



こんにちは、JS2IIUです。
今回は、自動運転やロボット制御、さらには金融工学や時系列解析の分野で長年使われ続けている、少し「魔法」のようなアルゴリズム、「カルマン・フィルタ(Kalman Filter)」について解説します。
「カルマン・フィルタ」という名前を聞いたことはあっても、「数式に行列がたくさん出てきて挫折した」「結局何をしているのか直感的にわからない」という方は多いのではないでしょうか。
この記事では、難解な数学的な導出は一旦脇に置き、「Pythonコード」と「直感的なイメージ」を中心に、このアルゴリズムがどのようにしてノイズまみれのデータから「真の値」を見つけ出しているのかを体験していきます。今回もよろしくお願いします。
はじめに:カルマン・フィルタって何?
センサは嘘をつく
私たちは普段、プログラムで何かしらの値を扱う際、その値が「正しい」ことを前提にしがちです。しかし、現実世界のデータはそうはいきません。
例えば、ドローンの高度センサやスマホの加速度計、株価のティックデータなど、あらゆる観測値には必ずノイズ(誤差)が含まれています。
このノイズを含んだデータをそのままグラフにプロットすると、線はガタガタになり、その瞬間ごとの変化率(微分値)などは使い物にならなくなってしまいます。
予測と観測のいいとこ取り
ここでカルマン・フィルタの出番です。カルマン・フィルタを一言で表すと、「理論上の予測」と「実際の観測」を、それぞれの『信頼度』に応じて重み付けし、真の値を推定する技術です。
分かりやすい例え話をしましょう。
あなたは今、真っ暗なトンネルの中を歩いています。自分の位置を知る方法は2つあります。
- 予測(理論): 「さっきの一歩から1メートル歩いたはずだから、今はあそこにいるはずだ」と自分の感覚で推測する。
- 観測(センサ): 手元のGPSを見る。ただし、トンネル内なのでGPSの誤差は大きいかもしれない。
もし、「自分の歩測(予測)」に自信があり、「GPS(観測)」が信用できないなら、予測を重視すべきです。逆に、GPSの精度が非常に高いなら、自分の感覚よりGPSを信じるべきです。
カルマン・フィルタは、この「予測」と「観測」のバランス(重み付け)を、数学的に最適な形で逐次計算し続ける仕組みなのです。これにより、ガタガタの計測データから、滑らかな「真の動き」を抽出(ノイズ除去・平滑化)することが可能になります。
Step 1: 概念の理解(予測と更新のサイクル)
カルマン・フィルタの実装に入る前に、その動作原理である「2つのステップ」を理解しましょう。このアルゴリズムは、以下のループをひたすら繰り返します。
1. 予測ステップ (Time Update)
現在の状態から、物理法則やモデルに基づいて「次の瞬間の状態」を予測します。
- 例:「車が時速60kmで走っているから、1秒後は16.7m先に進んでいるはずだ」
- このとき、予測した値と同時に、「その予測がどれくらい不確かか(分散)」も更新します。時間が経つほど、予測の不確かさは増していきます。
2. 更新ステップ (Measurement Update)
実際にセンサから新しいデータ(観測値)が入ってきたら、それを使って予測を修正します。
- 例:「予測では16.7m先のはずだが、センサは17.0mを示している」
- ここで登場するのが、カルマン・フィルタの心臓部である「カルマンゲイン (Kalman Gain)」です。
魔法の数字:カルマンゲイン
カルマンゲインは、「予測」と「観測」のどちらをどれだけ信用するかを決める係数(0〜1の値)です。
- カルマンゲインが大きい場合: 「センサの値」を強く信用し、予測を大きく修正します。
- カルマンゲインが小さい場合: 「予測」を信用し、センサのノイズ(急な変動)を無視します。
このカルマンゲインが、データのばらつき具合(共分散)に応じて自動的に計算される点が、カルマン・フィルタの最も優れた点です。
Step 2: Pythonでの実装(1次元のシンプルな例)
それでは、Pythonで実際に動かしてみましょう。
いきなり多次元の行列演算を行うと複雑になるため、ここでは最もシンプルな「1次元の値を推定するカルマン・フィルタ」を作成します。
「一定の電圧を出力する電源を、ノイズの乗る電圧計で測り続ける」ようなシチュエーションを想像してください。
必要なライブラリのインポート
数値計算にはNumPy、グラフ描画にはMatplotlibを使用します。
import numpy as np
import matplotlib.pyplot as plt
# 乱数のシードを固定(再現性のため)
np.random.seed(42)カルマン・フィルタ・クラスの実装
以下が、1次元カルマン・フィルタのクラス実装です。数式をコードに落とし込んでいますが、コメントを読むだけで何をしているか分かるはずです。
class KalmanFilter1D:
