
こんにちはJS2IIUです。
連載「StreamlitとRAGで作る:実用的なAIチャットボット開発ガイド」の第4回目の記事です。
前回は、PDFなどのドキュメントを読み込み、AIが食べやすい一口サイズ(チャンク)に分割するところまでを解説しました。これで手元には大量のテキストデータの断片があります。
しかし、このままではまだAIは知識を活用できません。
例えば、あなたが「会社の休暇規定」について知りたいとき、数千個あるテキストの断片から、どうやって関連する部分だけを瞬時に見つけ出せばいいのでしょうか? 全文検索(grep)では、「休み」と「休暇」のような言葉の揺らぎに対応できません。
そこで登場するのが今回の主役、「エンベディング(Embedding)」と「Vector Store」です。
これは、テキストデータを「意味の空間」に配置し、高速に検索できるようにする技術です。今回は、これらの概念を直感的に理解し、実際にPythonコードでローカル環境に検索エンジンを構築してみましょう。今回もよろしくお願いします。
1. はじめに:言葉を「数字」に変える魔法
前回作成したテキストチャンクは、あくまで「文字の羅列」です。コンピュータはそのままでは「意味」を理解できません。
もしあなたが「PCが動かない」と検索したとき、記事の中に「パソコンが起動しない」と書いてあったらどうでしょう?
単語が違うので、単純なキーワード検索ではヒットしません。しかし、人間なら同じ意味だと分かります。
RAGシステムでは、この「意味の近さ」を計算するために、テキストをベクトル(数値の列)に変換します。
そして、そのベクトルを効率よく保存・検索するために特化したデータベースが Vector Store です。
今回は、この「検索の頭脳」部分を構築します。
2. 技術解説:エンベディング(Embedding)とは?
エンベディングとは、一言で言えば「言葉の意味を、多次元空間上の座標に変換すること」です。
イメージしてください。
巨大な空間の中に、世の中のあらゆる言葉が浮かんでいます。
「リンゴ」という言葉の近くには「ミカン」や「バナナ」があり、「ロケット」という言葉はずっと遠くの場所にあります。
「猫」という言葉の近くには「犬」がいますが、少し離れたところには「ペットフード」もあります。
このように、意味が似ているもの同士が近く(距離が短く)なるように数値を割り振る技術がエンベディングです。
エンべディングの技術的な説明
エンベディングは、自然言語の単語や文、段落などを「ベクトル(数値の配列)」に変換する技術です。これにより、コンピュータは言語の意味的な類似性や関係性を数値的に扱えるようになります。
主な技術ポイント:
- 高次元ベクトル表現: 例えばOpenAIの
text-embedding-3-smallでは1536次元、SentenceTransformersでは384〜768次元など、数百〜数千次元のベクトルで表現されます。 - 意味的距離の計算: 2つのテキスト間の「意味の近さ」は、ユークリッド距離やコサイン類似度(cosine similarity)などの数式で計算できます。コサイン類似度が高いほど、意味が近いと判断されます。
- 学習済みモデル: エンベディングモデルは大量のテキストコーパスで事前学習されており、単語や文の意味的な関係性を自動的に捉えます。
- 用途: 類似検索(Semantic Search)、クラスタリング、分類、推薦システム、異常検知など、幅広いAIアプリケーションで利用されます。
例:コサイン類似度の計算式
$$
\cos(\theta) = \frac{\vec{A} \cdot \vec{B}}{|\vec{A}| |\vec{B}|}
$$
ここで\(\vec{A}\), \(\vec{B}\)は2つのエンベディングベクトルです。
なぜ有効か?
従来の「単語の一致」ではなく、「意味の近さ」で検索や分類ができるため、言い換えや表記揺れにも強く、より人間に近い情報検索や推論が可能になります。
どのモデルを使うべきか?
