



こんにちは、JS2IIUです。
Streamlitで「数分〜数時間かかる重い処理」を安全かつ安定して実行したい——そんな悩みを持つ開発者は多いのではないでしょうか。Streamlitは手軽にWebアプリを作れる一方、長時間処理には設計上の壁が立ちはだかります。本記事では、なぜStreamlitで長時間処理が難しいのかを解説し、外部サービスを使わずに「止まらない」アプリを実現するための現実的な設計パターンと実装例を紹介します。今回もよろしくお願いします。
1. はじめに:なぜ Streamlit で「長時間処理」は難しいのか
Streamlit は「Python スクリプトを書くだけで Web アプリが作れる」という強力な特徴を持っています。
一方で、「数分〜数時間かかる処理を実行したい」と考えた瞬間、多くの開発者が壁にぶつかります。
- ボタンを押したら途中で処理が止まる
- ブラウザを更新したら最初からやり直し
- サーバ負荷が高まると不安定になる
これらはバグではなく、Streamlit の設計思想そのものに起因する問題です。
本記事では、「Streamlit 長時間処理」「Streamlit バックグラウンド」「Streamlit 非同期」といった検索キーワードの背景にある課題を整理し、外部サービスを使わずに実現できる現実的な設計パターンを、動作するコード付きで解説します。
2. Streamlit の再実行モデルを正しく理解する
Streamlit の動作原理を理解するうえで最も重要なのが、再実行モデル(rerun model)です。
スクリプト全体の自動再実行
Streamlit アプリは、ユーザーによるインタラクション(例:ボタンのクリック、セレクトボックスの選択変更、ページ切り替えなど)が発生するたびに、Python スクリプト全体が最初から末尾まで自動的に再実行される仕組みになっています。
この挙動は、Jupyter Notebook のように「一部のセルだけを個別に実行する」モデルとは本質的に異なり、アプリの状態管理や長時間処理の設計に大きな影響を与えます。
長時間処理と再実行モデルの衝突
たとえば、10分かかる重い処理を if st.button("実行"): のように直接記述した場合、
ユーザー操作やページ遷移などで再実行が発生すると、
- 進行中の処理が途中で強制的に中断される
- 同じ重い処理が何度も繰り返し実行されてしまう
- セッションごとに状態が分断され、処理の一貫性が保てない
といった問題が生じます。
このように、UI操作(イベント)と重い計算処理が同じ実行コンテキストで密結合していることが、Streamlit で長時間処理を扱う際の最大の技術的課題となります。
3. よくある失敗パターンとその限界
パターン1:ボタン内で直接ループ処理を実行
if st.button("実行"):
for i in range(100):
heavy_task()この実装は一見シンプルで直感的ですが、Streamlit の再実行モデルの影響を強く受けます。ユーザーがボタンを押した直後に他のUI操作やページ遷移が発生すると、スクリプト全体が再実行され、進行中のループ処理が途中で中断されてしまいます。また、同じ処理が複数回重複して走るリスクもあり、安定した長時間処理には不向きです。
パターン2:st.session_state に長時間処理の状態を保持
st.session_state はユーザーごとの一時的な状態管理には便利ですが、長時間にわたる計算処理や進捗情報そのものを直接保持する用途には適していません。セッションの切断や再接続、アプリの再起動などが発生すると、session_state の内容が失われる可能性があり、処理の継続性や信頼性が担保できません。
これらの方法は、数秒程度の短い処理であれば問題なく動作しますが、数十分〜数時間に及ぶような重い処理では、設計上の限界が顕在化します。
4. 解決アプローチ全体像:長時間処理アーキテクチャ
ここで、従来の「UIと処理が密結合した設計」から脱却し、アーキテクチャの根本的な見直しが必要となります。
基本方針:UI層と計算処理層の完全分離
長時間処理を安定して扱うためには、以下の3層構造を明確に分離することが重要です。

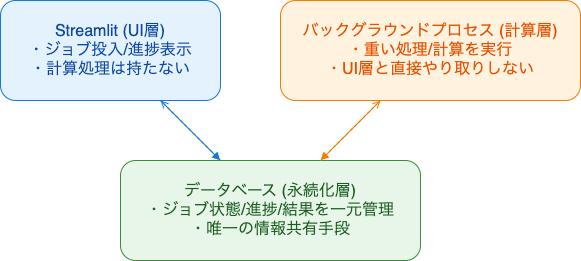
- Streamlit(UI層):ジョブの投入(登録)や進捗・結果の表示のみを担当し、重い計算処理は一切持たない
- バックグラウンドプロセス(計算層):実際の重い処理や計算を独立したプロセスで実行し、UI層とは直接やり取りしない
- データベース(永続化層):ジョブの状態や進捗、結果などを一元的に管理し、UI層と計算層の唯一の情報共有手段とする
このような構成を採用することで、Streamlit の再実行モデルによる影響(スクリプトの再実行やセッションの切断など)を完全に排除し、UIの操作と重い処理の実行を安全かつ堅牢に分離できます。結果として、アプリ全体の信頼性と拡張性が大きく向上します。
5. 実装①:SQLite を使ったシンプルなジョブ管理