def __init__(self, initial_state, initial_covariance, process_noise, measurement_noise):
"""
初期化メソッド
:param initial_state: 初期推定値 (x)
:param initial_covariance: 初期の不確かさ (P)
:param process_noise: プロセスノイズの分散 (Q) - システムのふらつき
:param measurement_noise: 観測ノイズの分散 (R) - センサの誤差
"""
self.x = initial_state # 状態推定値
self.P = initial_covariance # 共分散(推定の不確かさ)
self.Q = process_noise # プロセスノイズ (Q)
self.R = measurement_noise # 観測ノイズ (R)
def predict(self):
"""
予測ステップ (Time Update)
次の状態を予測する。今回は「値は変化しない」という単純なモデルを仮定。
"""
# 状態方程式: x(t+1) = x(t)
# 今回は静止している値を想定しているため、xはそのまま。
# もし移動している物体なら、ここで速度を加算する等の処理が入る。
# 誤差共分散の予測: P = P + Q
# 時間が経過すると、不確かさ(P)はプロセスノイズ(Q)の分だけ増える
self.P = self.P + self.Q
return self.x
def update(self, measurement):
"""
更新ステップ (Measurement Update)
観測値を用いて、予測値を修正する。
:param measurement: センサからの観測値 (z)
"""
# カルマンゲインの計算: K = P / (P + R)
# 不確かさ(P)が大きく、ノイズ(R)が小さいほど、Kは1に近づく(観測を信じる)
# 逆にノイズ(R)が大きいと、Kは0に近づく(予測を信じる)
K = self.P / (self.P + self.R)
# 推定値の更新: x = x + K * (z - x)
# (z - x) は「観測」と「予測」のズレ(残差)。
# それにKを掛けた分だけ修正する。
self.x = self.x + K * (measurement - self.x)
# 誤差共分散の更新: P = (1 - K) * P
# 観測データを取り込んだので、不確かさ(P)は減少する
self.P = (1 - K) * self.P
return self.xコード解説
このクラスには、predict(予測)とupdate(更新)という2つのメソッドがあります。
- 状態空間モデル (State Space Model): ここでは非常に単純化し、「値は変化しない\( x_{t+1} = x_t \)」というモデルを採用しています。
- 共分散行列 (Covariance Matrix) \(P\): 1次元なので単なるスカラー(分散)ですが、これが「現在の推定値に対する自信のなさ」を表します。更新ステップで観測値を取り込むたびに、\(P\)の値が小さくなり、推定への「自信」が深まっていく様子が数式から読み取れます。
Step 3: 実験と可視化
作成したクラスを使って、ノイズ除去のシミュレーションを行いましょう。
シミュレーションデータの作成
真の値は「10.0」で一定とします。そこに正規分布(ガウス分布)に従うノイズを加えて、擬似的な「センサの観測値」を作ります。
# パラメータ設定
n_steps = 50 # シミュレーションのステップ数
true_value = 10.0 # 真の値(一定)
measurement_noise_std = 2.0 # 観測ノイズの標準偏差 (これぐらいブレる)
# 真の値の配列
ground_truth = np.full(n_steps, true_value)
# 観測値の生成(真の値 + ガウスノイズ)
measurements = ground_truth + np.random.normal(0, measurement_noise_std, n_steps)
# カルマン・フィルタのインスタンス化
# Q (プロセスノイズ) は小さく設定(値はほぼ変化しないと仮定)
# R (観測ノイズ) は大きめに設定(センサは信用できないと仮定)
kf = KalmanFilter1D(initial_state=0.0, initial_covariance=1.0, process_noise=0.001, measurement_noise=measurement_noise_std**2)
# 推定の実行
estimates = []
