



こんにちは、JS2IIUです。
機械学習モデルは高い予測精度を持つ一方で、その予測結果の根拠がわかりづらい「ブラックボックス」になりがちです。特に医療や金融などの分野では、なぜその予測が出たのかという“説明責任”が求められる場面も多くあります。
そこで本記事では、機械学習モデルの解釈性を高めるための手法「SHAP(SHapley Additive exPlanations)」と、それを可視化するStreamlitアプリの作成方法をステップバイステップで紹介します。
1. 環境準備
以下のPythonライブラリを使用します。
pip install streamlit shap scikit-learn pandas matplotlib2. 使用するデータとモデルの準備
まずは、scikit-learnの有名な糖尿病データセット(diabetes dataset)を使い、ランダムフォレスト回帰モデルを学習させます。
# 2_model_training.py
import pandas as pd
import shap
import sklearn
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# データの読み込み
X, y = load_diabetes(return_X_y=True, as_frame=True)
# 学習用・テスト用に分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの学習
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)解説
このコードでは、糖尿病の進行度を予測する回帰モデルを構築しています。以下、各ステップの役割を説明します。
ライブラリのインポート
import pandas as pd
import shap
import sklearnpandas:データ操作用ライブラリ。shap:SHAP値の計算・可視化に使います(後のステップで使用)。sklearn:機械学習モデルやデータセットの提供元。
糖尿病データセットの読み込み
X, y = load_diabetes(return_X_y=True, as_frame=True)X:患者の年齢や血圧など、複数の特徴量(説明変数)。y:それに対応する糖尿病の進行度(目的変数)。as_frame=Trueにより、pandas.DataFrame形式でデータが取得されます。
データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)- 学習用(80%)とテスト用(20%)にデータを分けます。
random_state=42は乱数のシード値で、毎回同じ分割になるように固定します。
ランダムフォレスト回帰モデルの学習
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)RandomForestRegressor:複数の決定木を組み合わせて予測精度を高める回帰モデル。.fit()で、訓練データを使ってモデルを学習させます。
3. SHAP値の計算
次に、SHAPライブラリを使って、モデルの各特徴量が予測にどれだけ影響したかを可視化します。
# shap_value_calc.py
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test)この shap_values に、各予測に対する特徴量の影響が格納されています。
