



こんにちは、JS2IIUです。
今回は特徴量エンジニアリングがテーマです。実用的な特徴量を作成してモデルの性能改善に挑戦する事例を取り上げます。今回もよろしくお願いします。
1. はじめに
特徴量エンジニアリング(Feature Engineering)とは、機械学習モデルの性能を高めるために、元のデータから有用な特徴量(変数)を作成・変換・選択するプロセスのことです。これは、モデル構築における最も重要かつ影響力の大きいステップの一つとされています。
🔍 特徴量エンジニアリングが使われる場面
特徴量エンジニアリングは、以下のような場面で活用されます:
- 教師あり学習(分類・回帰)
- 例:顧客の購買予測、病気の診断、住宅価格の予測など
- 教師なし学習(クラスタリング、次元削減)
- 例:ユーザーの行動をグループ化、主成分分析による可視化
- 時系列予測
- 例:株価や需要の予測(時刻・曜日・季節性の特徴量が重要)
- 自然言語処理
- 例:テキストのベクトル化(TF-IDFやWord2Vecなど)
🔧 主なテクニックと方法
以下は、代表的な特徴量エンジニアリングのテクニックです:
1. 特徴量の作成
- 既存の特徴から新しい特徴を生成
- 例:
年齢 = 現在年 - 生年、平均購入額 = 総購入額 / 購入回数
- 例:
2. カテゴリ変数の処理
- One-hot encoding(ワンホットエンコーディング):
- カテゴリを0/1のベクトルに変換(例:
性別 → [1, 0] or [0, 1])
- カテゴリを0/1のベクトルに変換(例:
- Label encoding:
- カテゴリを整数に変換(例:
「赤, 青, 緑」→ 0, 1, 2)
- カテゴリを整数に変換(例:
3. スケーリング・正規化
- 標準化(StandardScaler):平均0・分散1に変換
- 正規化(MinMaxScaler):値を0〜1にスケーリング
4. 欠損値の処理
- 平均値・中央値・最頻値などで補完
- 欠損の有無自体を特徴量として扱うことも
5. 時系列特徴の抽出
- 日時データから曜日、月、時間帯などを抽出
- 例:
2025-05-06→曜日=火, 月=5, 祝日か否か
- 例:
6. 交差特徴(Interaction Features)
- 複数の特徴を組み合わせて新しい情報を得る
- 例:
価格 × 数量→売上額
- 例:
7. 集約統計量の導入(GroupBy + 集計)
- グループ単位で平均や合計などを計算
- 例:顧客ごとの平均購入単価、カテゴリごとの売上合計
8. 次元削減(PCA、t-SNEなど)
- 多次元の特徴を少数の重要な成分に変換
2. 今回使うデータについて
UCIの「Heart Disease」データセットを使用します。このデータには、年齢、性別、血圧、コレステロール値など、心疾患のリスクに関係しそうな情報が含まれています。
分類問題として「心疾患があるか(target=1)/ないか(target=0)」を予測します。
UCI Machine Learning Repository
3. 使用するライブラリのインストール
pip install pandas scikit-learn matplotlib seaborn streamlit4. アプリの全体像
Streamlitアプリでは以下の機能を実装します:
- データの読み込みと確認
- 特徴量エンジニアリングの実施(BMI、年齢カテゴリなど)
- モデル精度の比較(特徴量あり/なし)
- 特徴量重要度の可視化


5. Streamlitアプリの実装(フルコード)
以下がアプリ全体のコードです。要所で丁寧に解説していきます。
📁 ファイル名:heart_feature_engineering_app.py
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
st.title("💓 心臓病予測と特徴量エンジニアリング")
st.markdown("新しく作成した特徴量がモデル精度に与える影響を可視化します。")
@st.cache_data
def load_data():
# download th dataset from UCI
df = pd.read_csv('processed.cleveland.data')
columns = ['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg',
'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'thal', 'target']
df.columns = columns
return df
df = load_data()
st.subheader("🔍 データプレビュー")
st.dataframe(df.head())
df['bmi'] = df['thalach'] / (df['age'] ** 2) # 例として仮のBMI計算
df['age_group'] = pd.cut(df['age'], bins=[0, 40, 55, 100], labels=['young', 'middle', 'senior'])
df['high_risk'] = ((df['trestbps'] > 140) & (df['chol'] > 240)).astype(int)
features_all = ['age', 'sex', 'cp', 'trestbps', 'chol', 'thalach', 'slope', 'bmi', 'age_group', 'high_risk']