- OpenAI Embeddings (
text-embedding-3-small等):- メリット: 非常に高性能で、多言語に対応。APIを呼ぶだけで使える。
- デメリット: 有料(非常に安価ですが)。データが外部に送信される。
- Hugging Face (PyTorchベースのローカルモデル):
- メリット: 無料。ローカルで完結するためセキュリティが高い。
- デメリット: マシンスペック(GPU等)が必要な場合がある。日本語特化モデルの選定が必要。
本連載では、構築の容易さと性能の安定性から OpenAI Embeddings をメインに使用しますが、コードの一部を書き換えるだけでローカルモデル(PyTorch + HuggingFace)に切り替えることも可能です。
| 特性 \ モデル | OpenAI: text-embedding-3-small | OpenAI: text-embedding-3-large | Anthropic: claude-embeddings-1 | Cohere: embed-english-v2.0 | SentenceTransformers: all-MiniLM-L6-v2 (HF) |
|---|---|---|---|---|---|
| 主な特徴 | 最新の軽量高品質埋め込み(低コスト) | 高次元で表現力強め(より高精度) | LLMベンダー提供の汎用埋め込み | 英語向けに最適化、低レイテンシ | 軽量で高速、コミュニティ実装の定番 |
| 言語対応 | 多言語対応(日本語含む) | 多言語対応(日本語含む) | 主に英語だが多言語対応あり | 英語最適、他言語は限定的 | 多言語対応(英語が最良) |
| 精度 / 表現力 | 高め(コスト効率良) | 非常に高い(微妙な意味差も把握) | 高い(Anthropic最適化) | 高い(英語文に秀でる) | 中〜高(軽量モデルとして十分) |
| レイテンシ & コスト | 低〜中 / 低コスト | 中〜高 / 高コスト | 中 / 中〜高(API課金) | 低〜中 / 中程度 | 低 / 無料(ローカル) |
| ローカル実行可否 | ×(API) | ×(API) | ×(API) | ×(API) | ◯(ローカル/オフライン) |
| 長所 | コスト効率が良く安定 | 最良クラスの意味表現 | Claudeエコシステムとの親和性 | 英語での高性能・低レイテンシ | オフライン・低遅延・コストゼロ |
| 短所 | 極微な表現差では大型モデルに劣る | コストとレイテンシが高め | ベンダーロック、コスト発生 | 英語外では精度低下しやすい | 大規模データや微妙な意味差で限界 |
| 使い所(推奨ケース) | 多言語のプロダクトでコスト抑えたいとき | 高精度検索や微妙な類似性が重要な用途 | Anthropic製品チェーンで統合する場合 | 英語ドキュメント中心の検索・分類 | ローカル運用・プライバシー重視・プロトタイピング |
簡潔な選び方:
- コスト重視かつ多言語 →
text-embedding-3-small - 最高精度が必要 →
text-embedding-3-large - Anthropic環境で統合 →
claude-embeddings-1 - 英語中心で低レイテンシ →
Cohere embed-english-v2.0 - ローカル/プライバシー重視 →
SentenceTransformers (all-MiniLM-L6-v2)
3. 技術解説:Vector Store(ベクトルデータベース)
ベクトル化したデータは、それぞれが「1536次元の座標」のような巨大な数値データになります。これを通常のデータベース(MySQLなど)に入れて検索しようとすると、計算量が膨大すぎて時間がかかります。
そこで、「近似近傍探索(Approximate Nearest Neighbor)」というアルゴリズムを使って、高速に「近いデータ」を探し出せるようにしたのがVector Storeです。
今回は、Pythonで手軽に扱える代表的な2つのライブラリを紹介します。
- FAISS (Facebook AI Similarity Search): Meta(旧Facebook)が開発。非常に高速で、オンメモリでの動作が得意。RAGのプロトタイプ開発によく使われます。
- ChromaDB: メタデータの管理が得意で、永続化(保存)も簡単。最近のAI開発で急速に普及しています。
今回は、インストールの手軽さと動作の軽快さから FAISS を中心に実装を進めます。
4. 実装Step 1:テキストのベクトル化
まずは準備として、必要なライブラリをインストールします。
pip install langchain-openai langchain-community faiss-cpu tiktoken※ GPU搭載マシン(NVIDIA製)をお使いの方は faiss-gpu を使うとさらに高速になりますが、学習用には faiss-cpu で十分です。
では、実際にテキストをベクトルに変換してみましょう。
