
こんにちは、JS2IIUです。
現代のAIアプリケーション開発において、ユーザーがいかに直感的にAIと対話できるかは、そのアプリケーションの価値を左右する極めて重要な要素です。これまで、LLM(大規模言語モデル)との対話はテキスト入力が主流でしたが、最近ではマルチモーダルな入力への需要が急速に高まっています。
そのような中、Pythonで手軽にデータアプリを構築できるフレームワーク「Streamlit」が、バージョン1.52.0において画期的なアップデートを発表しました。チャットUIの中核を担う st.chat_input に、待望の「音声入力機能」が標準搭載されたのです。
本記事では、テックブログのベテランライターとして、この新機能の使い方を徹底解説します。単なる使い方の紹介に留まらず、取得した音声データをPyTorchベースのAIモデルで処理し、実際の音声対話システムへと昇華させる実践的なプロセスまでを詳しくガイドします。
1. 準備:Streamlitのアップデート
まず最初に、今回紹介する機能を利用するために、お手元のStreamlit環境を最新バージョンへアップデートする必要があります。音声入力機能はバージョン1.52.0以降で利用可能です。
以下のコマンドをターミナルで実行して、パッケージを更新してください。
# pipを使用してStreamlitを最新バージョンにアップグレード
pip install --upgrade streamlitアップデートが完了したら、正しく反映されているかを確認しましょう。
# バージョンの確認
streamlit --version出力結果が Streamlit, version 1.52.0 以上であれば準備完了です。もし古いバージョンのまま実行すると、今回解説する新しい引数が認識されずエラーとなってしまうため、必ずこのステップを確認してください。
2. st.chat_inputの基本をおさらい
新機能の詳細に入る前に、まずは st.chat_input の基本的な役割を復習しておきましょう。この関数は、画面下部に固定されたチャット入力欄を表示するためのものです。
もっともシンプルな実装は以下のようになります。
import streamlit as st
# チャット入力欄の作成
prompt = st.chat_input("メッセージを入力してください")
# 入力があった場合の処理
if prompt:
# ユーザーの入力を画面に表示
with st.chat_message("user"):
st.write(prompt)
このコードでは、ユーザーがテキストを入力して送信すると、prompt 変数に文字列が格納され、画面にメッセージとして表示されます。これまでは「文字列」のみを扱うコンポーネントでしたが、今回のアップデートにより、この一つの入力欄で「音声」も同時に扱えるようになりました。
3. 新機能:音声入力オプションの詳細解説
Streamlit 1.52.0では、st.chat_input に新しく accept_audio と audio_sample_rate という2つのオプションが追加されました。
accept_audio パラメータ
これを True に設定すると、入力欄の右側にマイクアイコンが表示されます。ユーザーはこのアイコンをクリック(または長押し)することで、ブラウザ経由で音声を録音できるようになります。
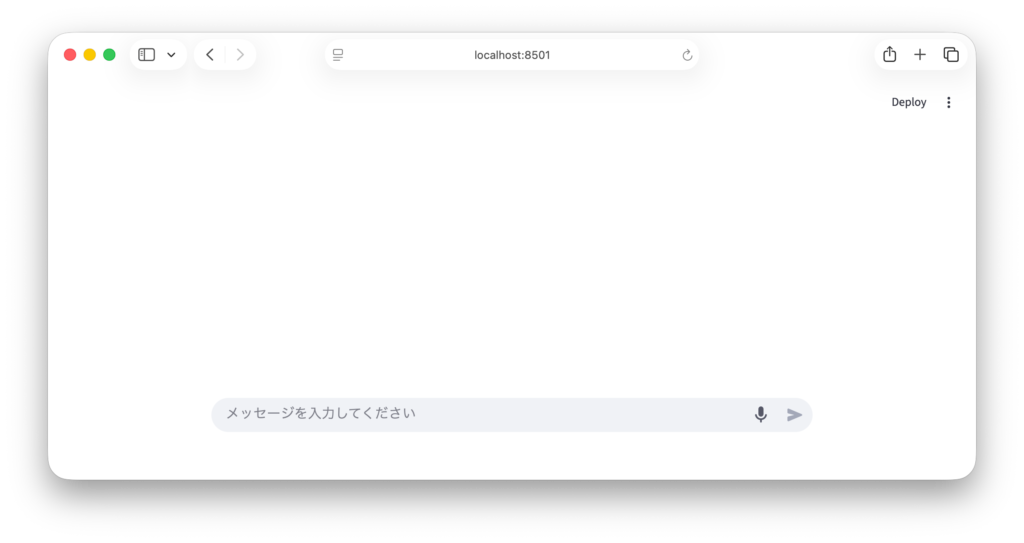
audio_sample_rate パラメータ
録音される音声のサンプリングレート(Hz)を指定します。デフォルトでは、ブラウザやOSの設定に依存しますが、後続のAIモデル(Whisperなど)で処理する場合、モデルが要求するレート(例:16,000Hz)に合わせることで、変換エラーや精度の低下を防ぐことができます。指定しなければデフォルトで16,000Hzがセットされます。
戻り値の変化
ここが最も重要なポイントです。accept_audio=True を設定した場合、st.chat_input の戻り値は単なる文字列ではなく、辞書のような振る舞いをするオブジェクト(ChatInputValue)になります。
prompt.text: 入力されたテキスト(テキスト入力があった場合)prompt.audio: 録音された音声データ(バイト列、音声入力があった場合)
これにより、テキストと音声をシームレスに一つのロジックで受け取ることが可能になります。
4. 実践:音声入力対応チャットアプリの実装
それでは、実際に音声入力機能を活用したコードを書いてみましょう。ここでは、録音された音声を、PyTorchで動作するOpenAIの「Whisper」モデルを使用してテキストに変換(Speech-to-Text)する例を紹介します。
このサンプルでは、ライブラリとして openai-whisper と、音声波形処理のための numpy を使用します。事前に pip install openai-whisper numpy でインストールしておいてください。
import streamlit as st
import whisper
import torch
import numpy as np
import io
import wave
# AIモデルのキャッシュ(起動のたびに読み込むのを防ぐ)
@st.cache_resource
def load_whisper_model():
# PyTorchで動作するWhisperモデルをロード
# "base"は軽量でCPUでも動作しやすいモデルです
return whisper.load_model("base")
model = load_whisper_model()
st.title("音声対応AIチャットボット")
st.write("マイクアイコンを押して話しかけてみてください。")
# セッション状態での履歴保持
if "messages" not in st.session_state:
st.session_state.messages = []
# 履歴の表示
for msg in st.session_state.messages:
with st.chat_message(msg["role"]):
st.markdown(msg["content"])
