
こんにちはJS2IIUです。
「StreamlitとRAGで作る:実用的なAIチャットボット開発ガイド」の第9回です。
前回は、LCEL(LangChain Expression Language)を使ってコードを美しくモジュール化しました。開発者としての体験(DX)はこれで最高になりましたね。
しかし、ユーザーの体験(UX)はどうでしょうか?
RAGアプリで最も「ユーザー体験が悪化する瞬間」。それは、チャットの応答待ちではありません。
「大量のPDFファイルをアップロードし、インデックスを作成している時間」です。
数十ページの資料なら数秒で終わりますが、数百ページのマニュアルや技術書を取り込もうとすると、処理時間は数分に及ぶこともあります。その間、Streamlitの画面はどうなるでしょうか? まるでフリーズしたかのように固まり、ユーザーは「壊れたのかな?」と思ってタブを閉じてしまうかもしれません。
今回は、この「長時間処理(Long-Running Process)」に立ち向かいます。
Streamlitの便利なUI機能による解決策から、Pythonのスレッドを使った非同期処理、そして本格的なジョブキューの概念まで、プロダクション環境で必須となる「待ち時間の設計」を学びましょう。今回もよろしくお願いします。
1. はじめに:なぜアプリは「固まる」のか?
まず、Streamlitの裏側で何が起きているのかを理解しましょう。
Streamlitは基本的にシングルスレッド(厳密にはセッションごとのメインスレッド)で動作しています。ユーザーがボタンを押すと、Pythonスクリプトが上から下へと実行されます。この時、スクリプトの途中に「1分かかる処理」があると、その処理が終わるまでStreamlitは次の行に進めず、画面の描画更新も止まってしまいます。
これが「フリーズ」の正体です。
これを回避するためには、以下の2つのアプローチがあります。
- UXによる解決: 処理は同期(直列)で行うが、リッチな進捗表示を出して「動いている」ことを伝える。
- アーキテクチャによる解決: 重い処理を別のスレッドやプロセス(バックグラウンド)に逃がし、メインのUIを解放する。
順に見ていきましょう。
2. 【初級編】進捗を見せる技術:st.status の活用
RAGのインデックス作成は、実は「終わるまで次の作業(検索)ができない」性質の処理です。そのため、無理にバックグラウンドに回すよりも、「今何をしているか」を詳細に見せる方が、ユーザーにとって安心感がある場合があります。
Streamlit 1.25以降で導入された st.status は、まさにこのためにある機能です。
従来の課題
st.spinner(くるくる回るアイコン)は便利ですが、「読み込み中…」としか表示できず、あとどれくらいかかるのか、今どの段階なのかが分かりません。
st.status による解決
st.status を使うと、処理のステップごとにログを表示し、完了後にはコンパクトに折りたたむことができます。
import streamlit as st
import time
st.title("ドキュメント登録プロセス")
# ファイルアップロードのシミュレーション
if st.button("ドキュメント処理開始"):
# st.status で進捗状況を表示するコンテナを作成
with st.status("ドキュメントを処理しています...", expanded=True) as status:
st.write("1. PDFを読み込んでいます...")
time.sleep(2) # 重い処理のシミュレーション
st.write("読み込み完了")
st.write("2. テキストをチャンキング(分割)しています...")
time.sleep(2)
st.write("分割完了(計 52 チャンク)")
st.write("3. OpenAI Embeddingsでベクトル化しています...")
time.sleep(3)
st.write("ベクトル化完了")
st.write("4. FAISSインデックスを保存しています...")
