



こんにちは、JS2IIUです。
近年、大規模言語モデル(LLM)は様々な分野で急速に活用が広がっていますが、その運用・管理の難しさも同時に注目されています。単にモデルを動かすだけでなく、適切に更新し、監視し、ユーザーとの対話を調整し続けることが求められます。こうした効率的な運用を支えるのが「LLMOps」です。
本記事では、Pythonで気軽にウェブアプリを作成できるStreamlitを活用し、初めての方でも分かりやすくLLMOpsの基本から実践的なデプロイ・管理方法までを丁寧に解説します。実際のコード例も交えながら、手を動かしながら理解を深めていただける構成です。
個人で運用される方がいるのか、わかりませんが、今回もよろしくお願いします。
LLMOpsとは?基礎知識と重要性
LLMOpsの定義と役割
LLMOps(Large Language Model Operations)とは、LLMを運用・管理するためのプロセスやツール群を指します。単なるモデルの開発に留まらず、デプロイ、監視、メンテナンス、スケーリングといった運用全般を効率化することが求められます。
なぜLLMOpsが注目されているのか
- モデルサイズの増大:数十億〜数百億パラメータのモデルが主流となり、単純なデプロイや運用が困難に。
- 利用シーンの多様化:リアルタイム応答やバッチ処理、カスタマイズ対応など多様なニーズへの柔軟な対応が必要。
- 継続的なメンテナンス:新データによる更新やバージョン管理、異常検知が日常的に求められる。
従来のMLOpsとの違いと共通点
LLMOpsは従来の機械学習モデル運用(MLOps)から派生しているものの、以下の点で特徴的です。
| 項目 | MLOps | LLMOps |
|---|---|---|
| モデル規模 | 小〜中規模 | 超大規模(数十億〜) |
| 推論コスト | 軽〜中 | 高い |
| ユーザーインタラクション | 限定的なAPI利用 | インタラクティブなチャット等を含む |
| モデル更新頻度 | 比較的コントロール可能 | 頻繁かつ迅速な更新が求められる |
LLMOpsで重視される観点
| 観点 | 説明 |
|---|---|
| プロンプト管理 | どのプロンプトがどんな結果を出すかを追跡・バージョン管理 |
| LLM応答の評価 | LLMの出力の正確性・有用性・一貫性を評価 |
| 安全性とフォーマット保証 | 不適切な出力や不正な形式を制限 |
| リアルタイム監視 | LLMを使ったサービスのパフォーマンスや障害を即座に検知 |
| コスト最適化 | 高コストなLLM推論の呼び出し頻度や方法を最適化 |
LLMOpsで使われる代表的なツール一覧
| ツール名 | 特徴 | 主な機能 | 使い所 |
|---|---|---|---|
| LangChain | LLMアプリケーションの構築を支援するフレームワーク | – チェーン構築 – メモリ管理 – エージェント制御 – 複数LLMや外部ツールとの連携 | プロンプト設計やLLMを組み合わせた複雑なアプリケーション開発に |
| LlamaIndex (旧GPT Index) | 外部データとの統合に特化 | – データインデックス作成 – Retriever機能 – データ接続(SQL, PDF, Notionなど) | RAG(Retrieval Augmented Generation)で外部情報を参照させたいとき |
| Weights & Biases (W\&B) | 機械学習/LLMの実験管理ツール | – ロギング – モデル比較 – LLMパフォーマンスの可視化 | LLMの出力ログを分析し、バージョン管理やABテストに |
| PromptLayer | プロンプトのトラッキングと分析に特化 | – プロンプトログの記録 – 出力追跡 – OpenAI APIとの統合 | プロンプトの最適化、バージョン管理、履歴の可視化に |
