
こんにちは、JS2IIUです。
今回はデータ分析に欠かせない、欠損値処理、外れ値除去などのデータクリーニング機能をStreamlit上に実装していきます。今回もよろしくお願いします。
1. はじめに
データ分析や機械学習を行う上で、「前処理」は欠かせないステップです。
生のデータには「欠損値」や「外れ値」が含まれていることが多く、そのままでは正しい分析ができません。
この記事では、Streamlitを使って、GUIから手軽に前処理ができるアプリを作成します。
2. Streamlitとは?
Streamlit は、Pythonで簡単にWebアプリを作れるライブラリです。
以下のような特徴があります。
- シンプルなコードでインタラクティブなUIが作れる
- データの表示や操作に強い
- ローカル環境でもすぐに起動できる
この記事では、Streamlitを使って、欠損値処理や外れ値除去をボタン一つで行える前処理アプリを作っていきます。
3. データ前処理とは?
データ前処理にはいくつかのステップがありますが、今回は以下の2つにフォーカスします。
欠損値(NaN)の処理
- データが一部欠けている状態
- 例:年齢列に空白がある
- 処理方法:
- 欠損行を削除
- 平均値や中央値で補完
外れ値の処理
- 他のデータと極端に異なる値
- 例:年齢が200歳など
- 処理方法:
- 範囲外データを除去(IQRなどの統計手法)
4. サンプルデータの準備
まずは、前処理を試すためのサンプルデータを作成しましょう。
import pandas as pd
import numpy as np
# サンプルデータ生成関数
def create_sample_data():
np.random.seed(42)
data = {
"年齢": np.append(np.random.randint(20, 60, 18), [200, np.nan]), # 外れ値と欠損値あり
"収入": np.append(np.random.randint(300, 800, 18), [5000, np.nan]), # 外れ値と欠損値あり
}
df = pd.DataFrame(data)
return dfこの関数を使って、Streamlitアプリ内で自動的にデータを生成します。
また、CSVファイルをアップロードして使う機能も後ほど追加します。
作成されるDataFrameデータは次のようなものです。
年齢 収入
0 58.0 791.0
1 48.0 713.0
2 34.0 593.0
3 27.0 685.0
4 40.0 491.0
5 58.0 743.0
6 38.0 576.0
7 42.0 460.0
8 30.0 759.0
9 30.0 613.0
10 43.0 321.0
11 55.0 552.0
12 59.0 535.0
13 43.0 644.0
14 22.0 348.0
15 41.0 774.0
16 21.0 358.0
17 43.0 469.0
18 200.0 5000.0
19 NaN NaN5. Streamlitアプリの実装
🔧 必要なライブラリのインストール
まずは以下のライブラリをインストールしておきましょう。
pip install streamlit pandas numpy5-1. アプリの基本構造
import streamlit as st
import pandas as pd
import numpy as np
# サンプルデータ生成
def create_sample_data():
np.random.seed(42)
data = {
"年齢": np.append(np.random.randint(20, 60, 18), [200, np.nan]),