import os
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
# .envからAPIキーを読み込み
load_dotenv()
# エンベディングモデルの初期化
# model="text-embedding-3-small" は、性能とコストのバランスが良い最新モデルです
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# テスト用テキスト
text = "StreamlitはPythonでWebアプリを作るためのフレームワークです。"
# ベクトル化を実行
vector = embeddings.embed_query(text)
# 結果の確認
print(f"テキスト: {text}")
print(f"ベクトルの次元数: {len(vector)}")
print(f"ベクトルの中身(先頭5つ): {vector[:5]}")実行すると、1536 という次元数(モデルによって異なります)と、[-0.012, 0.045, ...] といった数値の羅列が表示されます。これが、AIが理解した「この文章の意味」です。
テキスト: StreamlitはPythonでWebアプリを作るためのフレームワークです。
ベクトルの次元数: 1536
ベクトルの中身(先頭5つ): [-0.0028782603330910206, 0.016242273151874542, -0.03320642188191414, -0.05963829159736633, 0.02074938826262951]5. 実装Step 2:Vector Storeの構築と永続化
次に、前回学んだ「ドキュメントの読み込み・分割」と組み合わせて、実際のデータをVector Store(FAISS)に格納します。そして、後で再利用できるようにローカルディスクに保存します。
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
# 1. ダミーデータの作成(前回同様、実務ではPDFなどを読み込みます)
with open("knowledge.txt", "w", encoding="utf-8") as f:
f.write("""
プロジェクトAの概要: 次世代のAIチャットボットを開発するプロジェクト。
リーダーは佐藤さん、開発期間は2025年1月から6月まで。
プロジェクトBの概要: 社内システムのクラウド移行プロジェクト。
リーダーは鈴木さん、AWSを使用する予定。予算は500万円。
Streamlitの特徴: Pythonだけでフロントエンドを構築できる。
ステート管理には st.session_state を使用する。
""")
# 2. ロードと分割
loader = TextLoader("knowledge.txt", encoding="utf-8")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_documents(documents)
print(f"{len(chunks)} 個のチャンクを作成しました。")
# 3. Vector Storeの構築(ベクトル化とインデックス作成)
# ここでOpenAI APIが呼ばれ、課金が発生します(ごくわずかです)
db = FAISS.from_documents(chunks, embeddings)
# 4. ローカルへの保存
# "faiss_index" というフォルダが作成され、そこにデータが保存されます
db.save_local("faiss_index")
print("Vector Storeを構築し、保存しました。")これで、あなたの手元に「プロジェクトA」「プロジェクトB」「Streamlit」に関する知識を持った検索エンジンが完成しました。
6. 実装Step 3:意味検索(Semantic Search)を試す
作成したVector Storeを使って、実際に検索を試してみましょう。保存したインデックスを読み込んで検索します。
# 保存済みインデックスの読み込み
# (危険性のあるデシリアライズを許可するための設定 allow_dangerous_deserialization=True が必要な場合があります)
new_db = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
# 検索クエリ
query = "クラウド移行の予算はいくら?"
# 類似度検索の実行
# k=2 は「上位2件を取得」という意味です
found_docs = new_db.similarity_search(query, k=2)
print(f"質問: {query}\n")
for i, doc in enumerate(found_docs):
print(f"--- 検索結果 {i+1} ---")
print(doc.page_content)
print("-" * 20)実行結果のイメージ
質問: クラウド移行の予算はいくら?
