
こんにちは、JS2IIUです。
Streamlitと機械学習やデータ分析はとても相性の良い組み合わせです。学習済みモデルを読み込み、ユーザー入力に基づいて予測結果を表示するアプリを作っていきます。今回もよろしくお願いします。
1. はじめに
機械学習のモデルを作ったけれど、「もっと簡単に人に使ってもらえたらいいのに」と思ったことはありませんか?
そんなときに便利なのが Streamlit(ストリームリット) です。
Streamlitは、PythonのコードだけでWebアプリを作れるフレームワークです。とても簡単に、機械学習モデルをWebアプリ化して公開することができます。
この記事では、次のようなアプリを一緒に作っていきます:
- ユーザーが入力したデータをもとに
- 学習済みモデルで予測し
- 結果をWeb画面に表示
2. 必要な準備
2.1 使用するライブラリのインストール
まずは必要なPythonライブラリをインストールしましょう。以下のコマンドをターミナルまたはコマンドプロンプトに入力してください。
pip install streamlit scikit-learn pandas numpy joblib2.2 モデルの準備
今回は scikit-learn に含まれている「Iris(アヤメ)データセット」を使って分類モデルを作り、学習済みモデルとして保存します。
以下のコードを train_model.py というファイルに保存して、実行してください。
# train_model.py
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import joblib
# データの読み込み
iris = load_iris()
X = iris.data
y = iris.target
# モデルの作成と学習
model = RandomForestClassifier()
model.fit(X, y)
# モデルの保存
joblib.dump(model, 'iris_model.pkl')実行後、iris_model.pkl というファイルが作成されます。これがWebアプリで使う「学習済みモデル」です。joblib.dump()についてはこちらを参考にしてください。
joblib.dump — joblib 1.5.dev0 documentation
3. Streamlit アプリを作成する
次に、Streamlitアプリのコードを app.py という名前で作成します。
3.1 アプリの構成イメージ
- ユーザーが花の特徴(長さや幅)を入力
- モデルで予測
- 結果(アヤメの種類)を画面に表示
では順を追って作っていきましょう!
3.2 ステップ①:ライブラリのインポートとモデルの読み込み
# app.py
import streamlit as st
import pandas as pd
import numpy as np
