
こんにちはJS2IIUです。
生成AIを活用したアプリケーション開発において、現在最も注目されている技術の一つがRAG(Retrieval-Augmented Generation)です。社内ドキュメントや専門書の内容をAIに回答させるこの技術は、ビジネスの現場で急速に普及しています。
しかし、RAGを実装しようとしたとき、最初にぶつかる壁が「データの準備」ではないでしょうか?
手元にある大量のPDFマニュアルや契約書。これらをAIが読める形、すなわち「Vector Store(ベクトルデータベース)」に変換しなければ、RAGは始まりません。
今回は、PythonのWebフレームワークであるStreamlitと、高速なベクトル検索ライブラリFAISSを組み合わせ、「ブラウザからPDFをドラッグ&ドロップするだけで、ローカル環境にVector Storeを作製・保存できるツール」を作成します。
コマンドラインでの操作が苦手なチームメンバーでも使えるような、実用的なGUIツールを目指しましょう。今回もよろしくお願いします。
技術構成とアーキテクチャ
実装に入る前に、今回使用する技術スタックと、その役割を整理します。
- Streamlit: フロントエンドを担当。PythonだけでWeb UIが作れるため、データサイエンス領域で標準的に使われています。
- LangChain: LLMアプリケーション開発のフレームワーク。PDFの読み込みからベクトル化までのパイプラインを繋ぐ接着剤の役割を果たします。
- FAISS (Facebook AI Similarity Search): Meta社(旧Facebook)が開発したライブラリ。大量のベクトルデータを高速に検索・保存することに特化しており、ローカル環境での動作に優れています。
- pypdf: PDFファイルからテキストを抽出するためのライブラリです。
- OpenAI Embeddings: テキストをベクトル(数値の羅列)に変換するモデル。今回は精度を重視してOpenAIを使用しますが、記事の後半では完全無料のローカルモデルへの切り替え方も解説します。
処理の流れ
今回のアプリケーションは、以下のフローで動作します。
- Upload: ユーザーがStreamlit経由で複数のPDFをアップロード。
- Load: PythonがPDFからテキストを抽出。
- Split: 長いテキストを、AIが処理しやすいサイズ(チャンク)に分割。
- Embed: テキストチャンクをベクトルデータへ変換。
- Save: FAISSインデックスとしてローカルフォルダに保存。
開発環境のセットアップ
まずは必要なライブラリをインストールしましょう。ターミナルで以下のコマンドを実行してください。
pip install streamlit langchain langchain-community langchain-openai faiss-cpu pypdf※ GPU環境がある場合は faiss-gpu も選択肢に入りますが、今回は手軽さを優先して faiss-cpu を使用します。
実装ステップ:PDF処理パイプラインの構築
それでは、コードを書き進めていきましょう。ファイル名は app.py とします。
Step 1: UIと設定の準備
まずはStreamlitの基本設定と、OpenAI APIキーの入力欄を作成します。
import streamlit as st
import os
import tempfile
# LangChain関連のインポート
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
# ページ設定
st.set_page_config(page_title="PDF to FAISS Builder", layout="wide")
st.title("RAG用 ローカルVector Store 作成ツール")
# サイドバーで設定を行う
with st.sidebar:
st.header("設定")
openai_api_key = st.text_input("OpenAI API Key", type="password")
if openai_api_key:
os.environ["OPENAI_API_KEY"] = openai_api_key
st.markdown("---")
# チャンクサイズの調整用UI
chunk_size = st.number_input("Chunk Size (文字数)", min_value=100, max_value=2000, value=500)
chunk_overlap = st.number_input("Chunk Overlap (重複)", min_value=0, max_value=500, value=50)解説:
APIキーなどの機密情報は、コードに直書きせず、UIから入力するか環境変数で管理するのがセキュリティの基本です。また、chunk_size(分割サイズ)や chunk_overlap(重複幅)をUIで調整できるようにしておくと、ドキュメントの性質に合わせて試行錯誤しやすくなります。
Step 2: PDFアップロードとTempfileの魔術
ここが今回の実装で最も「ハマりやすい」ポイントです。
Streamlitの file_uploader はファイルをメモリ上のデータ(BytesIO)として扱いますが、LangChainの PyPDFLoader は「ファイルパス(ディスク上の場所)」を引数に要求します。このギャップを埋めるために tempfile を使用します。
