



こんにちは、JS2IIUです。
今回はStreamlitを使って線形回帰モデルの学習結果を散布図と回帰直線で表示するアプリを作成していきます。今回もよろしくお願いします。
1. はじめに
本記事では、PythonとStreamlitを使って「線形回帰分析の結果を可視化するWebアプリ」を作成します。回帰分析はデータ分析や機械学習の基本中の基本であり、「ある変数(x)が変化すると、別の変数(y)がどう変化するか?」という関係を調べるときに使われます。
たとえば、「勉強時間が増えるとテストの点数は上がるか?」といった問いに答えるために、回帰分析は非常に役立ちます。
今回は、以下のような簡単なアプリを作っていきます:
- データを散布図で表示
- 線形回帰モデルを学習
- 回帰直線を重ねて表示
- Streamlitで簡単なインターフェースを作成
2. 回帰分析とは?
回帰分析は、ある変数(特徴量)から別の変数(目的変数)を予測するための手法です。
中でも最も基本的なのが線形回帰(Linear Regression)です。
線形回帰では、以下のような数式で2つの変数の関係を表します:
y = a * x + b
x: 入力(例:勉強時間)y: 出力(例:テストの点数)a: 傾き(xが1増えるとyがどれだけ増えるか)b: 切片(x=0のときのyの値)
この直線をデータに当てはめることで、未来のデータを予測することができます。
3. 使用するライブラリ
まずは、必要なPythonライブラリを確認しましょう。以下のライブラリを使用します:
pip install pandas numpy matplotlib scikit-learn streamlit各ライブラリの役割は以下の通りです:
| ライブラリ | 役割 |
|---|---|
pandas | データ操作 |
numpy | 数値計算、乱数生成など |
matplotlib | グラフの描画 |
scikit-learn | 回帰モデルの構築 |
streamlit | Webアプリの作成 |
4. データの準備
今回は、簡単な疑似データをPythonで自動生成して使います。
import numpy as np
import pandas as pd
# ランダムなデータを生成
np.random.seed(42) # 再現性のための固定
x = np.random.rand(100) * 10 # 0〜10の範囲で100個のデータ
noise = np.random.randn(100) # ノイズ(正規分布)
y = 2.5 * x + 5 + noise # 回帰直線にノイズを加える
# DataFrameにまとめる
df = pd.DataFrame({'x': x, 'y': y})このデータは、「xの値が大きくなるほど、yも大きくなる」という傾向を持ったデータです。

5. 線形回帰モデルの構築
次に、scikit-learnを使って線形回帰モデルを学習させます。
from sklearn.linear_model import LinearRegression
# 特徴量と目的変数に分ける
X = df[['x']] # 入力は2次元配列が必要
y = df['y']
# モデルの作成と学習
model = LinearRegression()
model.fit(X, y)
# 回帰直線の係数と切片を取得
a = model.coef_[0]
b = model.intercept_
print(f"回帰直線の式: y = {a:.2f}x + {b:.2f}")ここで得られる a と b が、回帰直線のパラメータです。以下のような出力が得られます。
回帰直線の式: y = 2.45x + 5.226. 結果の可視化
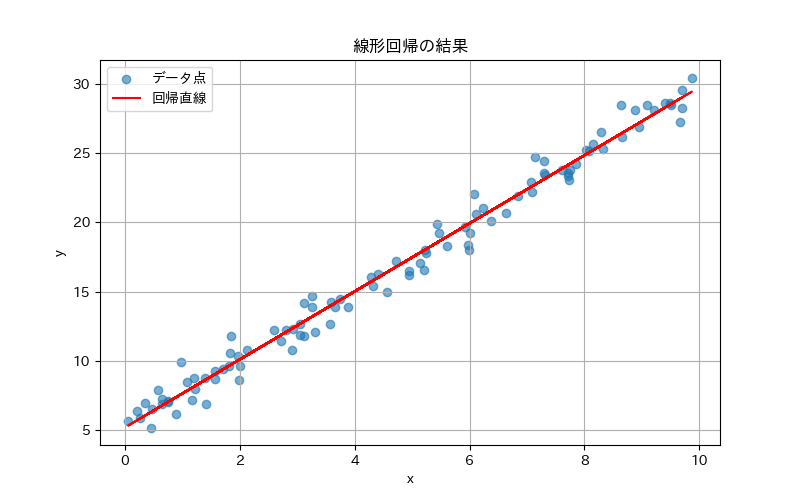
matplotlibを使って、元データと回帰直線を描画します。
import matplotlib.pyplot as plt
# 回帰直線の予測値
y_pred = model.predict(X)
# グラフの描画
plt.figure(figsize=(8, 5))
plt.scatter(x, y, label='データ点', alpha=0.6)
plt.plot(x, y_pred, color='red', label='回帰直線')
plt.xlabel('x')
plt.ylabel('y')
plt.title('線形回帰の結果')
plt.legend()
plt.grid(True)
plt.show()このグラフを見ると、点群(散布図)の傾向に合わせて直線が引かれていることがわかります。