import joblib次に、保存したモデルを読み込みます。
# 学習済みモデルの読み込み
model = joblib.load('iris_model.pkl')3.3 ステップ②:画面のタイトルや説明
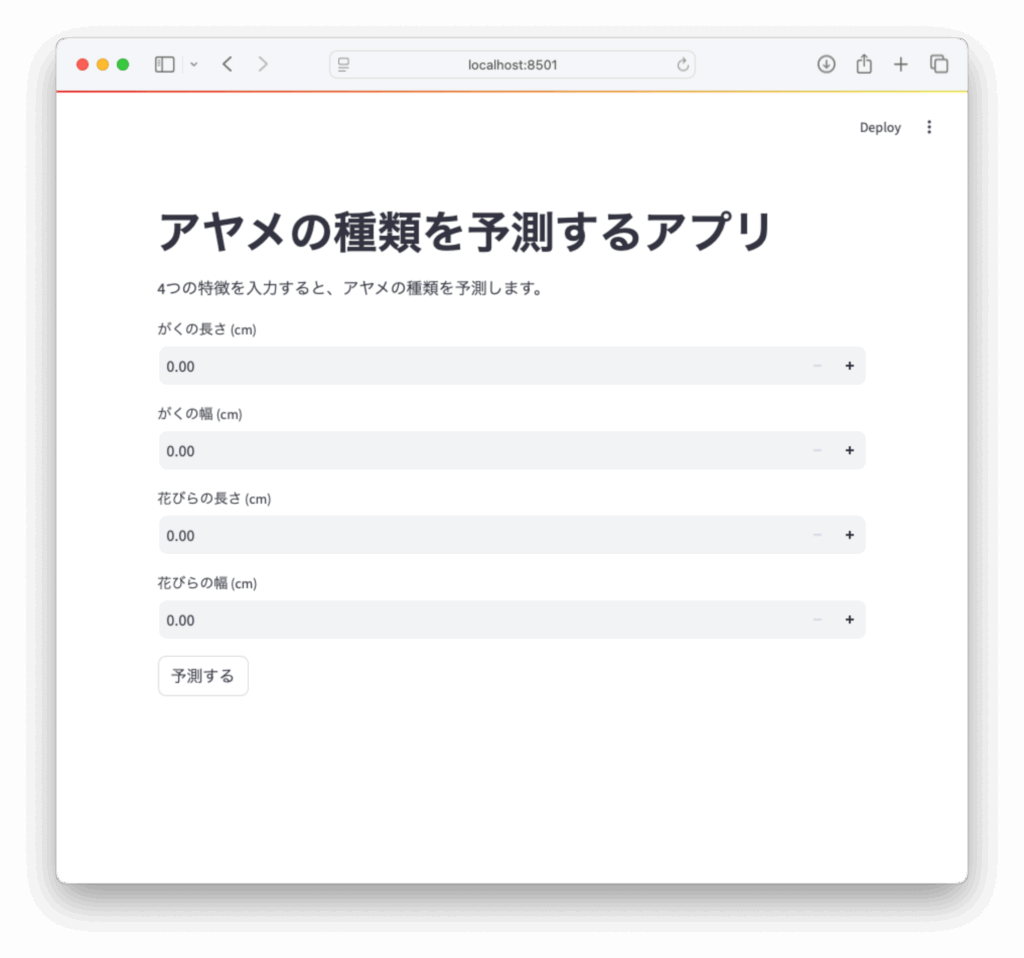
st.title('アヤメの種類を予測するアプリ')
st.write('4つの特徴を入力すると、アヤメの種類を予測します。')3.4 ステップ③:ユーザー入力フォームを作る
Streamlitの number_input を使って、花の特徴を入力するフォームを作ります。
sepal_length = st.number_input('がくの長さ (cm)', min_value=0.0, max_value=10.0, step=0.1)
sepal_width = st.number_input('がくの幅 (cm)', min_value=0.0, max_value=10.0, step=0.1)
petal_length = st.number_input('花びらの長さ (cm)', min_value=0.0, max_value=10.0, step=0.1)
petal_width = st.number_input('花びらの幅 (cm)', min_value=0.0, max_value=10.0, step=0.1)3.5 ステップ④:予測ボタンと結果表示
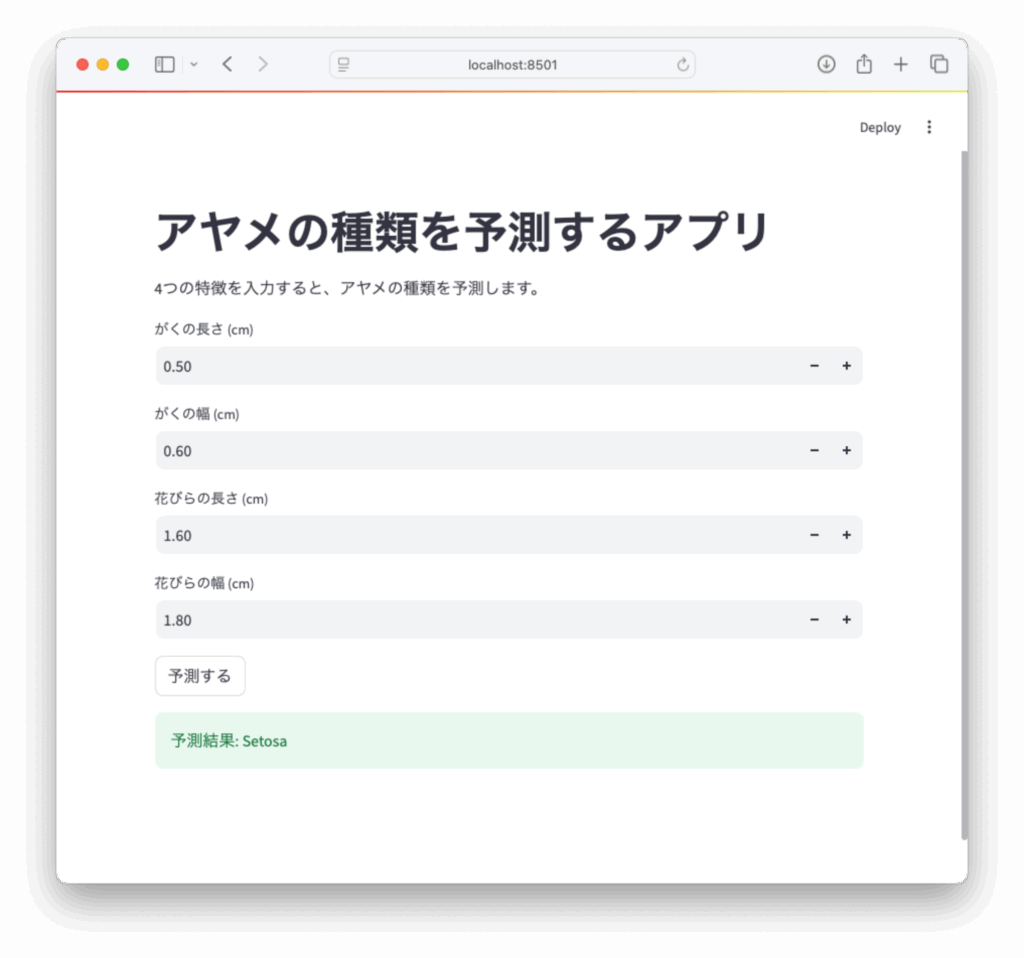
予測は「予測する」ボタンが押されたときだけ実行されるようにします。
if st.button('予測する'):
input_data = np.array([[sepal_length, sepal_width, petal_length, petal_width]])
prediction = model.predict(input_data)
predicted_class = prediction[0]
class_names = ['Setosa', 'Versicolor', 'Virginica']
st.success(f'予測結果: {class_names[predicted_class]}')3.6 アプリ全体のコード
# app.py
import streamlit as st
import pandas as pd
import numpy as np
import joblib
# モデルの読み込み
model = joblib.load('iris_model.pkl')
# タイトルと説明
st.title('アヤメの種類を予測するアプリ')
st.write('4つの特徴を入力すると、アヤメの種類を予測します。')
# 入力フォーム
sepal_length = st.number_input('がくの長さ (cm)', 0.0, 10.0, step=0.1)