time.sleep(1)
st.write("保存完了")
# 全ての処理が終わったら、ステータスを更新
status.update(label="処理が完了しました!", state="complete", expanded=False)
st.success("これでRAGの準備が整いました。質問を入力してください。")このコードを実行してみてください。処理が進むごとにチェックマークが増えていき、最後にシュッと折りたまれるアニメーションは、ユーザーに「待つことの納得感」を与えます。
RAGのインデックス作成処理には、まずこの実装を適用することを強く推奨します。
3. 【中級編】UIをブロックしない:Python ThreadingとStreamlit
st.status で見た目は良くなりましたが、処理中は他のボタン(例えば「キャンセル」ボタン)を押すことができません。
UIを完全にノンブロッキングにするには、非同期処理(スレッド化)が必要です。
Python標準の threading モジュールを使いますが、Streamlitでスレッドを使うには一つだけ落とし穴があります。「サブスレッドからは st.write などのStreamlitコマンドが直接使えない」という点です。Streamlitは「どのセッション(ユーザー)への表示か」というコンテキスト情報を管理しており、素のスレッドではその情報が失われるからです。
これを解決するために、add_script_run_ctx という魔法のおまじないを使います。
スレッドを使った非同期処理の実装例
import streamlit as st
import threading
import time
from streamlit.runtime.scriptrunner import add_script_run_ctx
# 重い処理を行う関数(スレッドで実行される)
def heavy_indexing_task(doc_name):
print(f"[{doc_name}] 処理開始")
# ここに実際のRAG処理が入ります
time.sleep(5)
print(f"[{doc_name}] 処理終了")
st.title("バックグラウンド処理のテスト")
doc_name = st.text_input("ドキュメント名", "Manual_v1.pdf")
if st.button("バックグラウンドで処理開始"):
# 1. スレッドの作成
thread = threading.Thread(target=heavy_indexing_task, args=(doc_name,))
# 2. コンテキストの付与(これがないとStreamlit機能がスレッド内で使えない場合がある)
# ※ 今回の例のようにprintするだけなら不要ですが、将来的な拡張のために記述します
add_script_run_ctx(thread)
# 3. スレッド開始
thread.start()
st.info(f"「{doc_name}」の処理をバックグラウンドで開始しました。このまま他の操作が可能です。")
st.write("ここは処理中でも表示されます。")
if st.button("別のボタン"):
st.write("UIはブロックされていません!")注意点:
この実装では、処理は裏で動きますが、「処理が終わったことをUIに通知する」のが難しいという課題が残ります。Streamlitは基本的に「ユーザーのアクションがあった時」にしか画面を更新しないからです。
完了を通知するには、st.empty() などのプレースホルダーを使うか、あるいは処理の完了状態をデータベースやファイルに書き出し、ユーザーが何かしら操作したタイミングで「あ、さっきの処理終わってますよ」と表示する設計にするのが一般的です。
4. 【上級編】プロのアーキテクチャ:Job Queue (Celery/Redis) の概念
ここまでは「Streamlitアプリの中」だけで解決する方法でした。しかし、もし処理が「1時間かかる」ものだったらどうでしょうか?
- ユーザーがブラウザのタブを閉じたら、処理は中断されます。
- HerokuやStreamlit Cloudなどのクラウド環境では、通信がない状態が続くとサーバーが切断(タイムアウト)されることがあります。
これを防ぐためには、「Webアプリ(フロント)」と「重い処理(ワーカー)」を完全に切り離すアーキテクチャが必要です。これを ジョブキュー(Job Queue) 構成と呼びます。
構成図のイメージ
- Streamlit (Producer):
ユーザーから「処理開始」の指示を受け取ると、Redis(メッセージボックスのようなもの)に「この仕事よろしく」とメモ(Job)を入れて、すぐにユーザーに「受け付けました」と返します。 - Redis (Broker):
Jobが溜まっていく場所です。メモリ上で高速に動作するデータベースです。 - Celery Worker (Consumer):
Streamlitとは別のプロセス(あるいは別のサーバー)で動いているワーカープログラムです。Redisを監視しており、Jobが入るとそれを取り出して実行します。処理結果をデータベースに保存します。
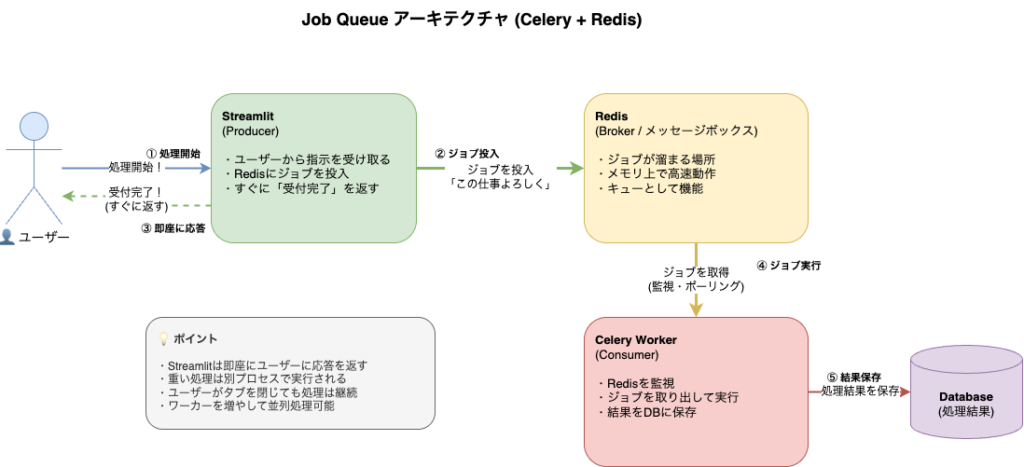
いつJob Queueが必要か?
