
こんにちは、JS2IIUです。
機械学習モデルの開発が進み、いざデモアプリを構築しようとした際、多くのエンジニアが直面するのが「画面の煩雑さ」です。推論結果だけでなく、入力パラメータの設定、データセットの統計、学習曲線のグラフ、モデルのアーキテクチャ詳細など、ユーザーに見せたい情報は多岐にわたります。これらを1つのページに縦に並べてしまうと、ユーザーは何度もスクロールを強いられ、目的の情報にたどり着くのが難しくなります。
Streamlitは、Pythonだけで素早く直感的なWebアプリを作れる強力なライブラリですが、そのシンプルさゆえに、何も考えずにコードを書くと「1枚の長いページ」になりがちです。
そこで活用したいのが、今回ご紹介する st.tabs 機能です。この機能を使うことで、限られた画面スペースを有効活用し、情報を論理的なグループに分けて整理することができます。本記事では、Streamlitの中級者を目指す皆様に向けて、st.tabs の基本的な使い方から、PyTorchを用いたAIアプリでの実践例、さらには大規模なアプリ開発でもコードを読みやすく保つための「ファイル分割(モジュール化)」のテクニックまで、詳しく丁寧に解説します。今回もよろしくお願いします。
1. st.tabsの基本:シンプルな使い方
st.tabs は、Streamlitのレイアウト機能の中でも非常に人気のあるコンポーネントの1つです。まずは、その基本的な使い方から見ていきましょう。
st.tabs は、タブのタイトル(ラベル)をリスト形式で引数に取り、各タブに対応するコンテナオブジェクトを返します。一般的には、Pythonのアンパック(Unpacking)代入を利用して、各タブを個別の変数として受け取ります。
以下のコードは、3つのタブを作成し、それぞれのタブの中に異なるテキストを表示する最もシンプルな例です。
import streamlit as st
# タイトルの設定
st.title("Streamlit st.tabs 基本デモ")
# 3つのタブを作成
tab1, tab2, tab3 = st.tabs(["概要", "設定", "ヘルプ"])
# 各タブの中身を定義
with tab1:
st.header("概要タブ")
st.write("ここではアプリケーションの全体像を説明します。")
with tab2:
st.header("設定タブ")
st.write("モデルのパラメータやAPIキーの設定を行います。")
with tab3:
st.header("ヘルプタブ")
st.write("使い方がわからない場合はここを参照してください。")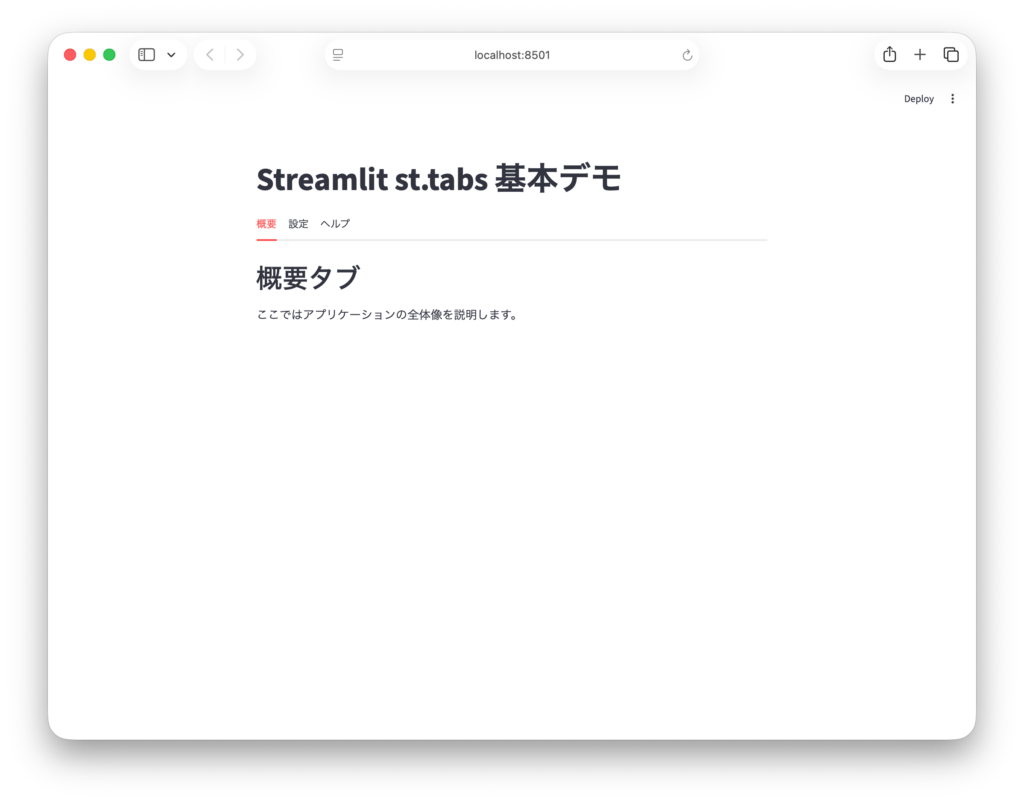
コードの解説:
このコードを実行すると、画面上部に「概要」「設定」「ヘルプ」という3つのタブが表示されます。
重要なのは with tab1: という記述です。これはコンテキストマネージャと呼ばれるPythonの仕組みで、このブロックの中で記述されたStreamlitのコマンド(st.header や st.write など)は、すべてそのタブの中に配置されるようになります。
st.tabs を使うことで、ユーザーは現在興味のある情報だけを選択して表示できるようになり、視覚的なノイズが劇的に減少します。
2. 実践:AIアプリケーションでの活用(PyTorch連携)
次に、より実践的な例として、PyTorchで構築した画像分類モデルのデモアプリを想定してみましょう。
AIモデルのデモでは、「画像をアップロードして結果を見る」というメイン機能の他に、「モデルがどのような構造をしているか」「どのデータセットで学習されたか」といったメタ情報を提示することがよくあります。これらをタブで分けることで、専門的な情報を整理して提示できます。
ここでは、PyTorchの学習済みモデル(ResNet18)を使用して、推論タブとモデル情報タブを作成してみます。
import streamlit as st
import torch
import torchvision.models as models
from torchvision.models import ResNet18_Weights
import torchvision.transforms as transforms
from PIL import Image
# ページ設定
st.set_page_config(page_title="AI画像分類デモ", layout="centered")
# モデルの読み込み(キャッシュを利用して高速化)
@st.cache_resource
def load_model():
# Pre-trainedのResNet18をロード(weights引数を使用)
model = models.resnet18(weights=ResNet18_Weights.DEFAULT)
model.eval()
return model
model = load_model()
# 画像の変換処理
def predict(image, model):