# メインエリア: ファイルアップロード
uploaded_files = st.file_uploader(
"PDFファイルをアップロードしてください(複数可)",
type="pdf",
accept_multiple_files=True
)
create_button = st.button("Vector Storeを作製・保存")
if create_button and uploaded_files:
if not openai_api_key:
st.error("OpenAI APIキーを入力してください。")
else:
with st.spinner("ドキュメントを処理中..."):
all_documents = []
# アップロードされた各ファイルを処理
for uploaded_file in uploaded_files:
# 1. 一時ファイルとしてディスクに書き出す
with tempfile.NamedTemporaryFile(delete=False, suffix=".pdf") as tmp_file:
tmp_file.write(uploaded_file.read())
tmp_path = tmp_file.name
try:
# 2. PyPDFLoaderでパスを指定して読み込む
loader = PyPDFLoader(tmp_path)
documents = loader.load()
all_documents.extend(documents)
finally:
# 3. 読み込み終わったら一時ファイルを削除(後始末)
os.remove(tmp_path)
st.info(f"合計 {len(all_documents)} ページを読み込みました。")解説:tempfile.NamedTemporaryFile を使うことで、OSの一時フォルダに実体のあるファイルを作成しています。LangChainに読み込ませた直後に os.remove で削除することで、サーバーのディスク容量を圧迫しないように配慮しています。これが実務的な実装の定石です。
Step 3: テキストの分割(Text Splitting)
読み込んだテキストをそのままベクトル化すると、長すぎてAIが扱えなかったり、検索精度が落ちたりします。適切なサイズに分割します。
# テキスト分割の設定
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
)
# ドキュメントを分割
splitted_docs = text_splitter.split_documents(all_documents)
st.info(f"チャンク分割完了: 合計 {len(splitted_docs)} チャンク")解説:RecursiveCharacterTextSplitter は、単に文字数で切るのではなく、段落、改行、空白などの「意味の区切り」を優先して分割してくれる賢いクラスです。chunk_overlap を設定することで、分割の境界にある文脈が途切れるのを防ぎます。
Step 4 & 5: ベクトル化とローカル保存
最後に、FAISSを使ってベクトル化し、ローカルに保存します。
# Vector Storeの構築
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splitted_docs, embeddings)
# 保存先のパス
save_path = "faiss_index_local"
# ローカルに保存
vectorstore.save_local(save_path)
st.success(f"完了! '{save_path}' フォルダにVector Storeを保存しました。")解説:vectorstore.save_local(save_path) を実行すると、指定したフォルダ内にインデックスファイル(.faiss)とメタデータ(.pkl)が生成されます。これさえあれば、次回からはPDFを読み込み直すことなく、このフォルダをロードするだけで高速検索が可能になります。
完全版ソースコード
ここまでの内容をまとめたコードが以下になります。コピー&ペーストして app.py として保存し、streamlit run app.py で実行してみてください。
import streamlit as st
import os
import tempfile
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv
# --- 設定 ---
load_dotenv()
st.set_page_config(page_title="PDF to FAISS Builder", layout="wide")
st.title("RAG用 ローカルVector Store 作成ツール")
# --- サイドバー設定 ---
with st.sidebar:
st.header("設定パネル")
st.markdown("---")
chunk_size = st.number_input("Chunk Size (文字数)", min_value=100, max_value=2000, value=500)
chunk_overlap = st.number_input("Chunk Overlap (重複)", min_value=0, max_value=500, value=50)
# --- メインエリア: PDFアップロード ---
uploaded_files = st.file_uploader(
"PDFファイルをアップロードしてください(複数可)",
type="pdf",