| LLMonitor | LLMアプリケーションのモニタリング | – 入出力の可視化 – ユーザー操作の記録 – フィードバック収集 | 実アプリ運用時の品質改善、出力ログの監査に |
| Helicone | LLM APIコールの可視化とコスト最適化 | – OpenAI/Gemini APIのラップ – レスポンスログと遅延計測 – 利用量トラッキング | LLMのAPI利用を安価かつ効率的に管理したいとき |
| Guardrails AI | 出力の安全性を担保するための検証ツール | – 出力検証ルール定義 – JSON構造保証 – LLM応答の正確性評価 | LLMが常に正しい形式で出力する必要があるアプリ(例:チャットボット、API)に |
| Trulens | 出力の評価とフィードバックループ構築 | – LLM評価指標(正確性、一貫性など) – 人的・自動評価の統合 | RAGやチャットアプリでのLLM評価と改善に |
| MLflow | モデル管理の定番ツール、LLMOpsでも活用可 | – 実験管理 – モデル登録 – デプロイ支援 | LLMファインチューニング結果の記録、パフォーマンス追跡に |
| FastAPI / Streamlit / Gradio | LLMアプリのUI・API構築 | – LLM推論UIの作成 – Webアプリ公開 – API化 | LLMをプロトタイピングや社内外公開アプリにする際に |
使い方の具体例
- LangChain × LlamaIndex:自社のPDF資料を読み込ませて、質問応答ができるチャットボットを構築。
- W\&B × PromptLayer:同じプロンプトに対して複数モデルでABテストを実施し、どのモデルが最も良い応答をするか評価。
- Guardrails AI:ユーザーに返すJSON出力が常に正しい形式であるよう保証。
- Helicone:API呼び出し回数とコストを定量的に可視化し、利用量の最適化を図る。
Streamlitとは?特徴とLLMOpsでの活用メリット
Streamlitの簡単な紹介
Streamlitは、Pythonコードだけで手軽にWebアプリを構築できるフレームワークです。特にデータサイエンスや機械学習の結果を可視化・操作するツールとして人気があり、標準で多彩なUIコンポーネントを備えています。
手軽にUIが作れる点の強調
HTMLやJavaScriptの知識がなくても、st.text_input(), st.button(), st.write()などの関数を呼ぶだけで直感的な画面作成が可能です。
LLMOpsにおけるStreamlitの強み
- 実装コスト削減:複雑で面倒なフロントエンドを作らずに済むため、開発効率が大幅アップ。
- リアルタイムインタラクション:ユーザー入力を即座にトリガーにした処理が可能。
- 簡易ダッシュボード作成:モデルの状態やログを手軽に可視化できる。
既存のLLMOpsツールとの比較的な位置付け
例えば、KubeflowやMLflowのような複雑なMLOpsプラットフォームと比較して、Streamlitは「人間とLLMをつなぐ簡易かつ柔軟なUI構築」に特化しており、すぐに運用用の画面を作りたい時に非常に有効です。
実践:Streamlitを用いた大規模言語モデルのデプロイ方法
ここからは実際にPythonの開発環境を整え、Streamlitを使ってOpenAIのGPTモデルを活用する簡単な質問応答アプリを作ってみましょう。
ステップ1: 環境準備
- Pythonのインストール
Python 3.7以上。私は3.11を主に使っています。あえて古いバージョンを選ぶメリットはありません。
Python公式サイト - 必要なライブラリのインストール
ターミナル(コマンドプロンプト)で次のコマンドを実行します。
pip install streamlit openai- OpenAIのAPIキーを取得
