
こんにちは、JS2IIUです。
蓄積されるデータから異常を検知するという活用シーンは世の中に多いと思います。センサデータの蓄積が楽にできるようになってきたので異常検知アプリのニーズが高くなってきています。機械学習の手法(Isolation Forest)を用いて異常検知するアプリを作成します。今回もよろしくお願いします。
1. はじめに
日々の業務やデータ分析の現場では、「いつもと違う状態」や「予期しない動き」に素早く気づくことが重要です。こうした異常を検出する手法を「異常検知(Anomaly Detection)」と呼びます。
本記事では、異常検知の基本的な考え方を紹介し、StreamlitというPythonライブラリを使って、異常検知の結果をわかりやすく可視化するアプリを作っていきます。さらに、機械学習を用いた異常検知と、それ以外の方法(ルールベース)についても具体的に解説します。
2. 異常検知とは?
異常検知とは、正常な状態から逸脱したデータを自動的に見つけ出す技術です。例えば、次のようなケースが該当します:
- センサー値が急激に変化した(工場の機器の故障)
- ログイン回数が異常に多い(セキュリティ侵害)
- クレジットカードの利用パターンが不自然(不正利用)
異常検知の方法は、大きく分けて次の2つがあります:
- ルールベース(しきい値ベース):手動で条件を設定
- 機械学習ベース:データから学習して異常を自動判定
3. 異常検知のアプローチ
3.1 ルールベースの手法
ルールベースの異常検知はシンプルです。例えば「温度が100度を超えたら異常」といった閾値を設定します。以下はzスコアを使った例です。
import numpy as np
# データ
values = [10, 12, 11, 13, 95, 14, 10]
# 平均と標準偏差
mean = np.mean(values)
std = np.std(values)
# zスコアで異常検知
z_scores = [(x - mean) / std for x in values]
anomalies = [x for x, z in zip(values, z_scores) if abs(z) > 2]
print("異常値:", anomalies)次のような結果が表示されます:
異常値: [95]3.2 機械学習を使った手法(Isolation Forest)
機械学習では、過去の正常データをもとに異常なデータを判定します。今回はIsolationForestを使用します。
from sklearn.ensemble import IsolationForest
import numpy as np
# 正常と異常の混在するデータ(2次元)
X = np.array([
[10, 10], [12, 11], [13, 13], [12, 12], [9, 10],
[100, 100] # 異常
])
clf = IsolationForest(contamination=0.1, random_state=42)
clf.fit(X)
labels = clf.predict(X) # 1:正常, -1:異常
print("判定結果:", labels)次の様な結果が表示されます:
判定結果: [ 1 1 1 1 1 -1]✅ ステップ 1: 必要なライブラリのインポート
from sklearn.ensemble import IsolationForest
import numpy as npIsolationForest: scikit-learnライブラリにある異常検知用のモデルです。正常データを多数と仮定して、「孤立しやすい(=異常な)」データを検出します。numpy: 数値計算ライブラリ。データを行列形式で扱うために使用します。
✅ ステップ 2: データの準備
X = np.array([
[10, 10], [12, 11], [13, 13], [12, 12], [9, 10],
[100, 100] # 異常
])Xは異常検知に使用する 2次元データ のリストをNumPy配列に変換したものです。- 各要素は
[x座標, y座標]を持つ2次元の点です。 - 最後の
[100, 100]は、明らかに他と離れており、異常なデータとみなされることを期待しています。
✅ ステップ 3: Isolation Forest モデルの作成
clf = IsolationForest(contamination=0.1, random_state=42)contamination=0.1: データの中に約10%(=1つ)の異常が含まれていると想定。random_state=42: 結果の再現性を保つための乱数シード。どのようにデータを「分離(isolate)」するかのランダム性に影響します。clfは異常検知のためのモデルインスタンスです。
✅ ステップ 4: モデルにデータを学習させる