7. Streamlitアプリの作成
では、これらの処理をStreamlitアプリに組み込みましょう。
アプリ全体のコード(streamlit_app.py)
import streamlit as st
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.linear_model import LinearRegression
st.title("【Streamlit】回帰分析の可視化アプリ")
# サンプルデータの生成
st.sidebar.header("データ生成設定")
n_samples = st.sidebar.slider("データ数", 10, 500, 100)
noise_level = st.sidebar.slider("ノイズの強さ", 0.0, 10.0, 1.0)
np.random.seed(42)
x = np.random.rand(n_samples) * 10
noise = np.random.randn(n_samples) * noise_level
y = 2.5 * x + 5 + noise
df = pd.DataFrame({'x': x, 'y': y})
# 回帰モデルの学習
X = df[['x']]
model = LinearRegression()
model.fit(X, df['y'])
y_pred = model.predict(X)
# 回帰式の表示
st.write(f"**回帰直線の式**: y = {model.coef_[0]:.2f}x + {model.intercept_:.2f}")
# グラフの表示
fig, ax = plt.subplots()
ax.scatter(df['x'], df['y'], label='データ点', alpha=0.6)
ax.plot(df['x'], y_pred, color='red', label='回帰直線')
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_title("線形回帰の結果")
ax.legend()
ax.grid(True)
st.pyplot(fig)
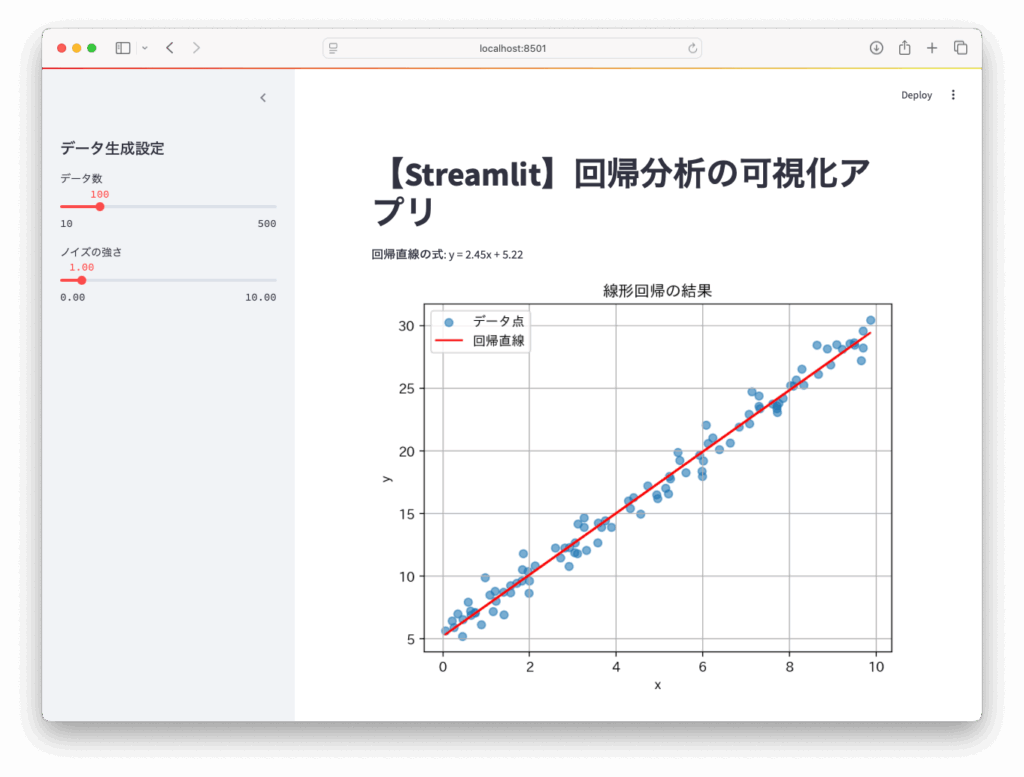
実行方法
ターミナルで以下のコマンドを実行すれば、ローカルサーバー上にアプリが立ち上がります:
streamlit run streamlit_app.pymatplotlibのタイトル日本語化
ソースの5行目にimport japanize_matplotlibを追加しています。japanize-matplotlibによってタイトル部分の日本語フォントが表示される様になります。詳しくはこちらの記事を参照してください。
【Python】matplotlibの日本語文字化けを解消する方法 | アマチュア無線局JS2IIU
8. まとめと今後のステップ
本記事では、以下の内容を学びました:
- 線形回帰とは何か
- Pythonで線形回帰モデルを構築する方法
- 結果を可視化する方法
- Streamlitで簡単なWebアプリを作成する手順
次のステップとしては:
- 実際のCSVファイルを読み込んで分析してみる
- 複数の変数を使った「重回帰分析」に挑戦してみる
- 残差分析や評価指標(R²スコアなど)を追加してみる
9. 参考リンク
最後に書籍のPRです。
24年11月に第3版が発行された「scikit-learn、Keras、TensorFlowによる実践機械学習 第3版」、Aurélien Géron 著。下田、牧、長尾訳。機械学習のトピックスについて手を動かしながら網羅的に学べる書籍です。ぜひ手に取ってみてください。

最後まで読んでいただきありがとうございます。