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
output = model(input_batch)
# 簡易的なスコア算出
probabilities = torch.nn.functional.softmax(output[0], dim=0)
return probabilities
# メインUI
st.title("PyTorch ResNet18 画像分類")
# タブの定義
tab_predict, tab_info = st.tabs(["画像推論", "モデル詳細"])
# --- タブ1: 画像推論 ---
with tab_predict:
st.subheader("画像のアップロード")
uploaded_file = st.file_uploader("分類したい画像を選択してください", type=["jpg", "jpeg", "png"])
if uploaded_file is not None:
image = Image.open(uploaded_file).convert('RGB')
st.image(image, caption='アップロードされた画像', width='stretch')
if st.button("分類実行"):
with st.spinner('計算中...'):
probs = predict(image, model)
top_prob, top_catid = torch.topk(probs, 1)
st.success(f"結果: クラスID {top_catid[0].item()} (確信度: {top_prob[0].item():.2f})")
st.info("※このIDはImageNetのクラスIDに対応しています。")
# --- タブ2: モデル詳細 ---
with tab_info:
st.subheader("ネットワーク構成")
st.write("このデモでは、PyTorchのtorchvisionで提供されている学習済みのResNet18モデルを使用しています。")
# モデルの構造をテキストで表示
with st.expander("レイヤー構造を表示"):
st.code(str(model))
st.subheader("パラメータ数")
total_params = sum(p.numel() for p in model.parameters())
st.metric("Total Parameters", f"{total_params:,}")コードの解説:
- モデルのキャッシュ化 (
@st.cache_resource): Streamlitはコードが上から下まで再実行される性質を持っています。タブを切り替えるたびに巨大なAIモデルをロードし直すと、アプリの反応が極めて悪くなります。これを防ぐために、モデルのロード部分は必ずキャッシュするようにしましょう。 - タブによる関心の分離:
tab_predictでは推論というユーザー体験に集中し、tab_infoでは開発者向け・技術解説向けの情報をまとめています。 - インタラクティブな要素: タブ内でも
st.buttonやst.file_uploaderは通常通り動作します。
このように st.tabs を使うことで、1つのURLで「アプリ」と「ドキュメント」を共存させるような、洗練されたインターフェースが実現できます。
3. メンテナンス性を高める:各タブの処理を別ファイルへ分割する
アプリの規模が大きくなってくると、メインの app.py ファイルが数千行に膨れ上がり、どこに何が書いてあるか分からなくなってしまいます。特にタブごとに複雑なデータ可視化や前処理が含まれる場合、コードの可読性は急速に低下します。
そこで、各タブの中身を関数化し、別のファイルに切り出す「モジュール化」の手法を導入しましょう。
おすすめのディレクトリ構成
my_ai_app/
├── app.py # メインの実行ファイル
├── tabs/ # 各タブの処理を格納するフォルダ
│ ├── __init__.py
│ ├── inference.py
│ └── analysis.py
└── utils.py # 共通のユーティリティ(モデルロード等)各ファイルの記述例
まず、推論タブの処理を tabs/inference.py に記述します。
# tabs/inference.py
import streamlit as st
from PIL import Image
def render_inference_tab(model, predict_fn):
st.subheader("画像推論")
uploaded_file = st.file_uploader("画像をアップロード", type=["jpg", "png"])
if uploaded_file:
image = Image.open(uploaded_file).convert('RGB')