df_model = df[features_all + ['target']].copy()
df_model = pd.get_dummies(df_model, columns=['cp', 'slope', 'age_group'], drop_first=True)
X_with = df_model.drop('target', axis=1)
X_without = X_with.drop(columns=['bmi', 'age_group_middle', 'age_group_senior', 'high_risk'], errors='ignore')
y = df_model['target']
X_train1, X_test1, y_train, y_test = train_test_split(X_without, y, test_size=0.3, random_state=0)
X_train2, X_test2, _, _ = train_test_split(X_with, y, test_size=0.3, random_state=0)
model1 = RandomForestClassifier(random_state=0)
model1.fit(X_train1, y_train)
pred1 = model1.predict(X_test1)
acc1 = accuracy_score(y_test, pred1)
model2 = RandomForestClassifier(random_state=0)
model2.fit(X_train2, y_train)
pred2 = model2.predict(X_test2)
acc2 = accuracy_score(y_test, pred2)
st.subheader("📈 モデルの精度比較")
st.metric("特徴量エンジニアリングなし", f"{acc1:.3f}")
st.metric("特徴量エンジニアリングあり", f"{acc2:.3f}")
importance_df = pd.DataFrame({
'feature': X_with.columns,
'importance': model2.feature_importances_
}).sort_values(by='importance', ascending=True)
st.subheader("🧠 特徴量の重要度(エンジニアリングありモデル)")
fig, ax = plt.subplots(figsize=(6, 8))
ax.barh(importance_df['feature'], importance_df['importance'], color='skyblue')
ax.set_xlabel("Importance")
ax.set_title("Feature Importances")
st.pyplot(fig)
部分ごとの解説
まずはデータセットを手に入れます。今回はUCIのデータセットを本家からダウンロードしてきました。
Heart Disease – UCI Machine Learning Repository
右上のDOWNLOADからダウンロードしてください。

以下のコードではデータを読み込んで、DataFrameに格納しています。カラム名はダウンロードしたファイルのうち、heart-disease.namesというファイルに記載がありました。
import streamlit as st
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
st.title("💓 心臓病予測と特徴量エンジニアリング")
st.markdown("新しく作成した特徴量がモデル精度に与える影響を可視化します。")
@st.cache_data
def load_data():
# download th dataset from UCI
df = pd.read_csv('processed.cleveland.data')
columns = ['age', 'sex', 'cp', 'trestbps', 'chol', 'fbs', 'restecg',
'thalach', 'exang', 'oldpeak', 'slope', 'ca', 'thal', 'target']
df.columns = columns
return df
df = load_data()
st.subheader("🔍 データプレビュー")
st.dataframe(df.head())Step 1:特徴量エンジニアリングの実施
以下のような新しい特徴量を作成します:
| 特徴量名 | 内容 |
|---|---|
bmi | 身長と体重からBMI(ここでは簡易的に weight / height^2 として仮定) |
age_group | 年齢をカテゴリに分割(young, middle, senior) |
high_risk | 高血圧かつ高コレステロールの条件を満たすか |
df['bmi'] = df['thalach'] / (df['age'] ** 2) # 例として仮のBMI計算
df['age_group'] = pd.cut(df['age'], bins=[0, 40, 55, 100], labels=['young', 'middle', 'senior'])
df['high_risk'] = ((df['trestbps'] > 140) & (df['chol'] > 240)).astype(int)✅ 1行目
