



こんにちは、JS2IIUです。
Pandas の apply メソッドは、データフレームの列や行に関数を適用する際に便利です。しかし、データ量が増えるとパフォーマンスが問題になることがあります。この記事では、apply メソッドを使わずに、カラムに対して関数を適用して効率的に計算する方法を解説します。
サンプルプログラム
Python
import pandas as pd
# 偏差値計算用の関数
def calc_hensachi(series):
mean = series.mean()
std = series.std()
return (series - mean) / std * 10 + 50
# データの読み込み
url = 'https://raw.githubusercontent.com/JS2IIU-MH/Pandas_sampledata/refs/heads/main/data/exam_results.csv'
df = pd.read_csv(url)
# インデックス設定
df.set_index('Name', inplace=True)
# 偏差値の計算
for col in df.columns:
df[f'hensachi_{col}'] = calc_hensachi(df[col])
print(df)各部分の詳細解説
1. データの読み込みとインデックスの設定
Python
url = 'https://raw.githubusercontent.com/JS2IIU-MH/Pandas_sampledata/refs/heads/main/data/exam_results.csv'
df = pd.read_csv(url)
df.set_index('Name', inplace=True)- サンプルデータを読み込み、
Name列をインデックスに設定します。



Pandas_sampledata/data/exam_results.csv at main · JS2IIU-MH/Pandas_sampledata
Sample data for Pandas demo programs. Contribute to JS2IIU-MH/Pandas_sampledata development by creating an account on GitHub.

github.com
2. 偏差値計算用関数の効率化
Python
def calc_hensachi(series):
mean = series.mean()
std = series.std()
return (series - mean) / std * 10 + 50- 改善点:
- 列全体を直接受け取ることで、
meanとstdの計算を一度だけ行います。 - 計算結果を列全体に適用するため、Pandas の高速なベクトル演算を活用します。
- 列全体を直接受け取ることで、


3. 偏差値の計算ループ
Python
for col in df.columns:
df[f'hensachi_{col}'] = calc_hensachi(df[col])- 改善点:
applyを使用せず、列ごとに計算を実行。- 各列の偏差値を新しい列として追加します。
4. 出力結果
修正後のコードで生成されるデータフレームの例は以下の通りです。

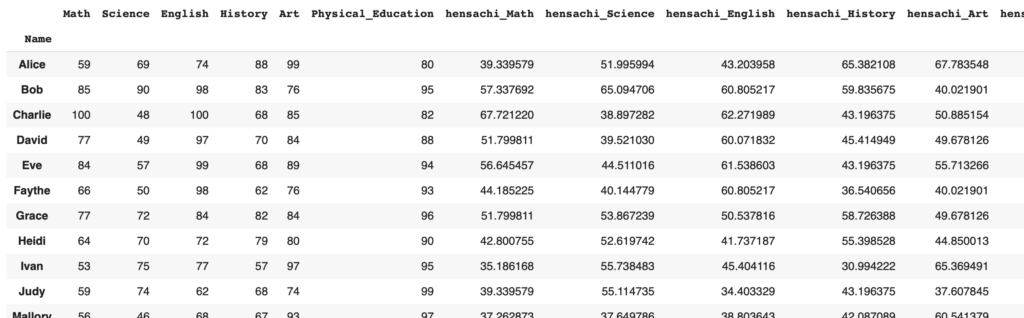
効率化のメリット
- ベクトル化を使用したことで、列方向の操作が高速化されます。
applyによる個別の値処理を避け、大量データでの処理速度が向上します。
使いどころと注意点
applyは便利ですが、列全体や行全体に対する単純な操作では、Pandas のベクトル演算を直接使用する方が効率的です。- この方法では、列方向の統計値を計算する際の一貫性を保ちながら処理を簡潔に記述できます。
参考リンク
Pandas の公式ドキュメント
関連記事
- Pandas
applyの使い方 (Real Python)
URL: https://realpython.com/pandas-apply/ - ベクトル化のメリットについて
URL: https://pandas.pydata.org/pandas-docs/stable/user_guide/basics.html#vectorized-operations
今回も少しだけPRです。
Pandasについて詳しく知りたいかた、もっと使いこなしたい方におすすめの本です。数年前に購入しましたが、今も手元に置いて時々見返しています。
「pandasクックブック Pythonによるデータ処理のレシピ」Theodore Petrou著、黒川利明訳。

最後まで読んでいただきありがとうございます。73