
こんにちはJS2IIUです。
連載「StreamlitとRAGで作る:実用的なAIチャットボット開発ガイド」の第7回です。
前回は、ストリーミング応答とチャット履歴の管理を実装し、ユーザー体験(UX)を大幅に向上させました。アプリとしての使い勝手はかなり良くなったはずです。しかし、RAGアプリを運用し始めると、開発者は必ずある「壁」にぶつかります。それは「回答の精度」です。
「ドキュメントには書いてあるはずなのに、AIが『分かりません』と答える」
「まったく関係のないドキュメントを参照して、見当違いな回答をする」
これらは、LLMの頭が悪いのではなく、必要な情報が正しく検索できていない(Retrievalの失敗)ことが最大の原因です。
第7回となる今回は、この検索精度を劇的に向上させるためのプロフェッショナルな技術、「Multi-Query(クエリ拡張)」と「Re-ranking(再順位付け)」について解説します。
RAGの仕組みを一段深く理解し、実用レベルの検索システムを構築しましょう。今回もよろしくお願いします。
1. はじめに:なぜベクトル検索だけでは不十分なのか?
これまで私たちは、検索システムとして「ベクトル検索(Vector Search)」一本で勝負してきました。これは、質問文とドキュメントを数値ベクトルに変換し、距離が近いものを探す手法です。
しかし、この手法には弱点があります。
- 質問の表現揺らぎ: ユーザーが「AWSのコスト削減」と検索したとき、ドキュメントに「クラウド利用料の最適化」と書かれていると、意味は同じでもベクトル空間上の距離が遠くなり、ヒットしないことがあります。
- 密度の限界: ベクトル検索は「大まかな意味の近さ」を高速に見つけるのは得意ですが、「文脈的な厳密な一致」を判断するのは苦手です。結果として、上位3件の中に無関係なノイズが混ざりやすくなります。
これを解決するのが、今回紹介する「広げる(Multi-Query)」と「絞る(Re-ranking)」という2つの戦略です。
2. 戦略その1:Multi-Query Retriever(クエリ拡張)
概念:聞き方を変えれば、見つかるかもしれない
ユーザーの質問は常に完璧とは限りません。曖昧だったり、独特な言い回しをしたりします。
Multi-Query Retrieverは、「ユーザーの元の質問を、LLMを使って様々な角度から言い換えさせ、それら全てで検索をかける」という手法です。
例えば、「RAGの遅延対策」という質問に対し、裏側で以下のように拡張します。
- 「RAGのレスポンス速度を上げる方法は?」
- 「Vector Storeの検索レイテンシを減らすには?」
- 「LLMの推論時間を短縮するテクニック」
これら複数のクエリで検索を行い、得られたドキュメントの重複を排除(ユニーク化)して最終的な検索結果とします。これにより、表現の揺らぎによる検索漏れ(Recallの低下)を防ぐことができます。
実装:LangChainでのMulti-Query
LangChainには MultiQueryRetriever が用意されており、数行で実装可能です。
from langchain_openai import ChatOpenAI
from langchain_classic.retrievers import MultiQueryRetriever
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
import logging
# loggerインスタンスを作成
logger = logging.getLogger("langchain_classic.retrievers.multi_query")
# ログ設定(裏でどんなクエリが生成されたか見るため)
logging.basicConfig(level=logging.INFO)
logging.getLogger("langchain_classic.retrievers.multi_query").setLevel(logging.INFO)
# 1. 前提リソースの準備
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.load_local("faiss_index", embeddings, allow_dangerous_deserialization=True)
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# 2. Multi-Query Retrieverの構築
# LLMを使って、元の質問から3つの異なる視点の質問を生成させます
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
# 3. 実行テスト
question = "RAGの精度を上げるには?"
unique_docs = retriever_from_llm.invoke(question)
print(f"検索されたドキュメント数: {len(unique_docs)}")このコードを実行すると、コンソール(ログ)に「生成された代替クエリ」が表示されるはずです。たった一つの質問から、網羅的な検索が行われる様子が確認できます。
INFO:faiss.loader:Loading faiss.
INFO:faiss.loader:Successfully loaded faiss.
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
INFO:langchain_classic.retrievers.multi_query:Generated queries: ['RAGのパフォーマンスを向上させるための方法は何ですか?', 'RAGの精度を向上させるために考慮すべき要素は何ですか?', 'RAGの精度を高めるための具体的な戦略やテクニックはありますか?']
