
こんにちは、JS2IIUです、
Pandas の apply メソッドは、データフレームの列や行に対して関数を適用する際に非常に便利な機能です。この記事では、apply メソッドを使用した具体的なサンプルプログラムを解説し、その応用方法について説明します。今回もよろしくお願いします。
サンプルプログラム
以下は、apply メソッドを使用して、模擬試験の結果を基に偏差値を計算するプログラムです。
Python
import pandas as pd
def hensachi(x, mean, std):
"""
偏差値を計算する関数。引数として、対象となる値と、その列の平均と標準偏差を受け取る。
"""
return (x - mean) / std * 10 + 50
# データの読み込み
url = 'https://raw.githubusercontent.com/JS2IIU-MH/Pandas_sampledata/refs/heads/main/data/exam_results.csv'
df = pd.read_csv(url)
# インデックス設定
df.set_index('Name', inplace=True)
# 各列の平均と標準偏差を計算
df_desc = df.describe()
# 偏差値を計算して新しい列を追加
for col in df_desc.columns:
mean = df_desc.loc['mean', col]
std = df_desc.loc['std', col]
df[f'hensachi_{col}'] = df[col].apply(hensachi, mean=mean, std=std)
# 結果を表示
print(df)
各部分の詳細解説
1. データの読み込み
Python
url = 'https://raw.githubusercontent.com/JS2IIU-MH/Pandas_sampledata/refs/heads/main/data/exam_results.csv'
df = pd.read_csv(url)- 説明: サンプルデータは CSV ファイルとして GitHub 上に公開されており、
pd.read_csvを使用して読み込みます。 - データ内容の例:
Pandas_sampledata/data/exam_results.csv at main · JS2IIU-MH/Pandas_sampledata
Sample data for Pandas demo programs. Contribute to JS2IIU-MH/Pandas_sampledata development by creating an account on GitHub.
github.com
2. インデックスの設定
Python
df.set_index('Name', inplace=True)- 説明:
set_index()メソッドを使って生徒名をインデックスとして設定します。この操作により、各生徒の名前をデータフレームの行ラベルとして使用できるようになります。

3. 偏差値計算用の関数
Python
def hensachi(x, mean, std):
"""
偏差値を計算する関数。引数として、対象となる値と、その列の平均と標準偏差を受け取る。
"""
return (x - mean) / std * 10 + 50- 説明: 偏差値を計算するための関数を定義します。
x: 偏差値を計算する対象のデータ。col: 対象となる列名。- 計算式:

4. データフレームの統計情報
Python
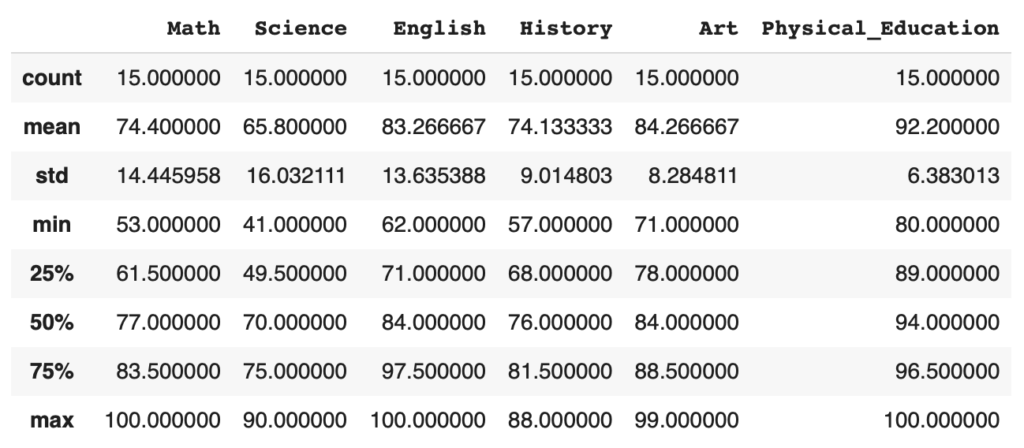
df_desc = df.describe()- 説明:
describeメソッドを使い、各列の統計情報(平均値、標準偏差など)を取得します。 - 結果の例:
plaintext Math English Science mean 82.33 75.00 88.33 std 9.07 8.54 3.51
5. apply メソッドによる列単位の計算
Python
# 偏差値を計算して新しい列を追加
for col in df_desc.columns:
mean = df_desc.loc['mean', col]
std = df_desc.loc['std', col]
df[f'hensachi_{col}'] = df[col].apply(hensachi, mean=mean, std=std)- 説明: 各列に対して偏差値を計算し、新しい列として追加します。
apply(hensachi, mean=mean, std=std):hensachi関数を各セルに適用。mean=meanとstd=stdによって対象の列の平均値、標準偏差を指定。
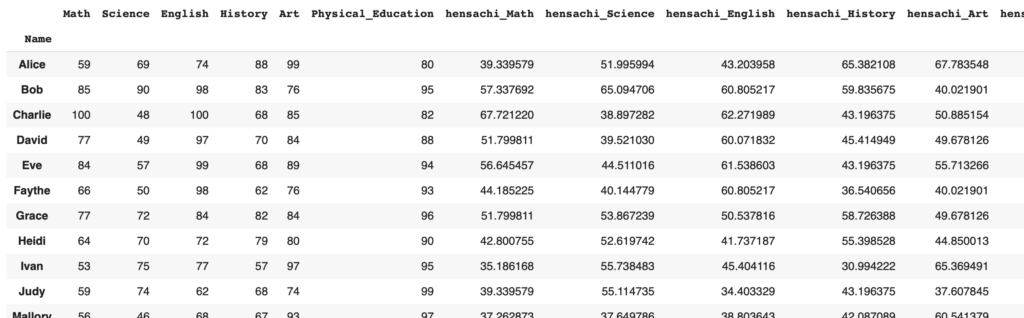
6. 出力結果
最終的なデータフレームの出力例は次のようになります。
使いどころと注意点
applyメソッドは、列や行方向に複雑な操作を適用したい場合に便利です。- 注意:
applyはループと似た動作をするため、非常に大規模なデータではパフォーマンスに影響が出る可能性があります。その場合は、NumPyなどを使用したベクトル演算を検討してください。
参考リンク
Pandas の公式ドキュメント
関連記事
- Pandas
applyの使い方 (Real Python)
URL: https://realpython.com/pandas-apply/ describeメソッドの解説
URL: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.describe.html
今回も少しだけPRです。
Pandasについて詳しく知りたいかた、もっと使いこなしたい方におすすめの本です。数年前に購入しましたが、今も手元に置いて時々見返しています。
「pandasクックブック Pythonによるデータ処理のレシピ」Theodore Petrou著、黒川利明訳。

https://amzn.to/41hKYvZ
amzn.to
最後まで読んでいただきありがとうございます。73


コメント