# --- st.chat_input の新機能を活用した入力セクション ---
# accept_audio=True にすることでマイク入力を有効化
# 16000HzはWhisperモデルの標準的なサンプリングレートです
user_input = st.chat_input("メッセージを入力するか、音声を録音してください",
accept_audio=True,
audio_sample_rate=16000)
if user_input:
# ユーザー入力を保持する変数
final_text = ""
# 1. 音声入力があった場合の処理
if user_input.audio:
with st.status("音声を解析中..."):
# user_input.audioはUploadedFile型なので、.read()でバイトデータを取得
audio_bytes = user_input.audio.read()
# bytesデータを一度メモリ上のバイナリファイルとして扱う
audio_file = io.BytesIO(audio_bytes)
# Waveファイルとして読み込み、float32のnumpy配列に変換
with wave.open(audio_file, 'rb') as wf:
# フレームの読み込み
frames = wf.readframes(wf.getnframes())
# int16からfloat32へ正規化(Whisperの期待する形式)
audio_np = np.frombuffer(frames, dtype=np.int16).astype(np.float32) / 32768.0
# Whisperで文字起こしを実行(日本語を明示指定)
result = model.transcribe(audio_np, fp16=torch.cuda.is_available(), language="ja")
final_text = result["text"]
st.write(f"音声認識結果: {final_text}")
# 2. テキスト入力があった場合の処理(音声がなければこちら)
elif user_input.text:
final_text = user_input.text
# 3. 解析または入力されたテキストを元にチャット処理
if final_text:
# ユーザーのメッセージを履歴に追加・表示
st.session_state.messages.append({"role": "user", "content": final_text})
with st.chat_message("user"):
st.markdown(final_text)
# AIの応答(ここでは簡単なエコーですが、ここでLLMを呼び出せます)
response_text = f"「{final_text}」と仰いましたね。音声入力機能はいかがですか?"
with st.chat_message("assistant"):
st.markdown(response_text)
st.session_state.messages.append({"role": "assistant", "content": response_text})コードのポイント解説
このコードの肝は、st.chat_input から返される user_input.audio の扱いです。このデータは生のバイト列(WAV形式のバイナリ)として提供されます。AIモデル、特にPyTorchベースの音声認識モデルで処理する場合、このバイト列をそのまま渡すことはできません。
io.BytesIO(audio_bytes)を使い、メモリ上でファイルのように扱います。waveモジュールでサンプリングデータを取り出します。np.frombufferで数値配列(numpy array)に変換し、さらに-1.0から1.0の範囲の浮動小数点数(float32)に正規化します。これが多くのディープラーニングモデルで共通の入力形式です。
このように、Streamlitの新機能は「データの取得」を極限までシンプルにし、エンジニアが「データの解析と応用」に集中できる環境を提供してくれます。
5. 応用:実用的なAIエージェントへの統合
音声入力機能が加わったことで、Streamlitアプリの用途は大きく広がります。例えば、以下のような応用が考えられます。
- アクセシビリティの向上: キーボード入力が困難な状況や、身体的な制約があるユーザーにとって、音声入力は不可欠なインターフェースとなります。
- 現場作業用ツール: 両手が塞がっている製造現場や医療現場で、音声によって報告書を作成したり、AIに指示を出したりするツールが、Streamlitだけで完結して構築可能です。
- 多言語翻訳機: 音声入力を受け取り、Whisperでテキスト化し、さらにLLMで翻訳して、別の音声合成(TTS)モデルで出力する。そんな本格的な翻訳アプリも、数十行のコードで実現できます。
実装時の注意点として、音声データはテキストデータに比べてサイズが大きいため、ネットワーク環境やサーバーのメモリ負荷に配慮する必要があります。audio_sample_rate を必要最小限に抑える、あるいは長時間録音を制限するようなUI側の工夫を併用すると、よりプロフェッショナルな仕上がりになります。
6. まとめと今後の展望
Streamlitの st.chat_input への音声入力機能の追加は、Pythonエンジニアにとって「AIとの対話」をデザインする上での大きな武器となりました。従来、音声録音のためのJavaScriptカスタムコンポーネントを自作したり、複雑な外部ライブラリを組み合わせたりしていた苦労が、わずか一行の引数追加で解決されるようになったのです。
本記事では、1.52.0へのアップデート方法から、accept_audio オプションの具体的な使い方、そしてPyTorchを用いた音声解析の実装までを解説しました。
AI技術は日々進化していますが、その技術をいかにしてユーザーに届けるかという「ラストワンマイル」の重要性は変わりません。ぜひ、この新機能を皆さんのプロジェクトに取り入れ、より自然で、より人間味のあるAIアプリケーションを構築してみてください。
最後まで読んでいただきありがとうございます。


コメント