--- 検索結果 1 ---
プロジェクトBの概要: 社内システムのクラウド移行プロジェクト。
リーダーは鈴木さん、AWSを使用する予定。予算は500万円。
--------------------
--- 検索結果 2 ---
プロジェクトAの概要: 次世代のAIチャットボットを開発するプロジェクト。
リーダーは佐藤さん、開発期間は2025年1月から6月まで。
--------------------注目してください。「クラウド移行」や「予算」という単語が含まれているテキストが正しくヒットしています。これがRAGのリトリーバル(検索)フェーズの核となる動きです。
7. Streamlitの最適化:st.cache_resource の活用
さて、ここからがStreamlit開発における最重要ポイントです。
Streamlitは、ボタンを押すなどの操作があるたびにスクリプト全体を再実行することを思い出してください。もし、以下のようなコードを書いてしまうとどうなるでしょうか?
# 悪い例:やってはいけない実装
import streamlit as st
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# アプリがリロードされるたびに実行される!
# 1. 重い処理(インデックス読み込み)が毎回走る → 遅い
# 2. APIコールが発生する場合、課金が重複する → お金の無駄
embeddings = OpenAIEmbeddings()
db = FAISS.load_local("faiss_index", embeddings)
st.write("検索準備完了")これを防ぐために、Streamlitには キャッシング(Caching) という機能があります。特に、データベース接続やMLモデルのような「重いリソース」を保持するためには st.cache_resource デコレータを使います。
正しい実装:キャッシュを使う
import streamlit as st
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
st.title("RAG検索デモ")
# キャッシュ関数を定義
# この関数は、引数が変わらない限り、2回目以降は実行されず
# メモリ内の結果を即座に返します。
@st.cache_resource
def load_vector_store():
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 永続化されたインデックスが存在するかチェック
if os.path.exists("faiss_index"):
db = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
return db
else:
st.error("インデックスが見つかりません。先に構築スクリプトを実行してください。")
return None
# 関数を呼び出し(初回のみ実行され、以降はキャッシュが使われる)
db = load_vector_store()
if db:
query = st.text_input("質問を入力してください")
if query:
docs = db.similarity_search(query, k=1)
st.write("### 検索結果")
st.write(docs[0].page_content)@st.cache_resource を付けるだけで、Streamlitは「この関数の戻り値(Vector Storeオブジェクト)をメモリに保存しておこう」と判断します。これにより、ユーザーがチャットを続けても、Vector Storeの読み込みは最初の一回だけで済み、動作が爆速になります。
構築スクリプトを含めたコード全体
実際に正しく実行できるように修正を加えたサンプルコードの全体を示します。このコードをstreamlit runで実行して下さい。
import os
from dotenv import load_dotenv
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
import streamlit as st
# 1. .envからAPIキーを読み込み
load_dotenv()
# 2. エンベディングモデルの初期化
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 3. ダミーデータの作成
with open("knowledge.txt", "w", encoding="utf-8") as f:
f.write("""
プロジェクトAの概要: 次世代のAIチャットボットを開発するプロジェクト。
リーダーは佐藤さん、開発期間は2025年1月から6月まで。
プロジェクトBの概要: 社内システムのクラウド移行プロジェクト。
リーダーは鈴木さん、AWSを使用する予定。予算は500万円。
Streamlitの特徴: Pythonだけでフロントエンドを構築できる。
ステート管理には st.session_state を使用する。
""")
# 4. テキストのロードと分割
loader = TextLoader("knowledge.txt", encoding="utf-8")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_documents(documents)
print(f"{len(chunks)} 個のチャンクを作成しました。")
# 5. Vector Storeの構築と保存
db = FAISS.from_documents(chunks, embeddings)
db.save_local("faiss_index")
print("Vector Storeを構築し、保存しました。")
# 6. 保存済みインデックスの読み込みと意味検索
new_db = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
query = "クラウド移行の予算はいくら?"
