



こんにちは、JS2IIUです。
データ分析において、データを集計・要約し、多角的な視点から分析することは非常に重要です。そのための強力なツールの一つが「ピボットテーブル」です。この記事では、PythonのPandasライブラリにおけるピボットテーブルの作成方法と、その応用について詳しく解説します。
1. ピボットテーブルとは
定義と目的: ピボットテーブルは、大量のデータを要約し、整理するための表です。行と列を入れ替えたり、集計方法を変えたりすることで、様々な角度からデータを分析できます。データ分析の現場では、データ全体の傾向を把握したり、特定の条件を満たすデータの集計を行ったりする際によく用いられます。
Excelとの比較: ピボットテーブルはExcelでもおなじみの機能です。ExcelのピボットテーブルとPandasのピボットテーブルは、概念的には非常に似ています。しかし、PandasではPythonの豊富なライブラリと連携することで、より柔軟で高度なデータ操作や分析、可視化が可能になります。
2. Pandasにおけるピボットテーブルの作成 (pivot_table関数)
Pandasでピボットテーブルを作成するには、pivot_table関数を使用します。基本的な構文は以下の通りです。
pd.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)各引数の説明:
data: 使用するDataFrame。values: 集計する列。index: 行インデックスとして使用する列。columns: 列インデックスとして使用する列。aggfunc: 集計関数(’mean’(平均)、’sum’(合計)、’median’(中央値)、’count’(個数)など)。リストや辞書で複数の関数を指定することも可能です。fill_value: 欠損値を埋める値。margins: 行と列の合計(総計)を表示するかどうか。dropna: すべてNaNの列を削除するかどうか。margins_name: マージン(合計)の名前。observed: カテゴリカル変数の処理方法(Pandas 1.3以降)。Trueの場合、実際に観測されたカテゴリのみを使用。Falseの場合、定義されているすべてのカテゴリを使用。sort: 結果をソートするかどうか(Pandas 1.3以降)。
なお、本記事を書いた2024年12月の時点でPandasのバージョンは2.2.3になっています。
簡単な例:
以下のような売上データDataFrameを例に、ピボットテーブルを作成してみましょう。
import pandas as pd
import numpy as np
data = {'Shop': ['A', 'A', 'B', 'B', 'A', 'B'],
'Product': ['X', 'Y', 'X', 'Y', 'X', 'Y'],
'Sales': [100, 150, 200, 250, 120, 180]}
df = pd.DataFrame(data)
print(df)出力:
Shop Product Sales
0 A X 100
1 A Y 150
2 B X 200
3 B Y 250
4 A X 120
5 B Y 180店舗ごとの売上合計を計算するピボットテーブルを作成します。集計する列として'Sales'(売上)、集計する列を'Shop'(店舗)とします。aggfunc集計関数にsumを指定して、各店舗における売上の合計を表示します。


pivot_table = pd.pivot_table(df, values='Sales', index='Shop', aggfunc='sum')
print(pivot_table)出力:
Sales
Shop
A 370
B 6303. aggfuncの応用
複数の集計関数:
商品ごとの売上合計と平均を同時に計算するには、aggfuncにリストを指定します。


pivot_table = pd.pivot_table(df, values='Sales', index='Product', aggfunc=['sum', 'mean'])
print(pivot_table)出力:
sum mean
Sales Sales
Product
X 420 140.000000
Y 580 193.333333カスタム集計関数:
例えば、最大値と最小値の差を計算する関数を定義してaggfuncに渡すことができます。
def range_func(x):
return x.max() - x.min()
pivot_table = pd.pivot_table(df, values='Sales', index='Shop', aggfunc=range_func)
print(pivot_table)出力:
Sales
Shop
A 50
B 704. マルチインデックス(階層的なインデックス)
複数のindexとcolumnsの指定:
店舗と商品ごとの売上を計算するには、indexに複数の列を指定します。