accept_multiple_files=True
)
create_button = st.button("Vector Storeを作製・保存")
if create_button and uploaded_files:
with st.spinner("ドキュメントを処理中..."):
try:
all_documents = []
# 1. 一時ファイルとして保存し、Loaderで読み込む
# Streamlitのアップロードファイルはメモリ上にあるため、
# PyPDFLoaderなどのLoaderがパスを要求する場合、一時ファイル経由が確実です。
for uploaded_file in uploaded_files:
with tempfile.NamedTemporaryFile(delete=False, suffix=".pdf") as tmp_file:
tmp_file.write(uploaded_file.read())
tmp_path = tmp_file.name
loader = PyPDFLoader(tmp_path)
documents = loader.load()
all_documents.extend(documents)
# 後始末
os.remove(tmp_path)
st.info(f"合計 {len(all_documents)} ページを読み込みました。")
# 2. テキストの分割 (Text Splitting)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
)
splitted_docs = text_splitter.split_documents(all_documents)
st.info(f"チャンク分割完了: 合計 {len(splitted_docs)} チャンク")
# 3. ベクトル化とFAISSへの格納 (Embedding & Indexing)
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(splitted_docs, embeddings)
# 4. ローカルへの保存
save_path = "faiss_index_local"
vectorstore.save_local(save_path)
st.success(f"完了! '{save_path}' フォルダにVector Storeを保存しました。")
st.balloons()
except Exception as e:
st.error(f"エラーが発生しました: {e}")
elif create_button and not uploaded_files:
st.warning("PDFファイルをアップロードしてください。")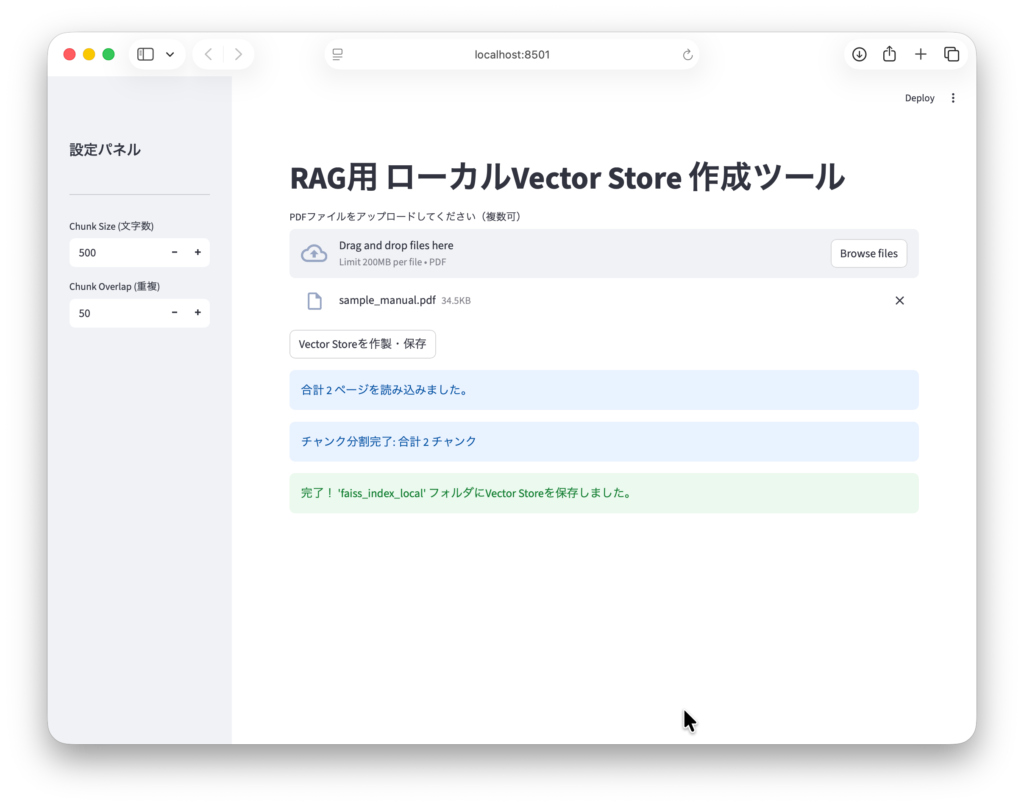
応用:完全ローカル環境(無料)への切り替え
ここまではOpenAIのEmbeddingsを使用しましたが、「社内規定でデータを外部に出せない」「APIコストをゼロにしたい」というケースもあるでしょう。
その場合、HuggingFaceが提供するオープンなモデルを使用することで、PC内部(ローカル)だけで完結させることができます。これにはPyTorchなどの機械学習ライブラリが裏側で動作します。
変更手順:
- 追加ライブラリをインストール:
pip install sentence-transformers - インポートの変更とモデルの差し替え:
# from langchain_openai import OpenAIEmbeddings # 削除
from langchain_community.embeddings import HuggingFaceEmbeddings # 追加
# ... (中略) ...
# ベクトル化部分の変更
# embeddings = OpenAIEmbeddings() # 削除
# 多言語対応の高性能・軽量モデルを指定
embeddings = HuggingFaceEmbeddings(model_name="intfloat/multilingual-e5-large")
vectorstore = FAISS.from_documents(splitted_docs, embeddings)これだけで、インターネット接続を必要としない、完全プライベートなVector Store構築環境が出来上がります。ただし、マシンスペック(特にCPU/GPU性能)によって処理時間は長くなる点に注意してください。
まとめ
今回は、StreamlitとFAISSを用いて、RAGのためのデータ基盤となるVector Store構築ツールを作成しました。
このツールの利点は、「データの準備」と「チャットボット本体」を分離できることです。
一度このツールで faiss_index_local フォルダを作成してしまえば、チャットボット側のアプリでは以下のようにロードするだけで済みます。
# チャットボット側での利用例
vectorstore = FAISS.load_local("faiss_index_local", embeddings, allow_dangerous_deserialization=True)
retriever = vectorstore.as_retriever()毎回PDFを解析する必要がなくなり、アプリの起動を高速化することができます。
ぜひ、このコードをベースに、皆様のプロジェクトに合わせたカスタマイズを行ってみてください。最後まで読んでいただきありがとうございます。


コメント