- 処理時間が30秒を超える場合: 多くのWebサーバーのタイムアウト設定が30〜60秒です。
- ユーザーが待つ必要がない場合: 「後でメールで通知して」というような処理。
- 大量の処理をさばく場合: ワーカーを増やせば並列処理が可能になります。
本連載の範囲(個人開発やプロトタイプ)では st.status で十分ですが、将来的にSaaSとして公開したり、大規模なデータを扱ったりする場合には、「Celery + Redis」 というキーワードを思い出してください。これが「おもちゃのアプリ」と「プロの製品」を分ける壁の一つです。
5. RAGアプリへの実装(実用的な落とし所)
では、本連載のRAGアプリとしては、どの戦略を採用すべきでしょうか?
今回は、最もコストパフォーマンスが良い 「st.status による同期的UX改善」 を採用します。RAGのインデックス作成は、完了しないと次のチャットができないため、ユーザーにとっても「終わるのを見届けたい」処理だからです。
以下は、これまでのRAGアプリに組み込むための、インデックス作成関数のテンプレートです。
import streamlit as st
# 必要なライブラリのインポート...
def create_index_with_ux(uploaded_file):
if not uploaded_file:
return None
# st.statusで処理全体をラップ
with st.status("ドキュメントを知識ベースに変換中...", expanded=True) as status:
# Step 1: ファイル保存とロード
st.write("📂 ファイルを読み込んでいます...")
# (ここに save_uploaded_file などの処理)
# documents = loader.load()
time.sleep(1) # UX調整用のウェイト
# Step 2: チャンキング
st.write(f"{len(documents)} ページをチャンク分割しています...")
# chunks = text_splitter.split_documents(documents)
st.write(f"{len(chunks)} 個のチャンクを作成しました。")
# Step 3: ベクトル化と保存
st.write("AIによるベクトル化を実行中(数分かかる場合があります)...")
# db = FAISS.from_documents(chunks, embeddings)
# db.save_local("faiss_index")
# 完了
status.update(label="インデックス作成完了!", state="complete", expanded=False)
st.success("知識ベースが更新されました。チャットを開始できます。")
return Trueこの関数を、サイドバーのファイルアップローダーの下で呼び出すように設計すれば、ユーザー体験は非常にスムーズになります。
6. まとめと次回予告
今回は、アプリケーション開発の裏側にある「時間」の問題に向き合いました。
- メインスレッドのブロック: 重い処理はUIを固める。
st.status: 処理の中身を見せることで、体感待ち時間を減らす(推奨)。- Threading: UI操作を可能にするが、完了通知などが難しい。
- Job Queue: 本格的な非同期処理にはCelery/Redisが必要。
これで、機能面だけでなく、運用面でも実用的なアプリに近づきました。
さて、いよいよ次回は最終回です。
手元のPCで動いているこの素晴らしいRAGアプリを、世界中の人に使ってもらえるようにWeb上に公開(デプロイ)します。
次回、第10回「最終回:DockerとStreamlit Cloudを使ったデプロイと公開」では、環境依存の問題を解決するコンテナ技術「Docker」の基本と、無料でアプリをホストできる「Streamlit Cloud」へのデプロイ手順を解説します。
最後まで読んでいただきありがとうございます。












コメント