sepal_width = st.number_input('がくの幅 (cm)', 0.0, 10.0, step=0.1)
petal_length = st.number_input('花びらの長さ (cm)', 0.0, 10.0, step=0.1)
petal_width = st.number_input('花びらの幅 (cm)', 0.0, 10.0, step=0.1)
# 予測処理
if st.button('予測する'):
input_data = np.array([[sepal_length, sepal_width, petal_length, petal_width]])
prediction = model.predict(input_data)
predicted_class = prediction[0]
class_names = ['Setosa', 'Versicolor', 'Virginica']
st.success(f'予測結果: {class_names[predicted_class]}')4. アプリの実行方法
ターミナルで以下のコマンドを実行してください。
streamlit run app.py
実行すると、自動的にブラウザが開き、アプリが表示されます。
表示されない場合は、出力されたURL(通常は http://localhost:8501)にアクセスしてください。
5. 応用アイデア:より便利なアプリにするには?
ここまでの内容に加えて、以下のような機能を追加すればさらに便利になります:
- 入力フォームを
st.formでまとめる st.columnsを使って横並びに整理predict_proba()を使って予測の確信度を棒グラフで表示- 複数のモデルから選択できる機能の追加
6. まとめ
今回は、以下のステップで学習済み機械学習モデルをStreamlitでWebアプリ化しました:
- モデルを作って保存する(
joblib.dump) - Streamlitでユーザー入力フォームを作る
- 入力に応じてモデルで予測し、結果を表示する
Streamlitを使えば、たった数十行のコードで誰でも簡単に予測アプリを作ることができます。
まずはローカルで試してみて、慣れてきたらStreamlit CloudやHerokuでの公開にも挑戦してみましょう!
7. 参考リンク
当ブログのStreamlit関連記事一覧です。こちらも参考にしていただけますと幸いです。ぜひご覧ください。

最後に書籍のPRです。
24年11月に第3版が発行された「scikit-learn、Keras、TensorFlowによる実践機械学習 第3版」、Aurélien Géron 著。下田、牧、長尾訳。機械学習のトピックスについて手を動かしながら網羅的に学べる書籍です。ぜひ手に取ってみてください。
最後まで読んでいただきありがとうございます。


コメント