
こんにちは、JS2IIUです。
今回はクラスタリングについて手法をおさらいしつつ、Streamlit上でクラスタリング結果の表示を行うアプリを作っていきます。今回もよろしくお願いします。
1. はじめに
この記事では、機械学習の「クラスタリング」という手法について学び、実際にその結果をStreamlitというツールを使ってインタラクティブに表示するアプリを作っていきます。
クラスタリングとは「データを似たもの同士でグループ分けする方法」で、例えば「お客様を行動パターンで分類する」など、さまざまな場面で利用されています。
今回はその中でも代表的な「K-means法」というクラスタリング手法を取り上げ、以下の内容を順を追ってみていきます。
- クラスタリングの基礎
- K-means法の考え方と仕組み
- PythonによるK-meansの実装
- Streamlitでの可視化アプリ作成
2. クラスタリングとは?
● 教師なし学習の一種
クラスタリングは「教師なし学習」に分類される機械学習手法の一つです。教師なしとは、「答え(正解ラベル)」が与えられていないデータに対して、自動的にパターンを見つけるという意味です。
● どんな場面で使われるの?
- お客様の購買履歴からグループ分け(マーケティング)
- 画像の類似度で分類(画像処理)
- Webサイトの利用パターンからユーザーをセグメント
● 分類との違い
| 種類 | 特徴 |
|---|---|
| 分類 | あらかじめ正解ラベルがある |
| クラスタリング | 正解ラベルがなく、似たデータを自動で分ける |
3. K-means法の基礎知識
K-means(ケイ・ミーンズ)法は、クラスタリングの中でも非常に有名でよく使われるアルゴリズムです。
● ざっくり流れ
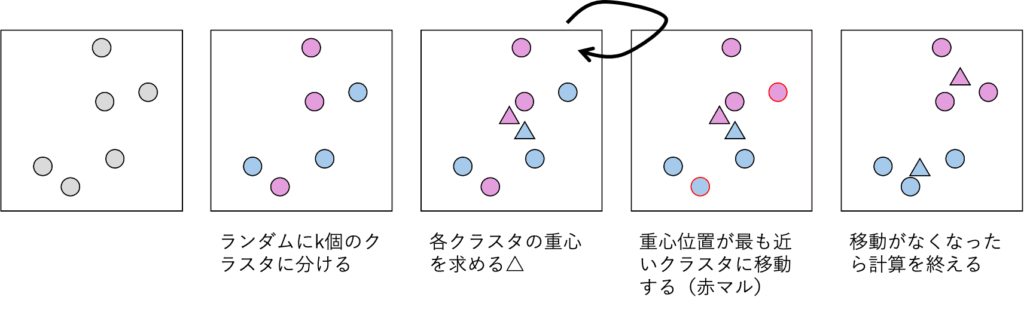
- クラスタ数 k を決める
- k個の重心(中心点) をランダムに決定
- 各データ点を最も近い重心に割り当てる
- 重心を更新(割り当てられたデータの平均を取る)
- 収束するまで繰り返す
図で見ると、以下のようなイメージです:
データ点 → クラスタに割り当て → 重心更新 → 再割り当て → ...
● メリット・デメリット
メリット
- 実装が簡単で高速
- 分かりやすい結果が得られる
デメリット
- 初期重心の選び方に影響されやすい
- クラスタ数 k の選び方が難しい
4. PythonでK-meansクラスタリングを実装してみよう
ここからは実際にコードを書いていきます。
📦 必要なライブラリをインストール
以下のコマンドをターミナルで実行して、必要なライブラリをインストールしてください。
pip install scikit-learn streamlit matplotlib seaborn🐍 サンプルデータの作成
scikit-learn にある make_blobs を使って、クラスタリングしやすいサンプルデータを作成します。
from sklearn.datasets import make_blobs
import pandas as pd
# 300個の2次元データ、クラスタ数3で生成
X, _ = make_blobs(n_samples=300, centers=3, random_state=42)
# DataFrameに変換
df = pd.DataFrame(X, columns=["x", "y"])変数のdfには以下の様な値が入ります。
x y
0 -7.338988 -7.729954
1 -7.740041 -7.264665
2 -1.686653 7.793442
3 4.422198 3.071947
4 -8.917752 -7.888196
.. ... ...