df['bmi'] = df['thalach'] / (df['age'] ** 2)- 目的:年齢と最大心拍数(
thalach)を用いて仮のBMI的な指標を作成。 - 意味:
thalach ÷ age²の形で計算(実際のBMIとは異なるが、例としての新特徴)。 - 効果:年齢を考慮した相対的な心拍数指標として使えるかもしれない。
✅ 2行目
df['age_group'] = pd.cut(df['age'], bins=[0, 40, 55, 100], labels=['young', 'middle', 'senior'])- 目的:年齢をカテゴリに分類(ビン分割)。
- 意味:
- 0〜40歳 →
'young' - 40〜55歳 →
'middle' - 55〜100歳 →
'senior'
- 0〜40歳 →
- 効果:モデルで年齢を「若年・中年・高年齢層」として扱いやすくなる。
✅ 3行目
df['high_risk'] = ((df['trestbps'] > 140) & (df['chol'] > 240)).astype(int)- 目的:血圧とコレステロールの条件から高リスクかどうかの二値特徴量を作成。
- 意味:
- 安静時血圧(
trestbps)が140より大きく、 - コレステロール(
chol)が240より大きい場合に「1(高リスク)」、それ以外は「0」。
- 安静時血圧(
- 効果:医療的な知識に基づいたリスク指標をモデルに導入。
Step 2:前処理とダミー変換
features_all = ['age', 'sex', 'cp', 'trestbps', 'chol', 'thalach', 'slope', 'bmi', 'age_group', 'high_risk']
df_model = df[features_all + ['target']].copy()
df_model = pd.get_dummies(df_model, columns=['cp', 'slope', 'age_group'], drop_first=True)✅ 1行目
features_all = ['age', 'sex', 'cp', 'trestbps', 'chol', 'thalach', 'slope', 'bmi', 'age_group', 'high_risk']- 目的:使いたい特徴量(列)の一覧をリストに定義。
- 内容:
- 数値型特徴量:
age,sex,trestbps,chol,thalach,bmi,high_risk - カテゴリ型特徴量:
cp(胸痛タイプ)、slope(ST傾き)、age_group(年齢層)
- 数値型特徴量:
✅ 2行目
df_model = df[features_all + ['target']].copy()- 目的:必要な列だけを取り出して、新しいデータフレーム
df_modelを作成。target:目的変数(心疾患の有無など)を追加。.copy():元のdfに影響を与えないようコピーを作成。
✅ 3行目
df_model = pd.get_dummies(df_model, columns=['cp', 'slope', 'age_group'], drop_first=True)- 目的:カテゴリ変数を One-hotエンコーディング でダミー変数に変換。
columns:変換対象はcp,slope,age_group。drop_first=True:- 多重共線性を避けるため、各カテゴリの最初の値を自動的に落とす(基準値とする)。
- 例:
cpが4種類あれば、3列のダミー変数にする。
📦 最終的な結果
df_model は、数値変数 + ダミー変数 + 目的変数(target)を含む、モデル学習に直接使える形式のデータになります。
Step 3:モデル構築と比較
特徴量あり・なしでモデルを訓練し、精度を比較します。
X_with = df_model.drop('target', axis=1)
X_without = X_with.drop(columns=['bmi', 'age_group_middle', 'age_group_senior', 'high_risk'], errors='ignore')
y = df_model['target']
X_train1, X_test1, y_train, y_test = train_test_split(X_without, y, test_size=0.3, random_state=0)
X_train2, X_test2, _, _ = train_test_split(X_with, y, test_size=0.3, random_state=0)
model1 = RandomForestClassifier(random_state=0)
model1.fit(X_train1, y_train)
pred1 = model1.predict(X_test1)
acc1 = accuracy_score(y_test, pred1)
model2 = RandomForestClassifier(random_state=0)
model2.fit(X_train2, y_train)
pred2 = model2.predict(X_test2)
acc2 = accuracy_score(y_test, pred2)
st.subheader("📈 モデルの精度比較")
st.metric("特徴量エンジニアリングなし", f"{acc1:.3f}")