clf.fit(X)fit(X)によって、モデルがXの構造(どんな分布になっているか)を学習します。- 正常なデータの分布を理解し、それと「違う」ものを異常と判定できるようになります。
✅ ステップ 5: 異常・正常の判定を行う
labels = clf.predict(X)predict(X)は、各データ点に対して 異常かどうかのラベル を出力します。- 出力は以下の通り:
1: 正常-1: 異常
✅ ステップ 6: 判定結果を表示
print("判定結果:", labels)- 出力されるのは、
Xの各データが正常 (1) か異常 (-1) かを示す配列です。 - 期待される出力例:
判定結果: [ 1 1 1 1 1 -1 ]→ 最後の [100, 100] だけが -1(異常)と判定されています。
🔍 Isolation Forest の特徴
- ランダムに決めたしきい値でデータを分割していき、「分離しやすさ」で異常を測ります。
- 分離にかかるステップ数が少ないほど異常とみなされる。
- ラベル付きデータが不要なので、教師なし学習に分類されます。
4. Streamlitアプリで異常検知を可視化する
ここでは、Streamlitを使って異常検知の結果を可視化するWebアプリを作成します。
4.1 必要なライブラリのインストール
pip install streamlit scikit-learn pandas matplotlib4.2 アプリのコード
以下がStreamlitアプリ全体のコードです。
import streamlit as st
import pandas as pd
import numpy as np
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
import japanize_matplotlib
st.title("異常検知の可視化アプリ")
# データ作成
def generate_data():
normal = np.random.normal(loc=50, scale=5, size=(100, 2))
anomaly = np.random.uniform(low=80, high=100, size=(5, 2))
data = np.vstack((normal, anomaly))
return pd.DataFrame(data, columns=["x", "y"])
# データ読み込み
st.subheader("1. データの生成")
data = generate_data()
st.write(data.head())
# モデル学習
st.subheader("2. Isolation Forest による異常検知")
model = IsolationForest(contamination=0.05, random_state=0)
data["label"] = model.fit_predict(data)
# 可視化
st.subheader("3. 結果の可視化")
fig, ax = plt.subplots()
normal_data = data[data["label"] == 1]
anomaly_data = data[data["label"] == -1]
ax.scatter(normal_data["x"], normal_data["y"], label="正常", c="blue")
ax.scatter(anomaly_data["x"], anomaly_data["y"], label="異常", c="red")
ax.legend()
st.pyplot(fig)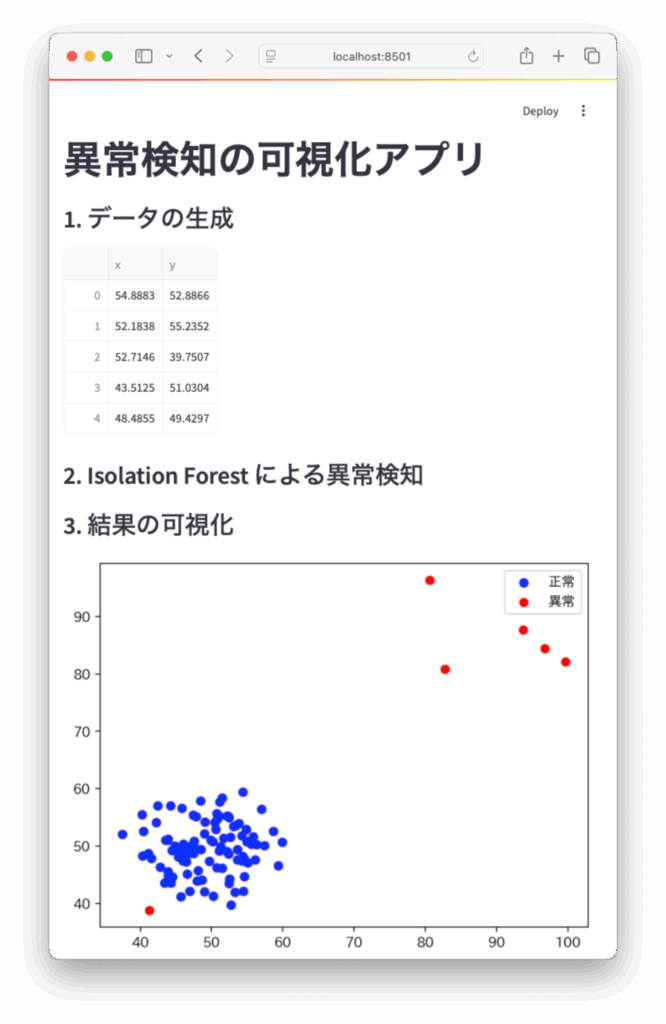
5. 機械学習 vs 非機械学習:どう使い分ける?
| 手法 | 特徴 | 適している場面 |
|---|---|---|
| ルールベース | シンプル、設定が明快 | 小規模データ、簡易監視など |
| 機械学習 | 柔軟・高精度 | データが複雑、大規模な場合 |
実際の現場では、両者を併用して「まずはしきい値、次に機械学習で補完」する方法もよく使われます。
6. まとめ
今回は異常検知の基本から、機械学習を使った異常検知の実装、Streamlitを使った可視化までを丁寧に解説しました。以下のポイントを押さえておくと良いでしょう:
- 異常検知はさまざまな現場で活用される重要な技術
- 機械学習手法(Isolation Forestなど)を使うことで自動化が可能
- Streamlitを使えば、結果の可視化も簡単で効果的
ぜひご自身のデータでも応用してみてください!
7. 参考リンク
最後に書籍のPRです。
24年11月に第3版が発行された「scikit-learn、Keras、TensorFlowによる実践機械学習 第3版」、Aurélien Géron 著。下田、牧、長尾訳。機械学習のトピックスについて手を動かしながら網羅的に学べる書籍です。ぜひ手に取ってみてください。
最後まで読んでいただきありがとうございます。


コメント