📌 コードの解説
explainer = shap.Explainer(model, X_train)
- SHAPの「説明器(explainer)」を作成します。
model:学習済みのランダムフォレストモデル。X_train:モデルの学習に使ったデータ。- SHAPはこの学習データを元に、特徴量ごとの影響度を推定するロジックを構築します。
🚨 SHAPでは、どの特徴量がどのように予測に影響したかを知るために、学習データの統計的性質が重要です。
shap_values = explainer(X_test)
- 実際にテストデータに対するSHAP値を計算しています。
shap_valuesには、各サンプル・各特徴量に対して、- プラスの影響(予測を押し上げる)か、
- マイナスの影響(予測を押し下げる)か、
- どの程度の寄与か
がすべて含まれています。
4. SHAPの可視化
代表的な可視化方法は以下の通りです。
4-1. Summary Plot(全体の特徴量重要度)
import matplotlib.pyplot as plt
shap.summary_plot(shap_values, X_test)4-2. Force Plot(個別の予測根拠)
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[0], X_test.iloc[0], matplotlib=True)このように、SHAPを使えば個別の予測に対して「どの特徴量がどう影響したのか」を明確に視覚化できます。
5. Streamlitアプリで可視化する
ここからは、Streamlitを使ってSHAPの可視化をインタラクティブなWebアプリとして表示する方法を紹介します。
5-1. Streamlitアプリの基本構成
import streamlit as st
import shap
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
import streamlit.components.v1 as components
# データとモデルの準備
X, y = load_diabetes(return_X_y=True, as_frame=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = RandomForestRegressor(random_state=42)
model.fit(X_train, y_train)
# SHAPの計算(check_additivity=False で誤差許容)
# explainer = shap.TreeExplainer(model)
explainer = shap.Explainer(model)
shap_values = explainer(X_test)
# shap_values = explainer(X_test, check_additivity=False)
st.title("SHAPによるモデルの解釈")
# Summary Plot表示
st.header("Summary Plot(特徴量の影響の全体像)")
fig_summary = plt.figure()
shap.summary_plot(shap_values, X_test, show=False)