st.metric("特徴量エンジニアリングあり", f"{acc2:.3f}")✅ 特徴量と目的変数の分割
X_with = df_model.drop('target', axis=1)
X_without = X_with.drop(columns=['bmi', 'age_group_middle', 'age_group_senior', 'high_risk'], errors='ignore')
y = df_model['target']X_with:すべての特徴量(特徴量エンジニアリング済)を含む。X_without:エンジニアリングで追加された特徴量(bmi,age_group_*,high_risk)を除いたもの。y:目的変数(心疾患の有無)。
✅ データの分割(学習用とテスト用)
X_train1, X_test1, y_train, y_test = train_test_split(X_without, y, test_size=0.3, random_state=0)
X_train2, X_test2, _, _ = train_test_split(X_with, y, test_size=0.3, random_state=0)train_test_split():データを70%訓練用、30%テスト用に分割。- 両者で
y_train,y_testは同じになるようにrandom_state=0を指定。 X_train1:特徴量エンジニアリングなしX_train2:特徴量エンジニアリングあり
✅ ランダムフォレストモデルの学習・予測・評価
model1 = RandomForestClassifier(random_state=0)
model1.fit(X_train1, y_train)
pred1 = model1.predict(X_test1)
acc1 = accuracy_score(y_test, pred1)model1:エンジニアリングなしデータで学習。acc1:そのモデルのテストデータに対する精度。
model2 = RandomForestClassifier(random_state=0)
model2.fit(X_train2, y_train)
pred2 = model2.predict(X_test2)
acc2 = accuracy_score(y_test, pred2)model2:エンジニアリングありデータで学習。acc2:こちらの精度。
✅ Streamlitで精度を表示
st.subheader("📈 モデルの精度比較")
st.metric("特徴量エンジニアリングなし", f"{acc1:.3f}")
st.metric("特徴量エンジニアリングあり", f"{acc2:.3f}")- Streamlitを使って、2つのモデルの精度を比較表示。
- 小数点3桁で見やすくフォーマット。
📌 要点まとめ
| モデル | 特徴量 | 精度を測る目的 |
|---|---|---|
| model1 | 元データのみ | ベースライン精度 |
| model2 | 新たな特徴量を追加 | 精度向上の有無を確認 |
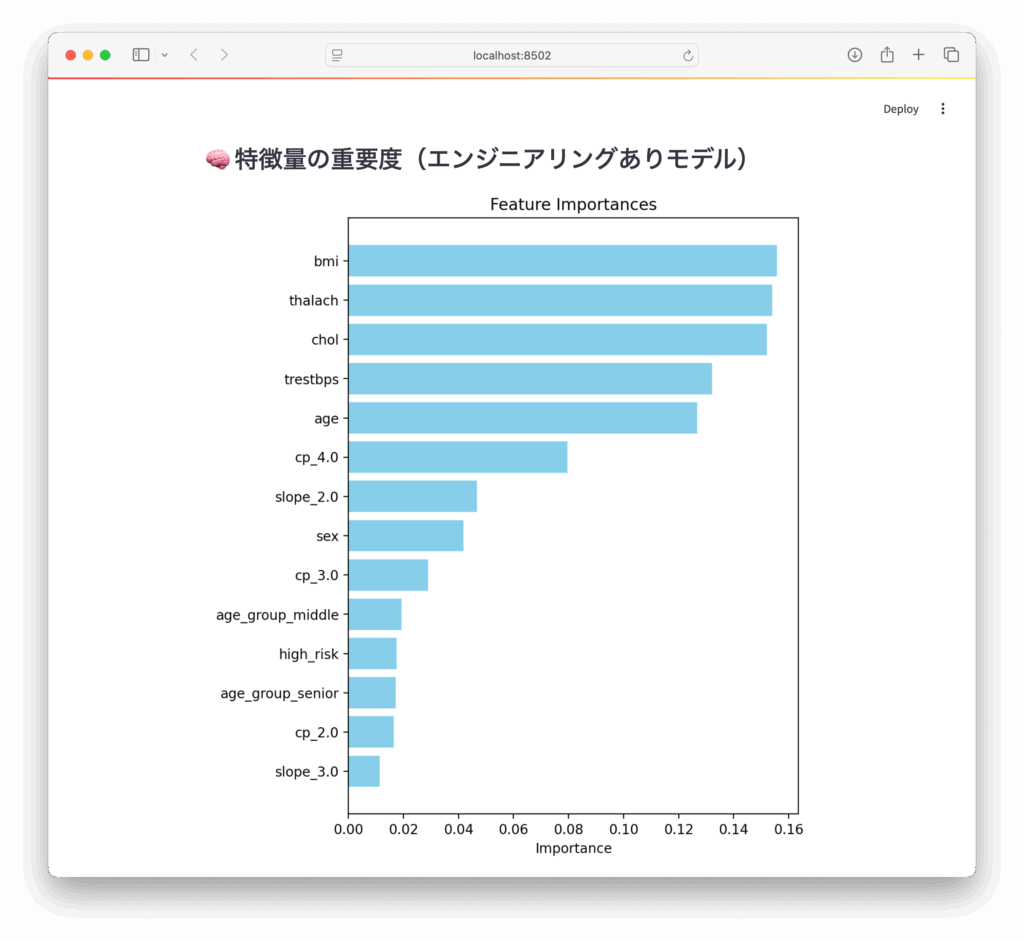
Step 4:特徴量重要度の可視化
AA importance_df = pd.DataFrame({
'feature': X_with.columns,
'importance': model2.feature_importances_
}).sort_values(by='importance', ascending=True)
st.subheader("🧠 特徴量の重要度(エンジニアリングありモデル)")
fig, ax = plt.subplots(figsize=(6, 8))
ax.barh(importance_df['feature'], importance_df['importance'], color='skyblue')
ax.set_xlabel("Importance")
ax.set_title("Feature Importances")
st.pyplot(fig)6. アプリの実行方法
保存したファイルを次のコマンドで実行:
streamlit run heart_feature_engineering_app.py7. 特徴量エンジニアリング振り返り
特徴量エンジニアリングとは、機械学習モデルが学習しやすいように、
既存のデータから有益な情報を抽出・加工して新しい特徴量を作る作業です。
たとえば:
- 数値の正規化やスケーリング
- 複数の項目を組み合わせて新しい意味をもたせる(例:BMI)
- ルールベースのフラグ(例:高血圧かどうか)
- カテゴリ分類(年齢 → 若者・中年・高齢)
モデルによっては精度向上に直結することも多く、データ分析では欠かせないテクニックです。
8. まとめ
- 特徴量エンジニアリングはモデル精度を高めるために非常に有効
- 「作って終わり」ではなく、「どの特徴量が効いたか」を可視化することが重要
- Streamlitを使うことで、データサイエンスの過程を手軽に共有・分析できます
9. 参考リンク
最後に書籍のPRです。
24年11月に第3版が発行された「scikit-learn、Keras、TensorFlowによる実践機械学習 第3版」、Aurélien Géron 著。下田、牧、長尾訳。機械学習のトピックスについて手を動かしながら網羅的に学べる書籍です。ぜひ手に取ってみてください。

最後まで読んでいただきありがとうございます。