OpenAI公式からAPIキーを生成します。
ステップ2: シンプルなStreamlitアプリ作成
以下のコードを app.py というファイルに保存してください。
import streamlit as st
import openai
import os
# 事前に環境変数などからAPIキーを設定しておく
openai.api_key = os.getenv("OPENAI_API_KEY")
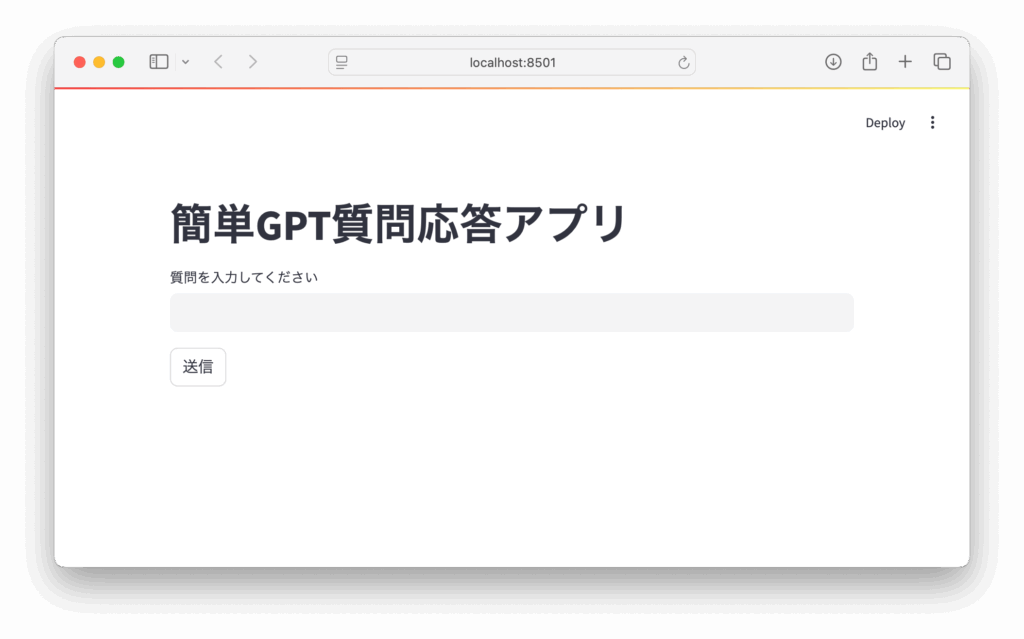
st.title("簡単GPT質問応答アプリ")
# ユーザーからの質問入力欄
user_input = st.text_input("質問を入力してください")
if st.button("送信"):
if not user_input.strip():
st.warning("質問を入力してください。")
else:
with st.spinner("回答を生成中..."):
try:
response = openai.Completion.create(
engine="text-davinci-003",
prompt=user_input,
max_tokens=150,
temperature=0.7,
)
answer = response.choices[0].text.strip()
st.markdown("**回答:**")
st.write(answer)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
ステップ3: アプリの起動
環境変数にAPIキーを設定し(例:Linux/macOSの場合)
export OPENAI_API_KEY='your_api_key_here'
streamlit run app.pyWindows PowerShellの場合は
setx OPENAI_API_KEY "your_api_key_here"
streamlit run app.pyブラウザが自動的に起動して、質問入力フォームが表示されます。質問を入力して「送信」を押すとGPTの応答が表示されます。
補足:Streamlitの主なコンポーネント
st.text_input():単一行テキスト入力欄st.button():クリック可能なボタンst.write()またはst.markdown():テキストやMarkdown形式での表記st.spinner():処理中の表示
モデル監視・管理におけるStreamlitの活用事例
運用ではモデルの状態を監視することが重要です。レスポンスタイムやエラー率、APIコール数などのメトリクスを見やすく可視化することで、問題の早期発見が可能になります。
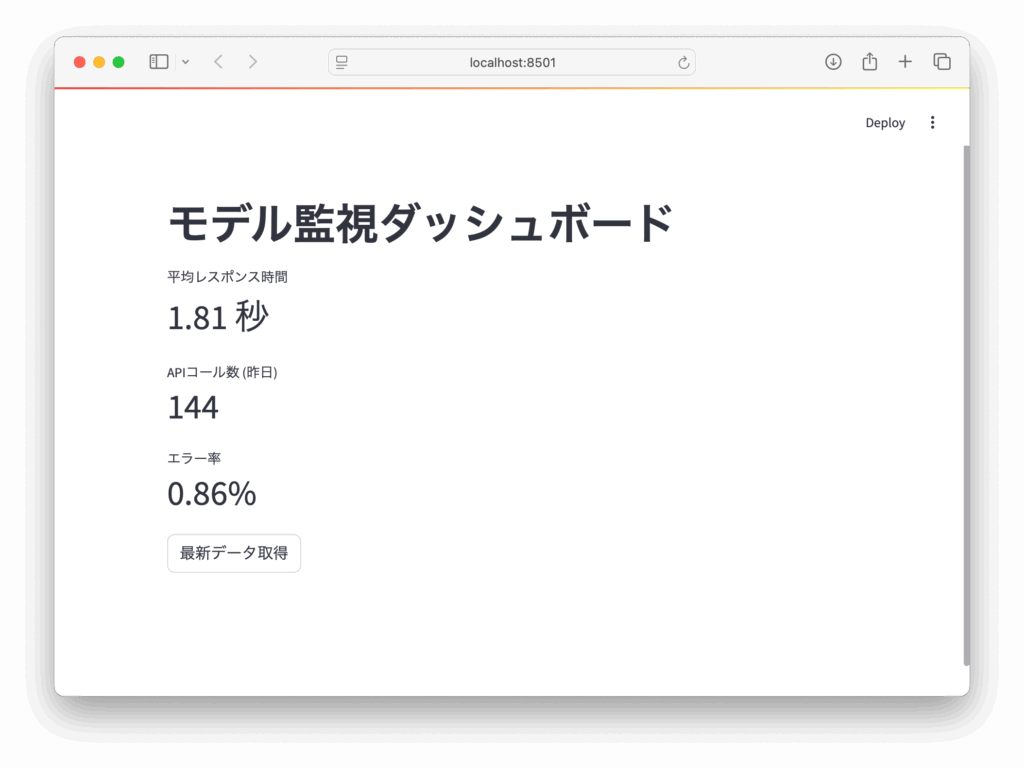
サンプル:簡単な監視ダッシュボード
下記は疑似的なメトリクスを表示する例です。
import streamlit as st
import time
import random
st.title("モデル監視ダッシュボード")
# 仮のメトリクス
response_time = random.uniform(0.1, 2.0) # 秒
api_calls = random.randint(50, 200)
error_rate = random.uniform(0, 0.05) # %
st.metric(label="平均レスポンス時間", value=f"{response_time:.2f} 秒")
st.metric(label="APIコール数 (昨日)", value=api_calls)
st.metric(label="エラー率", value=f"{error_rate:.2%}")
if st.button("最新データ取得"):
st.rerun()
モデルバージョン管理用UI例
model_versions = ["v1.0", "v1.1", "v2.0"]