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
INFO:httpx:HTTP Request: POST https://api.openai.com/v1/embeddings "HTTP/1.1 200 OK"
検索されたドキュメント数: 33. 戦略その2:Re-ranking(再順位付け)
概念:採用担当マネージャーの目
Multi-Queryで検索範囲を広げると、今度は「関係のないドキュメント」まで拾ってしまうリスクが増えます。そこで登場するのが Re-ranking(リランキング) です。
通常のベクトル検索(Bi-Encoder方式)は、高速ですが精度はそこそこです。
対してRe-ranking(Cross-Encoder方式)は、計算コストは高いですが、「質問とドキュメントのペアをじっくり読み比べて、関連度を厳密に採点する」ことができます。
この2つを組み合わせるのが鉄板の構成です。
- 一次検索(Vector Search): 高速に候補を多め(例:20件)に集める。
- 二次検索(Re-ranking): 集めた20件をCross-Encoderで精査し、本当に重要なトップ5件だけをLLMに渡す。
これは採用活動に似ています。まずリクルーター(Vector Search)が履歴書をキーワードでざっと集め、その中から採用担当者(Re-ranker)が詳しく面接して最終候補を選ぶのです。
実装:Cohere Rerankerを使う
Re-rankingの実装には、性能と手軽さから Cohere Reranker がよく使われます(APIキーの取得が必要です)。今回はこれを使って実装します。
※ 事前に pip install langchain-cohere を実行して下さい。また、CohereのAPIキーを取得しておいてください。以下のリンク先からユーザー登録し、APIキーを取得することが可能です。
Enterprise AI: Private, Secure, Customizable | Cohere
https://cohere.com/
Cohere | LangChain Reference
https://reference.langchain.com/python/integrations/langchain_cohere/?h=cohe
import os
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# APIキーの設定(環境変数または直接指定)
# os.environ["COHERE_API_KEY"] = "your_cohere_api_key"
# 1. ベースとなる検索機(Vector Store)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
vectorstore = FAISS.load_local("faiss_index", embeddings, allow_dangerous_deserialization=True)
# 通常より多めに取得するように設定します(例:20件)
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 20})
# 2. Reranker(コンプレッサー)の設定
# 検索結果を圧縮(Compression)する役割として定義されます
compressor = CohereRerank(
model="rerank-multilingual-v3.0", # 日本語に対応したモデル
top_n=5 # 最終的に残す件数
)
# 3. パイプラインの構築
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
# 4. 実行テスト
question = "RAGのコスト削減方法は?"
compressed_docs = compression_retriever.invoke(question)
print(f"--- Re-ranking後の上位 {len(compressed_docs)} 件 ---")
for i, doc in enumerate(compressed_docs):
# doc.metadata['relevance_score'] に関連度スコアが入ります
score = doc.metadata.get('relevance_score', 0)
print(f"順位 {i+1}: スコア {score:.4f} - {doc.page_content[:50]}...")実行結果:
--- Re-ranking後の上位 3 件 ---
順位 1: スコア 0.0000 - プロジェクトBの概要: 社内システムのクラウド移行プロジェクト。
リーダーは鈴木さん、AWS...
順位 2: スコア 0.0000 - プロジェクトAの概要: 次世代のAIチャットボットを開発するプロジェクト。
リーダーは佐藤さ...
順位 3: スコア 0.0000 - Streamlitの特徴: Pythonだけでフロントエンドを構築できる。
ステート管理には...この結果を見ると、ベクトル検索の段階では順位が低かった(あるいは埋もれていた)ドキュメントが、Re-rankingによって上位に浮上してくる現象を確認できることがあります。これこそが「精度の向上」です。