まず、ジョブの状態や進捗を永続的に管理するためのデータベースとして、SQLite を利用します。SQLite はファイルベースで動作し、外部サーバや複雑なセットアップが不要なため、個人開発や小規模なアプリケーションに最適です。
ジョブ管理用のテーブル(例:jobs)を作成し、各ジョブの状態や進捗率などを記録できるようにします。以下はその初期化処理の例です。
import sqlite3
def init_db():
conn = sqlite3.connect("jobs.db")
cur = conn.cursor()
cur.execute("""
CREATE TABLE IF NOT EXISTS jobs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
status TEXT,
progress INTEGER
)
""")
conn.commit()
conn.close()ジョブ状態の設計と管理
ジョブの状態(status)は、たとえば以下のような値で管理します。
pending:未実行(キューに登録されたがまだ処理されていない)running:実行中(バックグラウンドで処理が進行中)done:完了(処理が正常に終了し、結果が保存された)
ここで最も重要なのは、「処理の状態や進捗をPythonのメモリ上の変数やオブジェクトで管理するのではなく、必ずDB(永続化層)に保存する」ことです。これにより、Streamlit の再実行やセッション切断が発生しても、ジョブの状態が失われず、アプリ全体の堅牢性が大きく向上します。
6. 実装②:バックグラウンド処理(マルチプロセス)
次に、実際の長時間処理(重い計算やバッチ処理など)を、Streamlit のメインプロセスとは独立したバックグラウンドプロセスで実行する仕組みを構築します。これにより、UI の応答性を維持しつつ、計算処理の中断や競合を防ぐことができます。
Python 標準ライブラリの multiprocessing モジュールを利用することで、簡単にプロセス分離が可能です。以下は、ジョブIDを受け取り、その進捗をDBに記録しながら重い処理を実行する例です。
import time
import sqlite3
from multiprocessing import Process
import torch
def long_task(job_id: int):
conn = sqlite3.connect("jobs.db")
cur = conn.cursor()
cur.execute("UPDATE jobs SET status='running' WHERE id=?", (job_id,))
conn.commit()
# PyTorch を使った疑似的な重い処理
for i in range(10):
x = torch.randn(1000, 1000)
_ = torch.matmul(x, x)
time.sleep(2)
cur.execute(
"UPDATE jobs SET progress=? WHERE id=?",
(i * 10, job_id)
)
conn.commit()
cur.execute("UPDATE jobs SET status='done', progress=100 WHERE id=?", (job_id,))
conn.commit()
conn.close()コード詳細解説(ステップバイステップ)
- 必要なライブラリのインポート
time:処理の遅延(sleep)に使用。sqlite3:SQLiteデータベースへの接続・操作に使用。multiprocessing.Process:バックグラウンドで別プロセスを立ち上げるために使用。torch:重い計算処理の例としてPyTorchを利用。
- long_task関数の定義
job_id(int型)を引数に取り、指定されたジョブの進捗・状態をDBに記録しながら重い処理を実行する。
- DB接続とカーソル作成
sqlite3.connect("jobs.db")でDBファイルに接続。conn.cursor()でSQL実行用のカーソルを取得。
- ジョブ状態を「実行中(running)」に更新
cur.execute("UPDATE jobs SET status='running' WHERE id=?", (job_id,))で該当ジョブの状態を更新。conn.commit()で変更をDBに反映。
- 重い処理のメインループ
- 10回ループし、各イテレーションで以下を実施:
torch.randn(1000, 1000)で1000×1000の乱数行列を生成。torch.matmul(x, x)で行列積を計算(CPU負荷の高い処理例)。time.sleep(2)で2秒間スリープ(進捗の可視化用)。cur.execute("UPDATE jobs SET progress=? WHERE id=?", (i * 10, job_id))で進捗(10%刻み)をDBに記録。conn.commit()で進捗更新を反映。