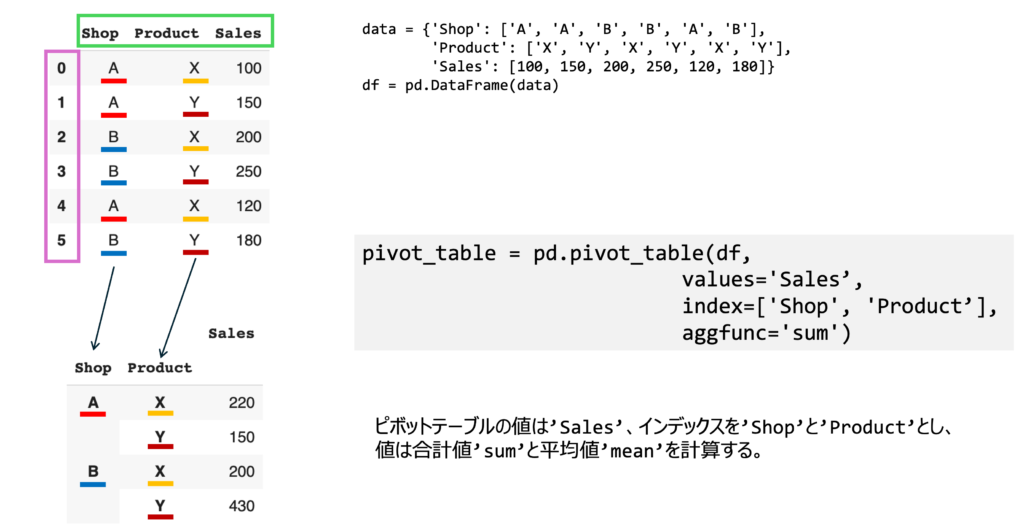
pivot_table = pd.pivot_table(df, values='Sales', index=['Shop', 'Product'], aggfunc='sum')
print(pivot_table)出力:
マルチインデックス('Shop', 'Product')を持つDataFrameとして出力されました。
Sales
Shop Product
A X 220
Y 150
B X 200
Y 430stackとunstack:
stackは列インデックスを最下層の行インデックスに移動し、unstackはその逆を行います。
stacked = pivot_table.stack()
print(stacked)
unstacked = stacked.unstack()
print(unstacked)# print(stacked)
Shop Product
A X Sales 220
Y Sales 150
B X Sales 200
Y Sales 430
dtype: int64# print(unstacked)
Sales
Shop Product
A X 220
Y 150
B X 200
Y 4305. 欠損値の扱い (fill_value)
データに欠損値がある場合、fill_valueで埋めることができます。下の例ではfill_value=0としているので、欠損値に対してゼロで埋めていきます。
data_with_nan = {'Shop': ['A', 'A', 'B'], 'Product': ['X', 'Y', 'X'], 'Sales': [100, np.nan, 200]}
df_with_nan = pd.DataFrame(data_with_nan)
pivot_table_with_nan = pd.pivot_table(df_with_nan, values='Sales', index='Shop', aggfunc='sum', fill_value=0)
print(pivot_table_with_nan) Sales
Shop
A 100.0
B 200.06. マージン(合計)の表示 (margins)
margins=Trueで合計を表示します。
pivot_table_with_margins = pd.pivot_table(df, values='Sales', index='Shop', aggfunc='sum', margins=True, margins_name='Sum')
print(pivot_table_with_margins) Sales
Shop
A 370
B 630
Sum 10007. 実践的な応用例
例えば、顧客のアンケートデータを用いて、性別ごとの満足度を分析することができます。また、売上データと広告データを組み合わせて、広告の効果を分析することもできます。作成したピボットテーブルを元にMatplotlibやSeabornでグラフを作成することで、分析結果を視覚的に表現できます。
8. その他の高度なトピック
その他のトピックについては、別の記事にしたいと思います。
crosstab関数:crosstabは、カテゴリカルデータのクロス集計を行うための関数です。pivot_tableと似た機能を提供しますが、より簡潔に記述できる場合があります。- パフォーマンス: 大規模データでは、データ型を適切に設定したり、
observed引数を活用することで、パフォーマンスを改善できます。
関連するWEBサイト
- Pandas公式ドキュメント: Pandasの公式ドキュメントは、詳細な情報と例が豊富です。
- Reshaping and pivot tables — pandas 2.2.3 documentation
今回も少しだけPRです。
Pandasについて詳しく知りたいかた、もっと使いこなしたい方におすすめの本です。数年前に購入しましたが、今も手元に置いて時々見返しています。
「pandasクックブック Pythonによるデータ処理のレシピ」Theodore Petrou著、黒川利明訳。

最後まで読んでいただきありがとうございます。73