selected_version = st.selectbox("モデルバージョンを選択してください", model_versions)
st.write(f"現在選択中のモデル: {selected_version}")このようにUIでモデルのバージョンを切り替えられると、複数モデルの運用管理がやりやすくなります。
LLMOpsにおけるユーザーインターフェース設計のポイント
使いやすさを高める基本原則
- シンプルで直感的な操作性
複雑な操作は避け、必要な機能だけを分かりやすく配置します。 - 障害時のわかりやすいメッセージ表示
エラーが起きてもユーザーが対応方法を理解できるように心がけます。 - 運用チームの役割やニーズを反映する
監視情報やログは担当者が利用しやすい形で提示しましょう。
フォーム入力の工夫
- 入力バリデーションの実装(例:空文字の検出)
- 入力補助(プレースホルダーや例示テキストの活用)
ロールごとのアクセスや機能の実装例(簡易説明)
例えば管理者用と一般ユーザー用の差別化には、ログイン機能(※外部認証連携も可能)を活用し、管理者はモデル更新や詳細ログ閲覧が可能、一般ユーザーは利用結果の閲覧だけにアクセス制限することが考えられます。
実践的ワークフロー:Streamlitと他ツール連携によるLLMOps自動化
LLMOpsでは、モデルの更新や監視、品質評価といった一連の運用タスクを自動化・可視化することが重要です。本節では、Streamlitを中心に据えたLLMOpsワークフローを構築するための具体的な方法を紹介します。CI/CD、可視化、監視、連携コードなど、実践的な要素を通して自動化の全体像を解説します。
CI/CDツールを用いたモデル更新トリガー
LLMを継続的に改善・運用する際、**CI/CD(継続的インテグレーション/継続的デリバリー)**ツールを活用することで、モデルの再学習から本番環境への自動反映までを自動化できます。
例えば、以下のようなGitHub Actionsを活用したパイプラインを構築可能です:
- モデル更新検知:新しいモデルのチェックインやバージョンタグ付けをトリガーに。
- 自動テスト:Pytestなどで推論結果の品質テストを実行。
- 品質が一定以上なら自動デプロイ:Dockerイメージのビルド → 本番環境へ自動反映。
# .github/workflows/deploy-model.yml(例)
on:
push:
tags:
- 'model-v*'
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout Repo
uses: actions/checkout@v2
- name: Run Model Evaluation
run: python evaluate_model.py
- name: Deploy to Production
if: success()
run: bash deploy.shこのようにすることで、人手を介さずにモデル更新の一貫した運用が実現します。
Streamlitでトリガー状況やログを可視化
Streamlitは、軽量かつ柔軟にフロントエンドを構築できるため、デプロイ状況やログを可視化するダッシュボードとして非常に適しています。
利用例:
- CI/CDの実行結果(成功・失敗)を表示
- デプロイ時刻やモデルバージョンの履歴を一覧化
- デプロイ中に発生したエラーの詳細ログ表示
これらは、GitHub ActionsのREST APIや、カスタムWeb API経由でログ情報を取得し、Streamlit上に表示する形で実装可能です。
import streamlit as st
import requests
# API経由でCIログを取得して表示
def show_deploy_log():
response = requests.get("https://your-api.com/logs/latest")