- 10回ループし、各イテレーションで以下を実施:
- ジョブ状態を「完了(done)」に更新
- ループ終了後、
cur.execute("UPDATE jobs SET status='done', progress=100 WHERE id=?", (job_id,))で状態と進捗を最終更新。 conn.commit()でDBに反映。
- ループ終了後、
- DB接続のクローズ
conn.close()でリソースを解放。
なぜマルチスレッドではなくマルチプロセスか
長時間・高負荷な計算処理を安全かつ効率的に実行するためには、マルチスレッドではなくマルチプロセス方式が推奨されます。主な理由は以下の通りです。
- Python の GIL(Global Interpreter Lock)の制約を受けず、CPUバウンドな処理でも並列実行が可能
- Streamlit のメインプロセスと完全に分離されるため、UI 側の安定性や応答性を損なわない
- PyTorch などの数値計算ライブラリはプロセス分離との相性が良く、リソース競合やメモリリークのリスクを低減できる
このように、プロセス分離によるバックグラウンド実行は、Streamlit アプリにおける長時間処理の信頼性・拡張性を大きく高める重要な設計ポイントです。
7. 実装③:Streamlit 側の UI 設計(マルチページ)
Streamlit 側では、ユーザーがジョブを投入(登録)するページと、ジョブの進捗や状態を監視するページを分離して設計します。これにより、UIの操作とバックグラウンド処理の実行が明確に分離され、アプリの保守性・拡張性が向上します。
ジョブ投入ページ
ジョブ投入ページでは、ユーザーが「ジョブ開始」ボタンを押すと、以下の処理が順に実行されます。
- SQLiteデータベースに新しいジョブ(
status='pending',progress=0)を登録。 - 登録直後に発行される
job_idを取得。 - データベース接続をクローズ。
multiprocessing.Processを使って、long_task(job_id)をバックグラウンドで非同期実行。- ユーザーに「ジョブ開始」を通知。
if st.button("ジョブ開始"):
conn = sqlite3.connect("jobs.db")
cur = conn.cursor()
cur.execute("INSERT INTO jobs (status, progress) VALUES ('pending', 0)")
job_id = cur.lastrowid
conn.commit()
conn.close()
p = Process(target=long_task, args=(job_id,))
p.start()
st.success(f"ジョブ {job_id} を開始しました")この設計により、UIの応答性を損なうことなく、重い処理を安全にバックグラウンドで実行できます。
ジョブ監視ページ
ジョブ監視ページでは、データベースから全ジョブの状態・進捗を取得し、st.dataframe で可視化します。
conn = sqlite3.connect("jobs.db")
df = pd.read_sql("SELECT * FROM jobs", conn)
conn.close()
st.dataframe(df)この方式では、Streamlit の再実行やセッション切断が発生しても、ジョブの状態はDBに永続化されているため、UI側で安全に進捗を監視・再表示できます。
Streamlitコード全体
上記のコードを一つにまとめます。
import streamlit as st
import sqlite3
from multiprocessing import Process
import time
import pandas as pd
import torch
import os
DB_PATH = "jobs.db"
def init_db():
conn = sqlite3.connect(DB_PATH)
cur = conn.cursor()
cur.execute("""
CREATE TABLE IF NOT EXISTS jobs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
status TEXT,
progress INTEGER
)
""")
conn.commit()
conn.close()
def long_task(job_id: int):
conn = sqlite3.connect(DB_PATH)
cur = conn.cursor()
cur.execute("UPDATE jobs SET status='running' WHERE id=?", (job_id,))
conn.commit()
for i in range(10):
x = torch.randn(1000, 1000)
_ = torch.matmul(x, x)