4. Streamlitアプリへの統合
では、前回までに作成したチャットアプリに、この高度な検索戦略を組み込みましょう。
ここでは、「Vector Searchで多めに検索」し、「Re-rankingで絞り込む」構成を採用します。これが最もコスト対効果が高い構成です。
app.py の load_retriever 関数を以下のようにアップグレードします。
import streamlit as st
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
# ...(省略:importsや環境変数読み込み)...
@st.cache_resource
def load_advanced_retriever():
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
try:
# ベクトルストアの読み込み
vectorstore = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
# 1. ベース検索機: まずは広く20件集める
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 20})
# 2. リランカー: 高精度にトップ5に絞る
# APIキーがない場合はエラーハンドリングが必要です
try:
compressor = CohereRerank(
model="rerank-multilingual-v3.0",
top_n=5
)
retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
return retriever
except Exception:
st.warning("Cohere APIキーが見つからないか、エラーが発生しました。通常の検索を使用します。")
return vectorstore.as_retriever(search_kwargs={"k": 5})
except Exception as e:
st.error(f"Index読み込みエラー: {e}")
return None
# アプリ内でこの関数を呼び出す
retriever = load_advanced_retriever()load_retriever 関数を反映したStreamlitアプリのコード全体
このコードを以前のStreamlitのコードに組み込んだ全体コードを示します。
import streamlit as st
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, AIMessage
from dotenv import load_dotenv
# 環境変数の読み込み
load_dotenv()
# --- 設定 ---
st.set_page_config(page_title="RAG Chatbot Advanced", layout="wide")
st.title("RAGチャットボット (Streaming & History)")
# --- 1. リソースの読み込み (Cache) ---
@st.cache_resource
def load_retriever():
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
try:
# 第4回で作成したインデックスを読み込む
vectorstore = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
return vectorstore.as_retriever(search_kwargs={"k": 3})
except Exception as e:
return None
retriever = load_retriever()
if not retriever:
st.error("Vector Storeが見つかりません。第4回のコードを実行してインデックスを作成してください。")
st.stop()
# --- 2. プロンプトとLLMの準備 ---
# 履歴(chat_history)を受け取れるように構造化します
prompt = ChatPromptTemplate.from_messages([
("system", """
あなたは優秀なアシスタントです。
以下の「コンテキスト」と「会話履歴」に基づいて、ユーザーの質問に答えてください。
コンテキストにない情報は答えず、「わかりません」と伝えてください。
# コンテキスト
{context}
"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
])
# ストリーミング対応のために streaming=True は必須ではありませんが、明示しておくと良いでしょう
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# --- 3. チャット履歴の管理 (Session State) ---
if "messages" not in st.session_state:
st.session_state.messages = []
# 過去の会話をUIに表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# --- 4. 履歴データの整形関数 ---
# LangChainに渡すために、辞書型の履歴をMessageオブジェクトのリストに変換します
def get_chat_history_features(messages):
history_buffer = []
for msg in messages:
if msg["role"] == "user":
history_buffer.append(HumanMessage(content=msg["content"]))
elif msg["role"] == "assistant":
history_buffer.append(AIMessage(content=msg["content"]))
return history_buffer
# --- 5. メインチャットループ ---
if query := st.chat_input("質問を入力してください..."):
# ユーザー入力の表示と保存
st.session_state.messages.append({"role": "user", "content": query})
with st.chat_message("user"):
st.markdown(query)
# AI応答の処理
with st.chat_message("assistant"):
# 検索(ここは同期処理で待つ必要があります)
relevant_docs = retriever.invoke(query)
context_text = "\n\n".join([d.page_content for d in relevant_docs])
# 履歴オブジェクトの作成
# 直前のユーザー入力は prompt の {question} に入るため、履歴からは除外しても良いですが、
# ここでは過去分すべてを渡す形にします(現在進行中の質問は除く)
chat_history = get_chat_history_features(st.session_state.messages[:-1])
# チェーンの定義
chain = prompt | llm | StrOutputParser()
# ストリーミング実行
# stream() メソッドはジェネレータ(文字列の断片を次々に出すもの)を返します
response_generator = chain.stream({
"context": context_text,
"chat_history": chat_history,
"question": query
})
# st.write_stream でリアルタイム表示しつつ、完了後の全テキストを取得
response_text = st.write_stream(response_generator)
# 履歴に追加
st.session_state.messages.append({"role": "assistant", "content": response_text})
# (オプション)参照元の表示
# ストリーミング完了後にソースを表示します
with st.expander("参照元の情報を表示"):
for doc in relevant_docs:
st.markdown(f"- {doc.page_content[:100]}...")
st.caption(f"Source: {doc.metadata.get('source', 'Unknown')}")
デバッグ機能の追加:検索スコアの可視化
せっかくRe-rankingを導入したので、ユーザー(または開発者)が「どのくらいの自信を持って検索したのか」を確認できるように、UI側も少し修正します。
Re-rankingを通したドキュメントには relevance_score(関連度スコア)が付与されています。これを st.expander 内で表示してみましょう。
# ...(チャット処理部分)...
# 検索実行
relevant_docs = retriever.invoke(query)
