, 2])。
実行結果
上記のコードを実行すると、以下のような結果が得られます。
DataFrame:
Name Age Score
0 Alice 25 85
1 Bob 30 90
2 Charlie 35 95
3 David 40 100
.locでラベルベースの行取得:
Name Bob
Age 30
Score 90
Name: 1, dtype: object
.locでラベルベースの列取得:
0 25
1 30
2 35
3 40
Name: Age, dtype: int64
.locで条件フィルタリング:
Name Age Score
2 Charlie 35 95
3 David 40 100
.ilocでインデックスベースの行取得:
Name Charlie
Age 35
Score 95
Name: 2, dtype: object
.ilocでスライス取得:
Name Age
1 Bob 30
2 Charlie 35
.atで単一要素取得: Alice
.iatで単一要素取得: 95
まとめ
.locと.ilocを使い分けることで、ラベルベースとインデックスベースの柔軟なアクセスが可能です。- 条件フィルタリングを活用すれば、データ分析が効率的に行えます。
.atと.iatは高速に単一要素にアクセスするために最適です。
参考リンク
- Pandas Official Documentation – DataFrame.loc
- Pandas Official Documentation – DataFrame.iloc
- Pandas Official Documentation – DataFrame.at
- Pandas Official Documentation – DataFrame.iat
今回も少しだけPRです。
Pandasについて詳しく知りたいかた、もっと使いこなしたい方におすすめの本です。数年前に購入しましたが、今も手元に置いて時々見返しています。
「pandasクックブック Pythonによるデータ処理のレシピ」Theodore Petrou著、黒川利明訳。
最後まで読んでいただきありがとうございます。73


コメント