295 -3.660191 9.389984
296 3.810884 1.412989
297 -4.116681 9.198920
298 -6.861209 -5.203672
299 -6.010021 -5.524472
[300 rows x 2 columns]🔍 K-meansによるクラスタリング
from sklearn.cluster import KMeans
# クラスタ数を3に設定して学習
kmeans = KMeans(n_clusters=3, random_state=42)
df["cluster"] = kmeans.fit_predict(df[["x", "y"]])K-Means法を適用した後は変数のdfに新しいカラムが生成されています。
x y cluster
0 -7.338988 -7.729954 1
1 -7.740041 -7.264665 1
2 -1.686653 7.793442 0
3 4.422198 3.071947 2
4 -8.917752 -7.888196 1
.. ... ... ...
295 -3.660191 9.389984 0
296 3.810884 1.412989 2
297 -4.116681 9.198920 0
298 -6.861209 -5.203672 1
299 -6.010021 -5.524472 1
[300 rows x 3 columns]🎨 クラスタリング結果の表示(matplotlib使用)
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 6))
for cluster_id in df["cluster"].unique():
cluster_data = df[df["cluster"] == cluster_id]
plt.scatter(cluster_data["x"], cluster_data["y"], label=f"Cluster {cluster_id}")
plt.title("K-means Clustering Result")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.show()
5. Streamlitでインタラクティブな可視化アプリを作成
Streamlitを使えば、上記の処理をWebアプリのような形で操作・表示できます。
🏗️ アプリの構成
- サイドバーでクラスタ数を選ぶ
- 実行ボタンでクラスタリングを開始
- 結果を散布図で表示(クラスタごとに色分け)
💡 コード全体(streamlit_app.py)
import streamlit as st
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
# タイトル
st.title("🔍 K-meansクラスタリング 可視化アプリ")
# クラスタ数をサイドバーで選択
k = st.sidebar.slider("クラスタ数 (k)", min_value=1, max_value=10, value=3, step=1)
# サンプルデータ作成
X, _ = make_blobs(n_samples=300, centers=k, random_state=42)
df = pd.DataFrame(X, columns=["x", "y"])
# クラスタリング実行
kmeans = KMeans(n_clusters=k, random_state=42)
df["cluster"] = kmeans.fit_predict(df[["x", "y"]])
# グラフ描画
fig, ax = plt.subplots()
for cluster_id in df["cluster"].unique():
cluster_data = df[df["cluster"] == cluster_id]
ax.scatter(cluster_data["x"], cluster_data["y"], label=f"Cluster {cluster_id}")
ax.set_title("クラスタリング結果")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend()
# 結果表示
st.pyplot(fig)
▶️ アプリの実行方法
ターミナルで以下を実行します:
streamlit run streamlit_app.pyブラウザが開いて、クラスタ数を変更するとグラフが動的に変わるインタラクティブなアプリになります!
6. アプリの拡張アイデア
- クラスタリング手法を選択できるようにする
- 例:DBSCAN、階層クラスタリングなど
- ファイルアップロード機能
- 自分のCSVデータでクラスタリングが可能に
- 特徴量の選択UI
- 2次元以外のデータにも対応しやすくなる
7. まとめ
本記事では、以下のステップでクラスタリングとその可視化を学びました。
- クラスタリングの考え方と分類との違い
- K-means法の基本的な流れと仕組み
- PythonでK-meansを実装し、matplotlibで可視化
- Streamlitでインタラクティブなアプリに仕上げる方法
K-meansとStreamlitは、どちらも扱いやすく学習に最適なツールです。ぜひ色々なデータで試して、理解を深めてみてください。
8. 参考リンク
最後に書籍のPRです。
24年11月に第3版が発行された「scikit-learn、Keras、TensorFlowによる実践機械学習 第3版」、Aurélien Géron 著。下田、牧、長尾訳。機械学習のトピックスについて手を動かしながら網羅的に学べる書籍です。ぜひ手に取ってみてください。
最後まで読んでいただきありがとうございます。


コメント