st.pyplot(fig_summary)
# Force Plotの表示(サンプル選択)
st.header("WaterFall Plot(個別予測の説明)")
index = st.slider("表示するサンプルのインデックス", 0, len(X_test) - 1, 0)
# Waterfall Plot
fig, ax = plt.subplots(figsize=(10, 3))
# waterfall プロットを代わりに使用
shap.plots.waterfall(shap_values[index], show=False, max_display=15)
st.pyplot(plt.gcf())Streamlit上でSHAPのプロットを切り替えたり、特定の予測結果を詳しく見たりできるようになっています。

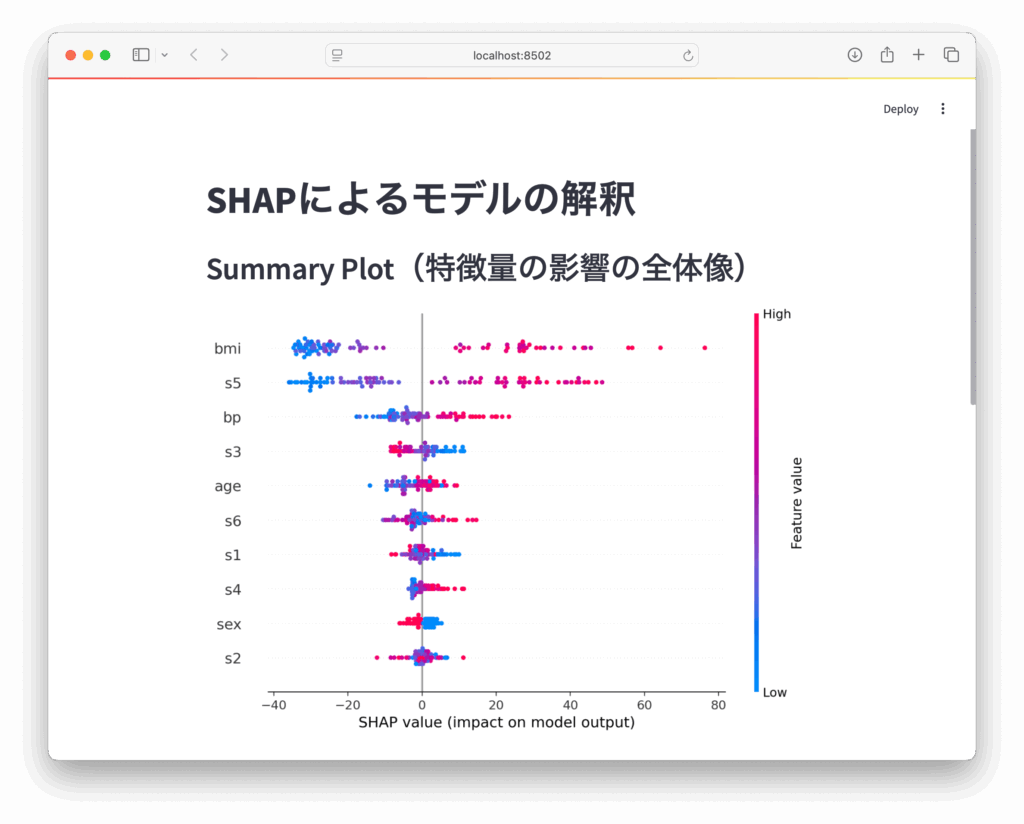

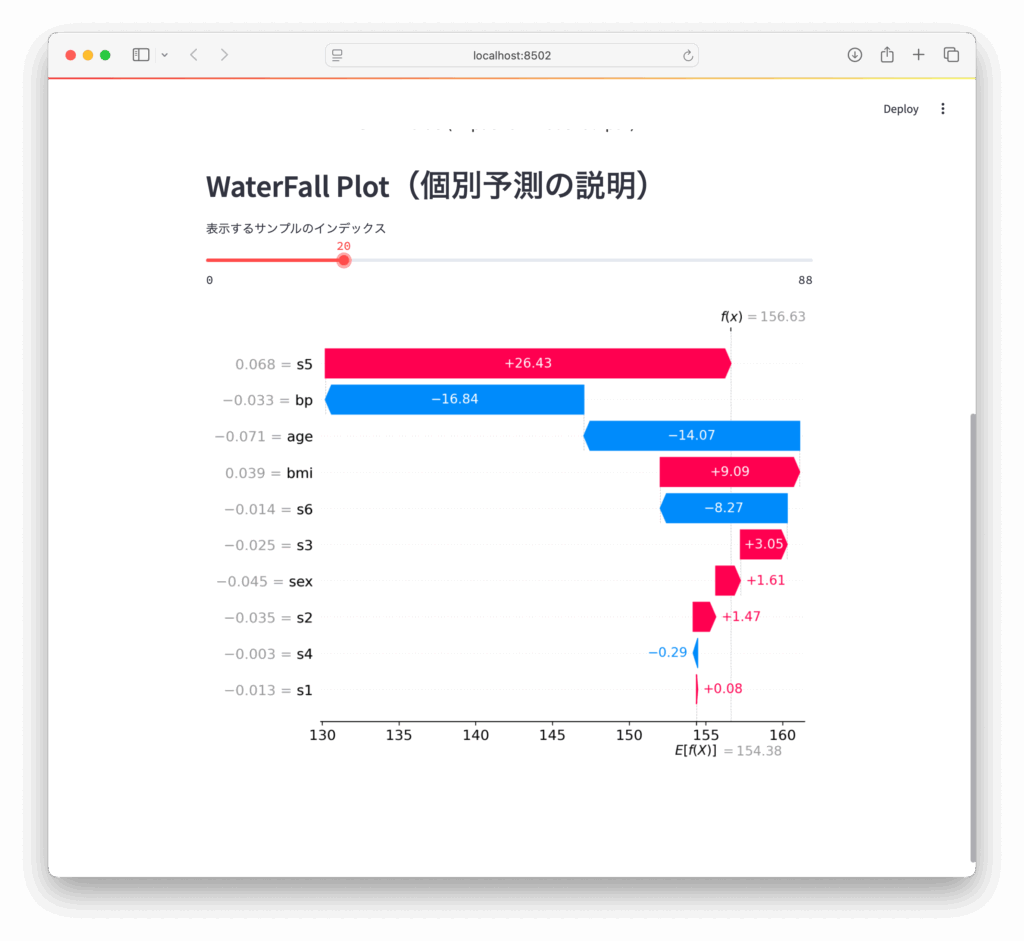
SHAPのWaterfall Plotの説明
SHAPのWaterfall Plot(ウォーターフォールプロット)は、機械学習モデルの予測値がどのように特徴量によって構築されていくかを視覚的に表現するグラフです。
基本的な構造
- 開始点: ベースライン値(平均予測値や期待値)から始まります
- 各特徴量の影響: 左から右へと各特徴量のSHAP値が積み上げられていきます
- 終点: すべての特徴量の寄与を足し合わせた最終的な予測値に到達します
読み方
- 右向きのバー: その特徴量が予測値を増加させる方向に寄与しています
- 左向きのバー: その特徴量が予測値を減少させる方向に寄与しています
- バーの高さ: 各特徴量がモデルの予測に与える影響の大きさを表しています
重要性
このプロットの利点は、個々の予測において各特徴量がどのように最終的な予測値に貢献しているかを明確に理解できることです。特に以下のような点で有用です:
- モデルの透明性の向上
- 予測結果の解釈性の向上
- 特定のケースでの特徴量の重要度の理解
- 予想外の予測値が出た際の原因究明
SHAPのWaterfall Plotは、モデルがある特定の予測を行った理由を「ストーリーとして語る」ことができるため、特に重要な意思決定に機械学習モデルを使用する場合に非常に価値があります。
6. アプリの起動と操作
以下のコマンドでアプリを起動できます:
streamlit run app.py画面が表示されたら、
- Summary Plotで全体の特徴量影響度を見る
- スライダーでインデックスを選んでForce Plotで個別の根拠を見る
という操作が可能です。
7. まとめ
SHAPは、機械学習モデルの「なぜその予測になったのか?」を明確にする強力な手法です。Streamlitと組み合わせることで、誰でも手軽に解釈性の高いインタフェースを構築できます。
本記事のアプローチを応用すれば、ビジネス現場や教育現場でのモデル説明や検証作業が格段にやりやすくなるでしょう。
参考リンク
最後に書籍のPRです。
24年11月に第3版が発行された「scikit-learn、Keras、TensorFlowによる実践機械学習 第3版」、Aurélien Géron 著。下田、牧、長尾訳。機械学習のトピックスについて手を動かしながら網羅的に学べる書籍です。ぜひ手に取ってみてください。

最後まで読んでいただきありがとうございます。