
こんにちは、JS2IIUです。
データをSeriesに読み込んだ後、最初に行うのが要素数のカウントです。いくつかの異なるカウント方法を紹介します。Seriesを使うすべての方に向けての記事です。今回もよろしくお願いします。
.size | 全要素数 |
.shape | データ形状(行, 列) |
len()関数 | 全要素数 |
.count() | 非欠損値の数 |
はじめに
Pandasは、Pythonでデータ処理を行う際に非常に便利なライブラリです。その基本構造であるSeriesは、インデックス付きの1次元データ構造で、リストや配列に似た動作を持ちます。データ処理の基本操作として、「要素数」を確認するのは重要です。特に欠損値を含むデータの場合、全ての要素数や有効な値の数を区別する必要があります。
この記事では、Seriesの要素数を取得するための4つの方法を解説します。また、「欠損値」とは何かについても詳しく触れます。具体的には以下の内容を扱います。
.size(全要素数).shape(データの形状を利用して要素数を取得)len()関数(全要素数).count()(非欠損値の数)
欠損値(NaN)とは?
データ処理では、値が欠落している部分を「欠損値」と呼びます。欠損値は以下のような場面で発生します。
- データ収集時の不完全さ
センサーの不具合や調査項目の回答漏れなどにより、値が記録されないことがあります。 - データ変換時の不一致
型変換や結合操作の結果として、値が失われることがあります。 - 意図的な置き換え
分析のために不適切な値を欠損値として扱うことがあります。
Pandasでは、NaN(Not a Number)が欠損値を表す標準的な記号として使われます。また、PythonのNoneもPandasでは欠損値として扱われる場合があります。
Series特有のカウント方法
Pandasでは、Seriesの要素数を取得するために以下の4つの方法が利用可能です。
1. .size
- 概要:
Series全体の要素数を返します。 - 特長: 欠損値を含めた全ての要素数をカウントします。
2. .shape
- 概要:
Seriesの形状を表すタプルを返します。shape[0]で要素数を取得可能です。 - 特長:
.sizeと同様に、欠損値を含む全ての要素数を取得します。
3. len()
- 概要:
Series全体の要素数を返します。 - 特長: 欠損値を含む全ての要素数をカウントします。
4. .count()
- 概要: 非欠損値(
NaNでない値)のみをカウントします。 - 特長: 有効なデータ数を取得する際に便利です。
サンプルコード
以下のコードは、各メソッドや関数を使用してSeriesの要素数を取得する例です。
import pandas as pd
import numpy as np
# サンプルデータを作成
data = pd.Series([10, 20, 30, np.nan, 50, None, 70])
# .size を使用して全要素数を取得
total_size = data.size
# .shape を使用して全要素数を取得
total_shape = data.shape[0]
# len() を使用して全要素数を取得
total_len = len(data)
# .count() を使用して非欠損値の数を取得
non_nan_count = data.count()
# 結果を表示
print("Series 全体:")
print(data)
print("\n.size で取得した全要素数:", total_size)
print(".shape で取得した全要素数:", total_shape)
print("len() で取得した全要素数:", total_len)
print(".count() で取得した非欠損値の数:", non_nan_count)
コードの解説
サンプルデータの作成
pd.Seriesを使用して、整数値と欠損値(NaNやNone)を含むデータを作成します。- 欠損値は、
np.nanまたはNoneとして定義されます。
.sizeの使用
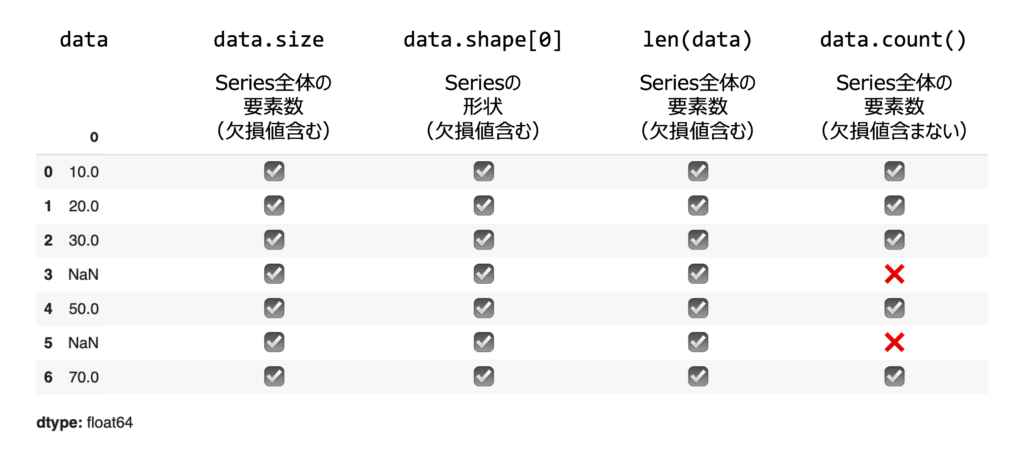
.sizeは欠損値を含む全ての要素数を返します。- このデータの場合、要素数は7になります。
.shapeの使用
.shapeはタプル形式でデータの形状を返します。Seriesは1次元なので、shape[0]が要素数を示します。
len()の使用
len(data)は.sizeと同様に欠損値を含む全要素数を返します。
.count()の使用
.count()は欠損値を無視して、非欠損値(有効な値)の数を返します。- この場合、欠損値が2つあるため、結果は5になります。
実行結果
上記コードを実行すると、以下のような結果が得られます。
Series 全体:
0 10.0
1 20.0
2 30.0
3 NaN
4 50.0
5 NaN
6 70.0
dtype: float64
.size で取得した全要素数: 7
.shape で取得した全要素数: 7
len() で取得した全要素数: 7
.count() で取得した非欠損値の数: 5
まとめ
- 全要素数を取得する方法
.size,.shape[0],len()は、欠損値を含む全ての要素数を取得します。 - 非欠損値の数を取得する方法
.count()は欠損値を無視して、実際に有効なデータ数を取得します。 - 欠損値を含むデータの扱い
欠損値が含まれるデータでは、.sizeや.count()の違いを意識することで、目的に応じた正確な情報を取得することが重要です。
参考リンク
- Pandas Official Documentation – Series.size
- Pandas Official Documentation – Series.shape
- Pandas Official Documentation – Series.count
- Pandas Official Documentation – Working with Missing Data
少しだけPRです。
Pandasについて詳しく知りたいかた、もっと使いこなしたい方におすすめの本です。数年前に購入しましたが、今も手元に置いて時々見返しています。
「pandasクックブック Pythonによるデータ処理のレシピ」Theodore Petrou著、黒川利明訳。
最後まで読んでいただきありがとうございます。73


コメント