found_docs = new_db.similarity_search(query, k=2)
print(f"質問: {query}\n")
for i, doc in enumerate(found_docs):
print(f"--- 検索結果 {i+1} ---")
print(doc.page_content)
print("-" * 20)
st.title("RAG検索デモ")
# キャッシュ関数を定義
# この関数は、引数が変わらない限り、2回目以降は実行されず
# メモリ内の結果を即座に返します。
@st.cache_resource
def load_vector_store():
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 永続化されたインデックスが存在するかチェック
if os.path.exists("faiss_index"):
db = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
return db
else:
# knowledge.txt から自動でインデックスを再構築
if os.path.exists("knowledge.txt"):
loader = TextLoader("knowledge.txt", encoding="utf-8")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
chunks = text_splitter.split_documents(documents)
db = FAISS.from_documents(chunks, embeddings)
db.save_local("faiss_index")
st.info("インデックスが見つからなかったため自動で再構築しました。")
return db
else:
st.error("knowledge.txt が見つかりません。インデックスを作成できません。")
return None
# 関数を呼び出し(初回のみ実行され、以降はキャッシュが使われる)
db = load_vector_store()
if db:
query = st.text_input("質問を入力してください")
if query:
docs = db.similarity_search(query, k=1)
st.write("### 検索結果")
st.write(docs[0].page_content)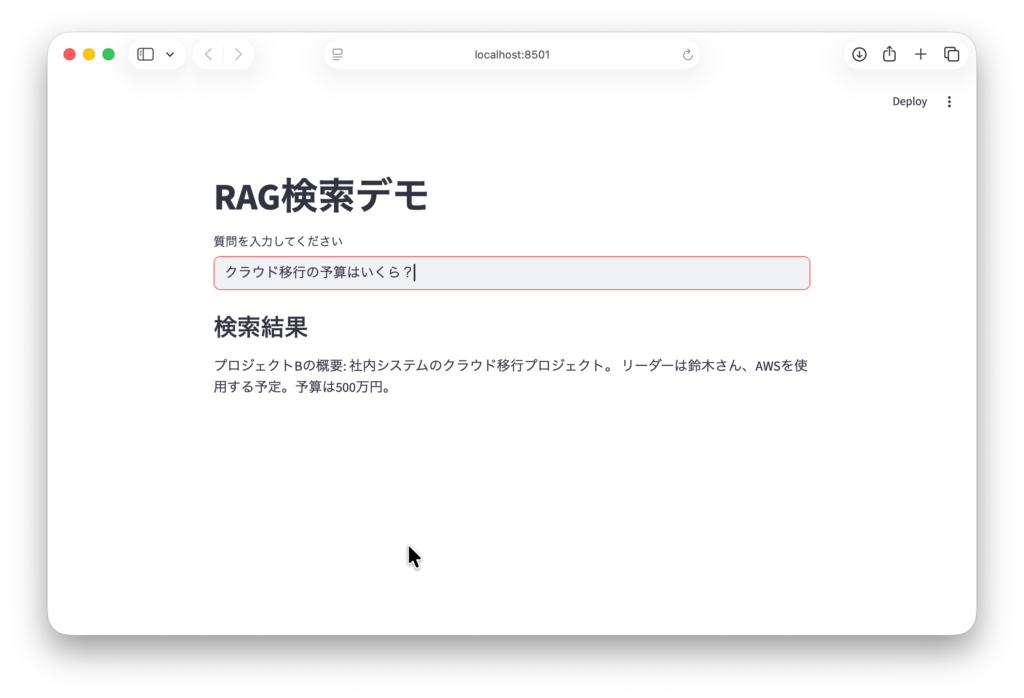
8. まとめと次回予告
今回は、テキストデータに「意味」を与え、検索可能な状態にするまでのフローを解説しました。
- エンベディング: 言葉を数値の座標に変換し、意味の計算を可能にする。
- Vector Store (FAISS): ベクトルデータを高速に検索できるデータベース。
st.cache_resource: Streamlitで重いリソース(DBやモデル)を扱う際の必須テクニック。
これで、「質問を受け取り」→「関連情報を検索する」までのパーツが揃いました。
次回、第5回「StreamlitとRAGを統合:基本の質問応答アプリを完成させる」では、これまで作成したすべてのパーツ(LLM, Prompt, Vector Store, Streamlit UI)を合体させます。
いよいよ、あなたの独自のドキュメントについて流暢に答えてくれる、オリジナルのチャットボットが動き出します。
最後まで読んでいただきありがとうございます。











コメント