"収入": np.append(np.random.randint(300, 800, 18), [5000, np.nan]),
}
return pd.DataFrame(data)
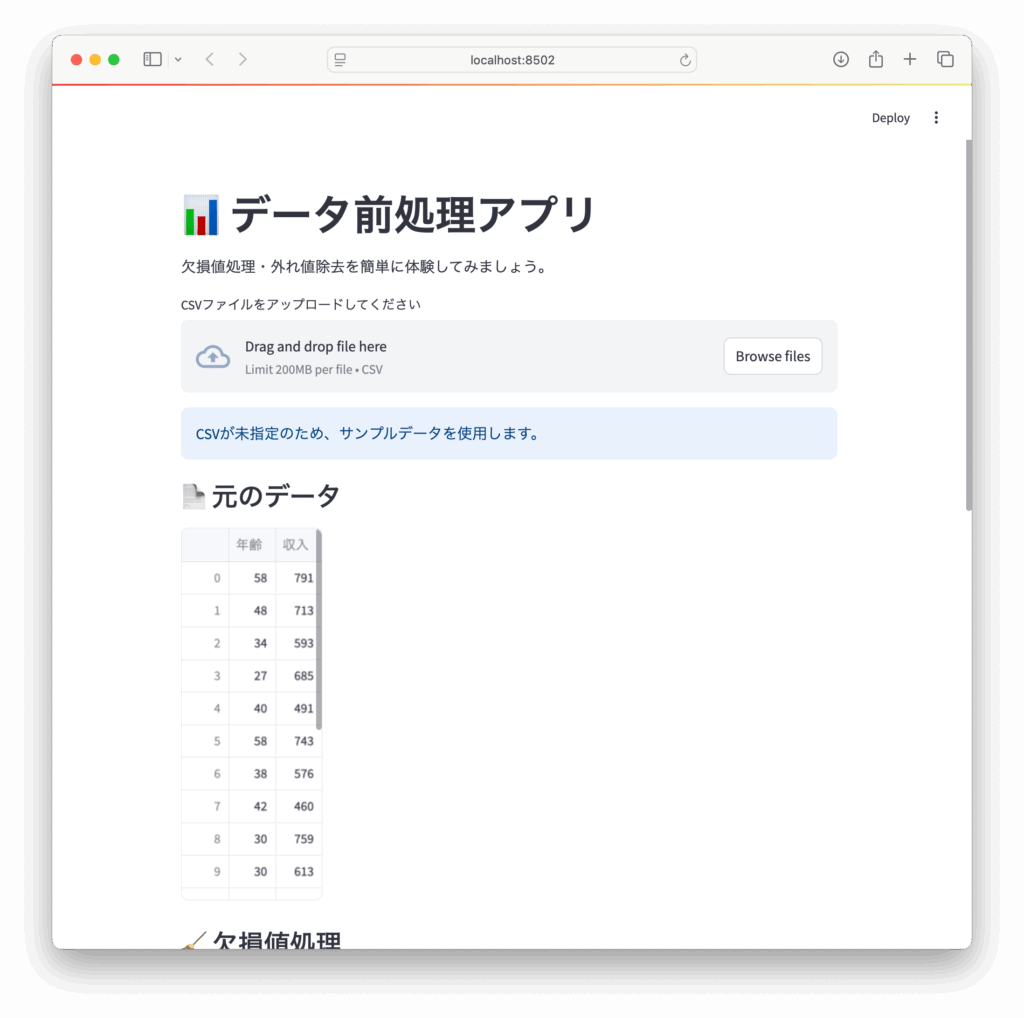
st.title("📊 データ前処理アプリ")
st.write("欠損値処理・外れ値除去を簡単に体験してみましょう。")
# データの読み込み
uploaded_file = st.file_uploader("CSVファイルをアップロードしてください", type="csv")
if uploaded_file:
df = pd.read_csv(uploaded_file)
st.success("CSVファイルを読み込みました。")
else:
st.info("CSVが未指定のため、サンプルデータを使用します。")
df = create_sample_data()
st.subheader("📄 元のデータ")
st.dataframe(df)✅ 1. ライブラリのインポート
import streamlit as st
import pandas as pd
import numpy as npstreamlit: Webアプリを作成するためのライブラリpandas: データの読み込み・操作用ライブラリnumpy: 数値計算・乱数生成などを行うライブラリ
✅ 2. サンプルデータの作成関数
def create_sample_data():
np.random.seed(42)
data = {
"年齢": np.append(np.random.randint(20, 60, 18), [200, np.nan]),
"収入": np.append(np.random.randint(300, 800, 18), [5000, np.nan]),
}
return pd.DataFrame(data)np.random.seed(42): 乱数を毎回同じ値にする(再現性を保つため)"年齢"と"収入"列にそれぞれランダムな値を生成- 各列の最後に 外れ値(200, 5000)と欠損値(
np.nan) を追加 pandas.DataFrameで表形式に整える
✅ 3. タイトルと説明の表示
st.title("📊 データ前処理アプリ")
st.write("欠損値処理・外れ値除去を簡単に体験してみましょう。")- アプリのタイトルと簡単な説明を画面に表示
✅ 4. データの読み込み(ファイルアップロード)
uploaded_file = st.file_uploader("CSVファイルをアップロードしてください", type="csv")
if uploaded_file:
df = pd.read_csv(uploaded_file)
st.success("CSVファイルを読み込みました。")
else:
st.info("CSVが未指定のため、サンプルデータを使用します。")
df = create_sample_data()- ユーザーがCSVファイルをアップロードできるようにする
- ファイルがあれば
pandas.read_csv()で読み込み - アップロードがなければ
create_sample_data()を使ってサンプルデータを使う
✅ 5. データの表示
st.subheader("📄 元のデータ")
st.dataframe(df)
- 前処理前のデータを表形式(
DataFrame)で表示
5-2. 欠損値処理の実装
st.subheader("🧹 欠損値処理")
missing_summary = df.isnull().sum()
st.write("各列の欠損値数:")
st.write(missing_summary)
method = st.radio("欠損値の処理方法を選択してください", ["そのままにする", "行を削除", "平均値で補完", "中央値で補完"])