# ...(回答生成処理)...
# ソース表示部分の修正
with st.expander("参照元の情報とスコアを表示"):
for i, doc in enumerate(relevant_docs):
# スコアの取得(通常の検索の場合はキーがない可能性があるので.getを使う)
score = doc.metadata.get("relevance_score")
st.markdown(f"**出典 {i+1}**")
if score:
st.caption(f"関連度スコア: {score:.4f}")
st.text(doc.page_content)
st.divider()検索スコアを表示するよう修正したコード全体
import streamlit as st
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_classic.retrievers import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, AIMessage
from dotenv import load_dotenv
# 環境変数の読み込み
load_dotenv()
# --- 設定 ---
st.set_page_config(page_title="RAG Chatbot Advanced", layout="wide")
st.title("RAGチャットボット (Streaming & History)")
# --- 1. リソースの読み込み (Cache) ---
@st.cache_resource
def load_advanced_retriever():
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
try:
vectorstore = FAISS.load_local(
"faiss_index",
embeddings,
allow_dangerous_deserialization=True
)
base_retriever = vectorstore.as_retriever(search_kwargs={"k": 20})
try:
compressor = CohereRerank(
model="rerank-multilingual-v3.0",
top_n=5
)
retriever = ContextualCompressionRetriever(
base_compressor=compressor,
base_retriever=base_retriever
)
return retriever
except Exception:
st.warning("Cohere APIキーが見つからないか、エラーが発生しました。通常の検索を使用します。")
return vectorstore.as_retriever(search_kwargs={"k": 5})
except Exception as e:
st.error(f"Index読み込みエラー: {e}")
return None
retriever = load_advanced_retriever()
if not retriever:
st.error("Vector Storeが見つかりません。第4回のコードを実行してインデックスを作成してください。")
st.stop()
# --- 2. プロンプトとLLMの準備 ---
# 履歴(chat_history)を受け取れるように構造化します
prompt = ChatPromptTemplate.from_messages([
("system", """
あなたは優秀なアシスタントです。
以下の「コンテキスト」と「会話履歴」に基づいて、ユーザーの質問に答えてください。
コンテキストにない情報は答えず、「わかりません」と伝えてください。
# コンテキスト
{context}
"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
])
# ストリーミング対応のために streaming=True は必須ではありませんが、明示しておくと良いでしょう
llm = ChatOpenAI(model_name="gpt-4o-mini", temperature=0)
# --- 3. チャット履歴の管理 (Session State) ---
if "messages" not in st.session_state:
st.session_state.messages = []
# 過去の会話をUIに表示
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# --- 4. 履歴データの整形関数 ---
# LangChainに渡すために、辞書型の履歴をMessageオブジェクトのリストに変換します
def get_chat_history_features(messages):
history_buffer = []
for msg in messages:
if msg["role"] == "user":
history_buffer.append(HumanMessage(content=msg["content"]))
elif msg["role"] == "assistant":