for z in measurements:
kf.predict() # 1. 予測
est = kf.update(z) # 2. 更新
estimates.append(est)結果のプロット
Matplotlibを使って、「真の値」「観測値(ノイズあり)」「カルマン・フィルタの推定値」を重ねて表示します。
plt.figure(figsize=(10, 6))
# 真の値
plt.plot(ground_truth, label='Ground Truth (10.0)', color='green', linestyle='dashed', linewidth=2)
# 観測値(ノイズ)
plt.plot(measurements, label='Measurements (Noisy)', color='lightgray', marker='o', linestyle='none')
# 推定値
plt.plot(estimates, label='Kalman Filter Estimate', color='blue', linewidth=2)
plt.title('Kalman Filter Simulation (1D Constant Model)')
plt.xlabel('Time Step')
plt.ylabel('Value')
plt.legend()
plt.grid(True)
plt.show()
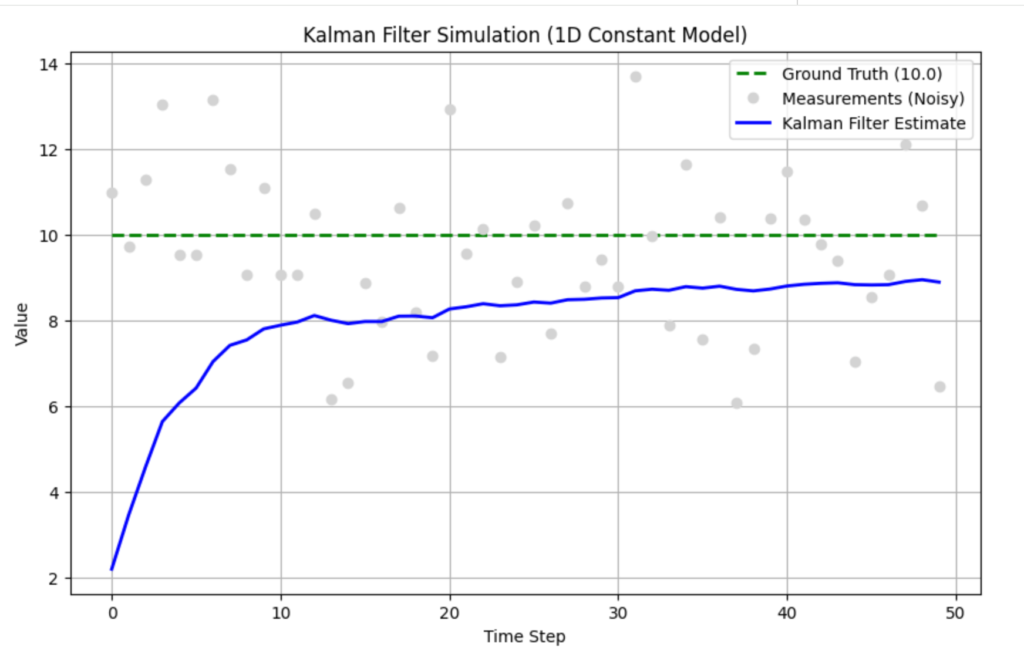
実行結果の解釈
このコードを実行すると、灰色の点は上下に大きくバラついている(ノイズ)にもかかわらず、青色の線(カルマン・フィルタ)は滑らかに緑色の点線(真の値)に収束していく様子が確認できるはずです。
最初は初期値(0.0)からスタートしているため真の値とのズレがありますが、ステップが進むにつれて「観測データ」を取り込みながら修正し、かつ「ノイズ」には過剰反応しないという、絶妙な動きをしています。これがカルマン・フィルタの効果です。
Step 4: パラメータをいじってみよう
カルマン・フィルタを使いこなす鍵は、\(Q\)(プロセスノイズ)と\(R\)(観測ノイズ)の設定にあります。これらは「モデル(予測)の不確かさ」と「センサの不確かさ」を表すパラメータです。
コード内の値を変更して、挙動がどう変わるか試してみましょう。
ケースA:センサを全く信用しない ($R$ を非常に大きくする)
# Rを極端に大きく(例: 1000.0)
kf = KalmanFilter1D(..., measurement_noise=1000.0)結果: グラフの線は非常に滑らかになりますが、真の値(10.0)に近づくのに長い時間がかかります。新しい情報(観測)をなかなか受け入れなくなるためです。
ケースB:センサを過信してモデルを信用しない ($Q$ を大きく、$R$ を小さく)
# Qを大きく(例: 1.0)、Rを小さく(例: 0.01)
kf = KalmanFilter1D(..., process_noise=1.0, measurement_noise=0.01)結果: グラフは観測値(灰色の点)をほぼそのままなぞるようになり、ギザギザになります。これはフィルタリングの効果がほとんどなくなっている状態です。「値は急には変化しないはずだ」という予測の制約を緩めてしまったためです。
この \(Q\) と \(R\) のバランスを調整することを「チューニング」と呼び、実務では非常に重要な工程になります。
まとめと応用
今回は、最も基礎的な1次元の例を通して、カルマン・フィルタの「予測」と「更新」のサイクルをPythonで実装・体験しました。
今回のポイント
- カルマン・フィルタは、予測と観測の信頼度(分散)に基づいて、最適な値を推定する。
- カルマンゲインが、そのバランスを自動調整する「つまみ」の役割を果たす。
- Pythonであれば、複雑な数式を意識せずとも数行のコードで実装できる。
応用への入り口
今回扱ったのは「値が一定」という静的なモデルでしたが、現実世界では物体は動きます。
位置と速度を同時に推定する場合、変数はベクトル(行列)になり、「行列演算」が必要になります。ここでNumPyの行列機能が本領を発揮します。
さらに、現実の物理現象(ロボットの関節運動など)は単純な比例関係(線形)ではないことが多いです。そのような場合には、今回学んだ基礎を拡張した「拡張カルマン・フィルタ (EKF)」や「アンサンブル・カルマン・フィルタ」などが使われます。
センサフュージョンや時系列解析の世界は奥が深いですが、すべての基礎はこの「予測して、測って、修正する」というサイクルにあります。ぜひ、今回のコードをベースに、パラメータを変えたりモデルを複雑にしたりして、その挙動を楽しんでみてください。
最後まで読んでいただきありがとうございます。