time.sleep(2)
cur.execute(
"UPDATE jobs SET progress=? WHERE id=?",
(i * 10, job_id)
)
conn.commit()
cur.execute("UPDATE jobs SET status='done', progress=100 WHERE id=?", (job_id,))
conn.commit()
conn.close()
# --- Streamlit UI ---
st.set_page_config(page_title="Streamlit 長時間処理サンプル", layout="centered")
st.title("Streamlit 長時間処理サンプル")
# DB初期化
if not os.path.exists(DB_PATH):
init_db()
# ページ切り替え
page = st.sidebar.selectbox("ページ選択", ["ジョブ投入", "ジョブ監視"])
if page == "ジョブ投入":
st.header("ジョブ投入ページ")
if st.button("ジョブ開始"):
conn = sqlite3.connect(DB_PATH)
cur = conn.cursor()
cur.execute("INSERT INTO jobs (status, progress) VALUES ('pending', 0)")
job_id = cur.lastrowid
conn.commit()
conn.close()
p = Process(target=long_task, args=(job_id,))
p.start()
st.success(f"ジョブ {job_id} を開始しました")
elif page == "ジョブ監視":
st.header("ジョブ監視ページ")
conn = sqlite3.connect(DB_PATH)
df = pd.read_sql("SELECT * FROM jobs", conn)
conn.close()
st.dataframe(df)
8. 応用:より高度な設計に拡張するには
より大規模・高機能なジョブ管理や分散処理が必要な場合、設計の拡張が検討されますが、まずは本記事で紹介した「SQLite + プロセス分離」構成で多くのユースケースに十分対応できます。
Pythonにおける非同期処理方式の比較
- asyncio(非同期I/O):ファイルやネットワーク通信などI/Oバウンドな処理に最適。イベントループ上で複数のI/O待ちタスクを効率的に切り替えることができるが、CPUバウンドな重い計算処理には不向き。
- マルチプロセス(multiprocessing):CPUバウンドな計算処理や長時間バッチ処理に最適。各プロセスが独立して動作するため、GILの制約を受けずに並列実行が可能。
Celery / Redis など外部分散ジョブキューを使わない理由
- CeleryやRedisなどの分散ジョブキュー/メッセージブローカーは、ジョブのスケーラビリティや耐障害性が求められる大規模システムには有効だが、小〜中規模のStreamlitアプリでは導入・運用コストが高く、オーバースペックになりやすい。
- デプロイや保守の複雑さが増すため、まずはシンプルな「SQLite + プロセス分離」構成で十分なことが多い。
このように、要件に応じて段階的に設計を拡張していくのが現実的です。まずは 「SQLite + プロセス分離」 で堅牢な基盤を作り、必要に応じて外部サービスや分散処理基盤の導入を検討しましょう。
9. まとめ:Streamlit で「止まらない」アプリを作るために
Streamlit で長時間処理を安定して実行するための本質的な課題は、単なる「テクニック」や「小手先の回避策」ではなく、アプリケーション全体の設計思想そのものにあります。
特に、以下の3つの設計原則を徹底することが重要です。
- 再実行モデルの正しい理解:Streamlit のスクリプトはユーザー操作のたびに全体が再実行されるため、状態や処理の持ち方を根本から見直す必要がある。
- UI層と処理層の明確な分離:UI(Streamlit)はジョブの登録・進捗表示のみを担当し、重い計算処理は必ずバックグラウンドで独立して実行する。
- 状態の永続化(外部化):ジョブの状態や進捗は、Pythonのメモリやセッションではなく、必ず外部データベース等に保存し、再実行やセッション切断に強い構成とする。
この3点を守るだけで、「Streamlit は長時間処理に弱い」という従来の評価は大きく覆り、堅牢で拡張性の高いアプリケーションを構築できるようになります。
ぜひ本記事の設計指針を参考に、止まらず動き続ける Streamlit アプリを実現してください。
最後まで読んでいただきありがとうございました。
当ブログでStreamlit関連記事を紹介してきましたが、今回の記事でちょうど200本目となりました。過去の記事はこちらのリンク先から覗いてみて下さい。これからもよろしくお願いします。