history_buffer.append(AIMessage(content=msg["content"]))
return history_buffer
# --- 5. メインチャットループ ---
if query := st.chat_input("質問を入力してください..."):
# ユーザー入力の表示と保存
st.session_state.messages.append({"role": "user", "content": query})
with st.chat_message("user"):
st.markdown(query)
# AI応答の処理
with st.chat_message("assistant"):
# 検索実行
relevant_docs = retriever.invoke(query)
context_text = "\n\n".join([d.page_content for d in relevant_docs])
# 履歴オブジェクトの作成
# 直前のユーザー入力は prompt の {question} に入るため、履歴からは除外しても良いですが、
# ここでは過去分すべてを渡す形にします(現在進行中の質問は除く)
chat_history = get_chat_history_features(st.session_state.messages[:-1])
# チェーンの定義
chain = prompt | llm | StrOutputParser()
# ストリーミング実行
# stream() メソッドはジェネレータ(文字列の断片を次々に出すもの)を返します
response_generator = chain.stream({
"context": context_text,
"chat_history": chat_history,
"question": query
})
# st.write_stream でリアルタイム表示しつつ、完了後の全テキストを取得
response_text = st.write_stream(response_generator)
# 履歴に追加
st.session_state.messages.append({"role": "assistant", "content": response_text})
# 参照元の情報とスコアを表示
with st.expander("参照元の情報とスコアを表示"):
for i, doc in enumerate(relevant_docs):
score = doc.metadata.get("relevance_score")
st.markdown(f"**出典 {i+1}**")
if score:
st.caption(f"関連度スコア: {score:.4f}")
st.text(doc.page_content)
st.divider()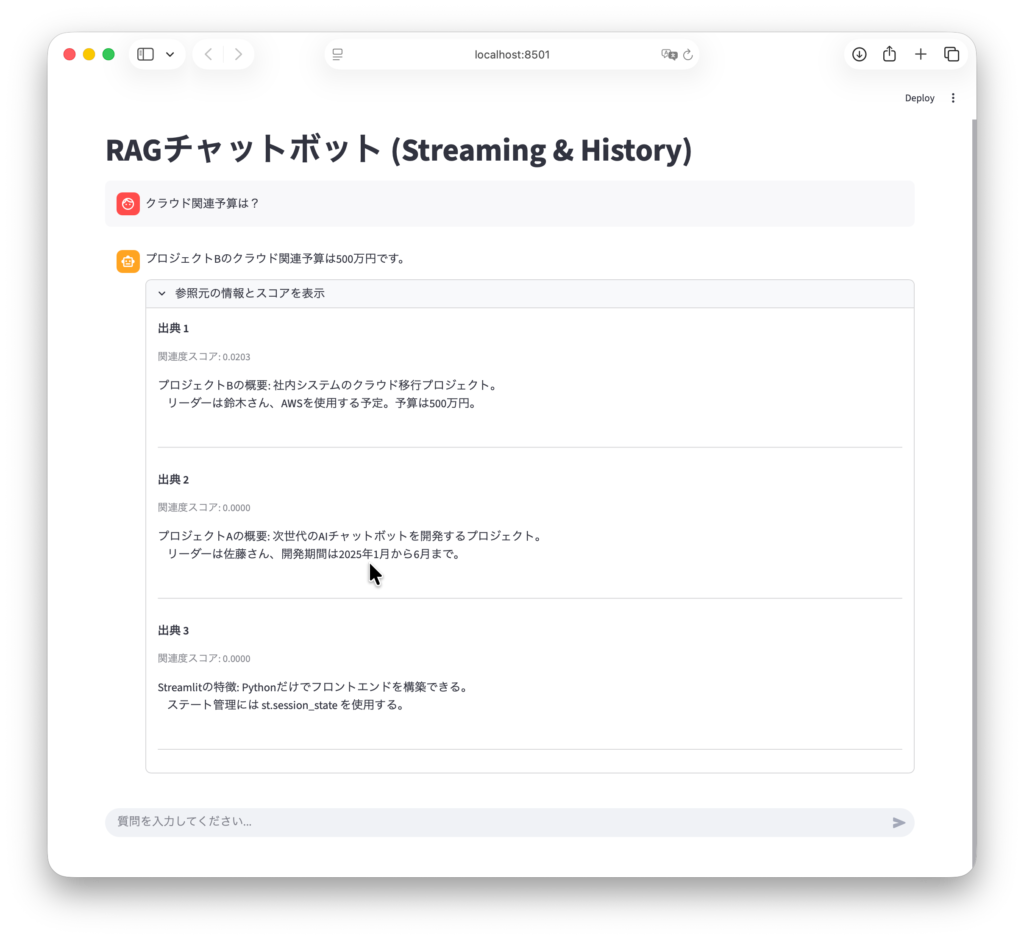
5. RAGの評価(Evaluation)について
今回、私たちは「精度が上がったはずだ」と考えましたが、それを客観的に証明するにはどうすればよいでしょうか?
これを扱うのが RAG Evaluation(RAG評価) という分野です。
本格的な評価には Ragas や DeepEval といったフレームワークを使いますが、基本的な考え方は以下の通りです。
- Ground Truth(正解データ)を用意する: 「この質問に対しては、このドキュメントが参照され、こういう回答が返るべき」というセットを作る。
- Faithfulness(忠実性): 回答が検索されたドキュメントの内容に基づいているか(ハルシネーションしていないか)。
- Answer Relevance(回答関連性): 質問に対して適切な回答になっているか。
- Context Precision(検索精度): 必要なドキュメントが上位に来ているか。
Re-rankingを導入すると、特に4つ目の「Context Precision」が劇的に改善します。興味がある方は、ぜひこれらのキーワードでさらに深く調べてみてください。
6. まとめと次回予告
今回は、RAGの「頭脳」にあたる検索アルゴリズムを強化しました。
- Multi-Query Retriever: 質問を言い換えて、検索の網羅性(Recall)を高める。
- Re-ranking: 高速なベクトル検索の結果を、高精度なモデルで並べ替えて精度(Precision)を高める。
この「広げて(Multi-Query)、絞る(Re-ranking)」アプローチは、現在のRAG開発におけるデファクトスタンダードとも言える構成です。これを実装できたあなたは、すでに初心者レベルを脱しています。
さて、システムが複雑になるにつれて、コードの見通しが悪くなってきているのを感じませんか?
「プロンプト定義」「検索」「後処理」「LLM呼び出し」…これらがスパゲッティのように絡まり合うと、保守が大変です。
次回、第8回「LangChain Expression Language (LCEL)によるパイプラインのモジュール化」では、この複雑な処理フローを、驚くほど美しく、宣言的に記述できる LCEL について詳しく解説します。
最後まで読んでいただきありがとうございました。











コメント