if method == "行を削除":
df = df.dropna()
elif method == "平均値で補完":
df = df.fillna(df.mean(numeric_only=True))
elif method == "中央値で補完":
df = df.fillna(df.median(numeric_only=True))
st.write("欠損値処理後のデータ:")
st.dataframe(df)✅ 1. 欠損値処理セクションのタイトル表示
st.subheader("🧹 欠損値処理")- 「🧹 欠損値処理」という小見出しを画面に表示します。
✅ 2. 欠損値の個数を確認
missing_summary = df.isnull().sum()
st.write("各列の欠損値数:")
st.write(missing_summary)df.isnull():各要素が欠損かどうかをTrue/Falseで示すDataFrameを作成.sum():列ごとにTrueの数(= 欠損値の数)を合計- それをStreamlitで表示
✅ 3. 欠損値の処理方法をユーザーに選ばせる
method = st.radio("欠損値の処理方法を選択してください", ["そのままにする", "行を削除", "平均値で補完", "中央値で補完"])st.radio()でユーザーに欠損値の対処方法を選択させる- 選択肢は以下の4つ:
- 「そのままにする」→ 何もしない
- 「行を削除」→ 欠損を含む行を消す
- 「平均値で補完」→ 各列の平均値でNaNを埋める
- 「中央値で補完」→ 各列の中央値でNaNを埋める
✅ 4. 選択に応じた処理の実行
if method == "行を削除":
df = df.dropna()
elif method == "平均値で補完":
df = df.fillna(df.mean(numeric_only=True))
elif method == "中央値で補完":
df = df.fillna(df.median(numeric_only=True))dropna():欠損がある行をまるごと削除fillna():欠損値に別の値を代入して補完df.mean(numeric_only=True):数値列の平均値を計算df.median(numeric_only=True):数値列の中央値を計算numeric_only=Trueを指定することで、文字列列などは無視
✅ 5. 処理後のデータを表示
st.write("欠損値処理後のデータ:")
st.dataframe(df)- ユーザーが選んだ方法で前処理されたデータを画面に表示
5-3. 外れ値の処理
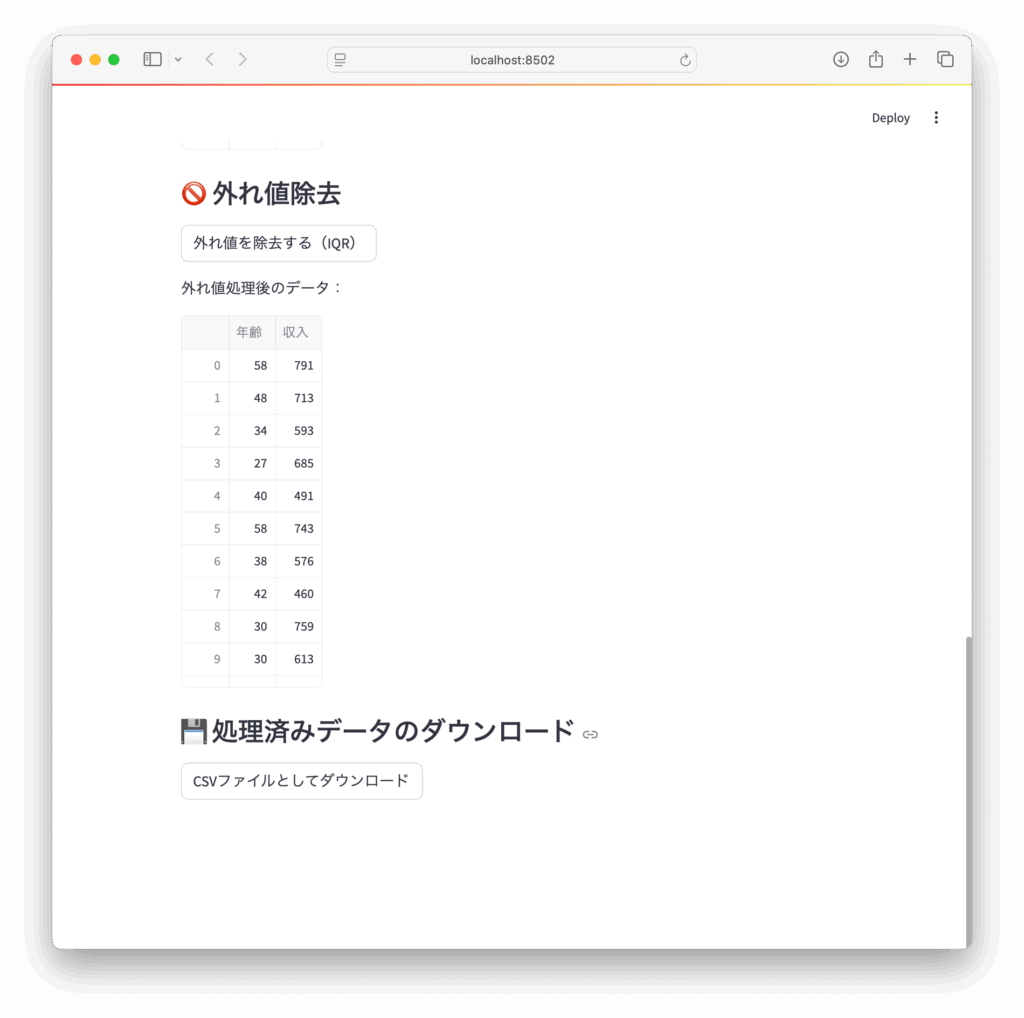
st.subheader("🚫 外れ値除去")
def remove_outliers_iqr(dataframe):
df_clean = dataframe.copy()
for col in df_clean.select_dtypes(include=["number"]).columns:
q1 = df_clean[col].quantile(0.25)
q3 = df_clean[col].quantile(0.75)
iqr = q3 - q1
lower = q1 - 1.5 * iqr
upper = q3 + 1.5 * iqr
df_clean = df_clean[(df_clean[col] >= lower) & (df_clean[col] <= upper)]
return df_clean
if st.button("外れ値を除去する(IQR)"):
df = remove_outliers_iqr(df)