st.image(image, use_container_width=True)
if st.button("実行"):
result = predict_fn(image, model)
st.write(result)次に、メインの app.py でこれらを呼び出します。
# app.py
import streamlit as st
from tabs.inference import render_inference_tab
from tabs.analysis import render_analysis_tab # 別途作成
from utils import load_model, predict # 共通処理
model = load_model()
st.title("モジュール化されたStreamlitアプリ")
# タブの作成
tab1, tab2 = st.tabs(["推論実行", "データ分析"])
with tab1:
# 外部ファイルの関数を呼び出し、必要な引数(モデルなど)を渡す
render_inference_tab(model, predict)
with tab2:
render_analysis_tab()この手法のメリット:
- 可読性向上:
app.pyが非常にスッキリし、アプリ全体の構造が一目で分かります。 - 共同開発のしやすさ: Aさんは推論タブ、Bさんは分析タブ、といった具合に分担して作業しやすくなります。
- デバッグの容易さ: エラーが発生した際、どのファイルに原因があるか特定しやすくなります。
中級以上の開発者であれば、このように st.tabs と関数の分割を組み合わせることで、プロフェッショナルなコードベースを維持することができます。
4. 応用:st.tabsを利用する際の注意点とTips
st.tabs を使いこなすために、いくつか知っておくべき重要な仕様があります。
1. すべてのタブが「同時に」レンダリングされる
ここが最も重要なポイントです。Streamlitの st.tabs は、現在表示されていないタブのコードも、裏側ですべて実行します。例えば、「タブ2」に非常に重い計算処理やデータの読み込みを記述している場合、ユーザーが「タブ1」を見ている間もその計算が実行され、アプリ全体の動作が重くなる原因になります。
対策:
- 重い計算には必ず
st.cache_dataやst.cache_resourceを使用する。 - どうしても選択された時だけ実行したい場合は、
st.tabsではなくst.selectboxやst.sidebar.radioを使って、条件分岐(if文)で表示を切り替える手法(条件付きレンダリング)を検討してください。
2. ネスト(入れ子)の制限
公式ドキュメントにある通り、st.tabs の中にさらに st.tabs を入れる(ネストする)ことは可能ですが、UIデザインの観点からはあまり推奨されません。
階層が深すぎると、ユーザーは今自分がどこの階層にいるのか混乱してしまいます。「サイドバーで大項目を選び、メイン画面のタブで小項目を選ぶ」といった、Streamlitの他のレイアウト要素との組み合わせを優先しましょう。
3. 動的なタブ生成
タブの数は固定である必要はありません。例えば、アップロードされた複数の画像ごとにタブを自動生成することも可能です。
images = st.file_uploader("複数画像を選択", accept_multiple_files=True)
if images:
# 画像の数だけタブを作成
tabs = st.tabs([f"画像 {i+1}" for i in range(len(images))])
for i, tab in enumerate(tabs):
with tab:
st.image(images[i])リスト内包表記を使ってタブのリストを動的に生成し、for ループで各タブの中身を埋めていく手法は、データ分析ツールなどを作る際に非常に便利です。
5. まとめ
本記事では、Streamlitの st.tabs 機能について、基本的な構文から、PyTorchを用いた実践的なAIデモの実装、そしてコードのメンテナンス性を高めるためのファイル分割手法まで解説しました。
st.tabs は単なる見た目の調整機能ではありません。ユーザーに情報の優先順位を提示し、複雑なAIアプリケーションを「使いやすいツール」へと昇華させるための重要な要素です。
今回ご紹介したテクニックを自身のプロジェクトに取り入れ、ぜひ「使いやすく、かつコードも美しい」Streamlitアプリを構築してみてください。最初は1つのファイルで書き始めても構いませんが、機能が増えてきたら「タブごとにファイルを分ける」というステップを思い出すことが、テックブログの読者である中級者の皆様にとって、次なる成長への鍵となるはずです。
より詳細な仕様については、Streamlit公式ドキュメントのst.tabsリファレンスも併せて参照してください。あなたのAI開発が、より洗練されたものになることを応援しています。
最後まで読んでいただきありがとうございます。


コメント