data = response.json()
st.write("最終デプロイ:", data["timestamp"])
st.code(data["log"], language="bash")
show_deploy_log()監視ツールとの連携例:Prometheus × Grafana
LLMアプリケーションの運用では、リクエスト数、応答時間、エラー率といったメトリクス監視が不可欠です。
具体的な構成例:
| ツール | 役割 |
|---|---|
| Prometheus | Streamlitアプリのメトリクスを定期取得し保存 |
| Grafana | Prometheusのデータを元にダッシュボードを構成 |
実装の流れ:
- Streamlitアプリ内にエンドポイントを設置
from flask import Flask, Response
from prometheus_client import Counter, generate_latest
REQUEST_COUNT = Counter('llm_requests_total', 'LLM APIへのリクエスト数')
@api.route("/metrics")
def metrics():
return Response(generate_latest(), mimetype="text/plain")- Prometheusでこのエンドポイントを定期取得(scrape)
scrape_configs:
- job_name: 'llm_app'
static_configs:
- targets: ['localhost:8501']- Grafanaで可視化
メトリクス(例:llm_requests_total)を使ってダッシュボードを構成し、アクセス状況やエラー発生タイミングをリアルタイムで確認可能に。
コードレベルでのツール連携ポイント例
Streamlitアプリが、GitHub Actionsや外部システムからのWebhook通知を受けて処理を開始する例です。これにより、CI/CDパイプラインとStreamlitダッシュボード間の連携が自動化されます。
import requests
# GitHub ActionsなどからWebhookで通知を受け取りStreamlit側で処理
def notify_deploy_trigger():
url = "https://your-streamlit-app/api/deploy_notify"
payload = {
"status": "started",
"timestamp": "2024-06-01T12:00:00Z",
"model_version": "v2.1.0"
}
response = requests.post(url, json=payload)
return response.status_codeStreamlit側では、FlaskやFastAPIなどを併用してWebhookを受け取り、ローカルDBやログに記録してダッシュボードに反映することができます。
運用業務効率化の効果
このようなLLMOpsの自動化により、以下のような実運用でのメリットが得られます:
| 効果 | 説明 |
|---|---|
| デプロイへの手動介入削減 | モデル更新時の人的作業を減らし、再現性のあるデプロイが可能に |
| 早期検知と対応 | モデルの挙動やエラーをリアルタイムで把握し、迅速なトラブル対応を実現 |
| チーム間での情報共有 | StreamlitやGrafanaによるダッシュボードで、非技術者を含めた運用状況の共有が円滑に |
参考リンク集
当ブログのStreamlit関連記事一覧です。こちらも参考にしていただけますと幸いです。ぜひご覧ください。



最後まで読んでいただきありがとうございます。
ご質問やフィードバックはコメント欄でお寄せください。