st.success("外れ値を除去しました。")
st.write("外れ値処理後のデータ:")
st.dataframe(df)✅ 1. セクションの見出し表示
st.subheader("🚫 外れ値除去")
- 「外れ値除去」という小見出しを表示して、次の処理の目的を明示します。
✅ 2. 外れ値を除去する関数の定義(IQR法)
def remove_outliers_iqr(dataframe):
df_clean = dataframe.copy()
for col in df_clean.select_dtypes(include=["number"]).columns:
q1 = df_clean[col].quantile(0.25)
q3 = df_clean[col].quantile(0.75)
iqr = q3 - q1
lower = q1 - 1.5 * iqr
upper = q3 + 1.5 * iqr
df_clean = df_clean[(df_clean[col] >= lower) & (df_clean[col] <= upper)]
return df_clean
🔍 何をしているのか?
この関数は、IQR(四分位範囲) を使って数値データの外れ値を除去します。
🔢 手順の流れ:
df_clean = dataframe.copy():元のデータを壊さないようにコピーselect_dtypes(include=["number"]):数値列だけを対象にする- 各列で以下を計算:
- Q1(25%点)
- Q3(75%点)
- IQR = Q3 – Q1
- 下限:Q1 – 1.5×IQR
- 上限:Q3 + 1.5×IQR
- その範囲に 収まっている行だけを残す(外れ値を削除)
✅ 3. ボタンを押したら外れ値を除去
if st.button("外れ値を除去する(IQR)"):
df = remove_outliers_iqr(df)
st.success("外れ値を除去しました。")
- 「外れ値を除去する(IQR)」というボタンが表示される
- ユーザーが押すと
remove_outliers_iqr()関数を実行し、外れ値を削除 - 成功メッセージが表示される
✅ 4. 外れ値処理後のデータを表示
st.write("外れ値処理後のデータ:")
st.dataframe(df)
- 外れ値を除去したあとのデータを表形式で表示します
🔍 IQR法とは?
IQR(Interquartile Range:四分位範囲) を使って、統計的に“外れた値”を見つけて除外する方法です。
💡 そもそも「四分位数」とは?
データを小さい順に並べて、以下の位置で分割します:
- Q1(第一四分位数):下から25%の位置の値(全体の下位1/4点)
- Q2(第二四分位数、中央値):ちょうど真ん中(50%地点)
- Q3(第三四分位数):上から25%を除いた75%地点(上位1/4の境界)
🔢 IQRの計算方法
IQR = Q3 - Q1
- データの「中央50%」の範囲を表す指標です
- この範囲が“普通”のばらつきとみなされます
🚫 外れ値の定義(IQRルール)
IQRの上下に1.5倍分の幅をとって、それを超える値を「外れ値」と見なします。
下限値 = Q1 - 1.5 × IQR
上限値 = Q3 + 1.5 × IQR
- この範囲 外 にある値は「外れ値(Outlier)」と判定されます。
✅ 具体例
たとえば次のようなデータがあったとします:
[10, 12, 13, 15, 18, 19, 21, 22, 200]
- Q1 = 13
- Q3 = 21
- IQR = 21 – 13 = 8
計算:
- 下限 = 13 – 1.5×8 = 1
- 上限 = 21 + 1.5×8 = 33
→ この範囲(1〜33)を超える値 は外れ値 → 200 が外れ値!
✅ なぜIQR法が使われる?
- 平均と標準偏差による方法だと、すでにある外れ値が平均を大きく動かしてしまう
- IQRは中央値と四分位数を使うので、極端な値に強く影響されにくい(ロバスト)
🛠️ 実用面での特徴
| 特徴 | 内容 |
|---|---|
| メリット | 簡単で視覚的にわかりやすい、極端な値に強い |
| デメリット | 分布の形状を考慮しない、正規分布でないとやや不正確なことも |
5-4. CSVとしてダウンロード
st.subheader("💾 処理済みデータのダウンロード")
csv = df.to_csv(index=False).encode("utf-8")
st.download_button(
label="CSVファイルとしてダウンロード",
data=csv,
file_name="cleaned_data.csv",
mime="text/csv",
)6. アプリ全体のコード
すべてのコードを1つにまとめると、以下のようになります:
import streamlit as st
import pandas as pd
import numpy as np
# サンプルデータ生成
def create_sample_data():
np.random.seed(42)
data = {
"年齢": np.append(np.random.randint(20, 60, 18), [200, np.nan]),
"収入": np.append(np.random.randint(300, 800, 18), [5000, np.nan]),
}
return pd.DataFrame(data)
st.title("📊 データ前処理アプリ")
st.write("欠損値処理・外れ値除去を簡単に体験してみましょう。")
# データの読み込み
uploaded_file = st.file_uploader("CSVファイルをアップロードしてください", type="csv")
if uploaded_file:
df = pd.read_csv(uploaded_file)
st.success("CSVファイルを読み込みました。")
else:
st.info("CSVが未指定のため、サンプルデータを使用します。")
df = create_sample_data()
st.subheader("📄 元のデータ")
st.dataframe(df)
st.subheader("🧹 欠損値処理")
missing_summary = df.isnull().sum()
st.write("各列の欠損値数:")
st.write(missing_summary)
method = st.radio("欠損値の処理方法を選択してください", ["そのままにする", "行を削除", "平均値で補完", "中央値で補完"])
if method == "行を削除":
df = df.dropna()
elif method == "平均値で補完":
df = df.fillna(df.mean(numeric_only=True))
elif method == "中央値で補完":
df = df.fillna(df.median(numeric_only=True))
st.write("欠損値処理後のデータ:")
st.dataframe(df)
st.subheader("🚫 外れ値除去")
def remove_outliers_iqr(dataframe):
df_clean = dataframe.copy()
for col in df_clean.select_dtypes(include=["number"]).columns:
q1 = df_clean[col].quantile(0.25)
q3 = df_clean[col].quantile(0.75)
iqr = q3 - q1
lower = q1 - 1.5 * iqr
upper = q3 + 1.5 * iqr
df_clean = df_clean[(df_clean[col] >= lower) & (df_clean[col] <= upper)]
return df_clean
if st.button("外れ値を除去する(IQR)"):
df = remove_outliers_iqr(df)
st.success("外れ値を除去しました。")
st.write("外れ値処理後のデータ:")
st.dataframe(df)
st.subheader("💾 処理済みデータのダウンロード")
csv = df.to_csv(index=False).encode("utf-8")
st.download_button(
label="CSVファイルとしてダウンロード",
data=csv,
file_name="cleaned_data.csv",
mime="text/csv",
)
7. おわりに
このアプリを使えば、Pythonやデータ分析が初めての方でも、視覚的にデータの問題点を確認しながら、前処理を行うことができます。
今後は、以下のような機能の追加もおすすめです:
- 特徴量のスケーリング(正規化、標準化)
- カテゴリ変数のエンコーディング
- Streamlitでの機械学習モデルの実装
8. 参考リンク
最後に書籍のPRです。
24年11月に第3版が発行された「scikit-learn、Keras、TensorFlowによる実践機械学習 第3版」、Aurélien Géron 著。下田、牧、長尾訳。機械学習のトピックスについて手を動かしながら網羅的に学べる書籍です。ぜひ手に取ってみてください。
最後まで読んでいただきありがとうございます。


コメント