
こんにちは、JS2IIUです。
機械学習エンジニアやデータサイエンティストの皆さん、日々の業務お疲れ様です。Pythonで高度なデータ分析やモデル構築を行い、素晴らしいインサイトを得た後、最後に待っているのが「PowerPointでの報告資料作成」です。
「Jupyter Notebookのグラフを画像保存して、パワポに貼り付けて、サイズを調整して、数値を表に入力して……」
この単純作業に、貴重なエンジニアリングリソースを割くのは非常にもったいないことです。
今回は、この「ラストワンマイル」をPythonで自動化するライブラリ、python-pptxについて徹底解説します。Pandasとの連携も含め、実務ですぐに使えるテクニックを紹介していきます。今回もよろしくお願いします。
1. python-pptx とは
ライブラリの概要
python-pptxは、Microsoft PowerPointファイル(.pptx)を作成・読み込み・更新するためのPythonライブラリです。
PowerPointがインストールされていない環境(Linuxサーバー上のDockerコンテナなど)でも動作するため、サーバーサイドで定期的にレポートを自動生成してメール送信するといったシステム構築が可能です。
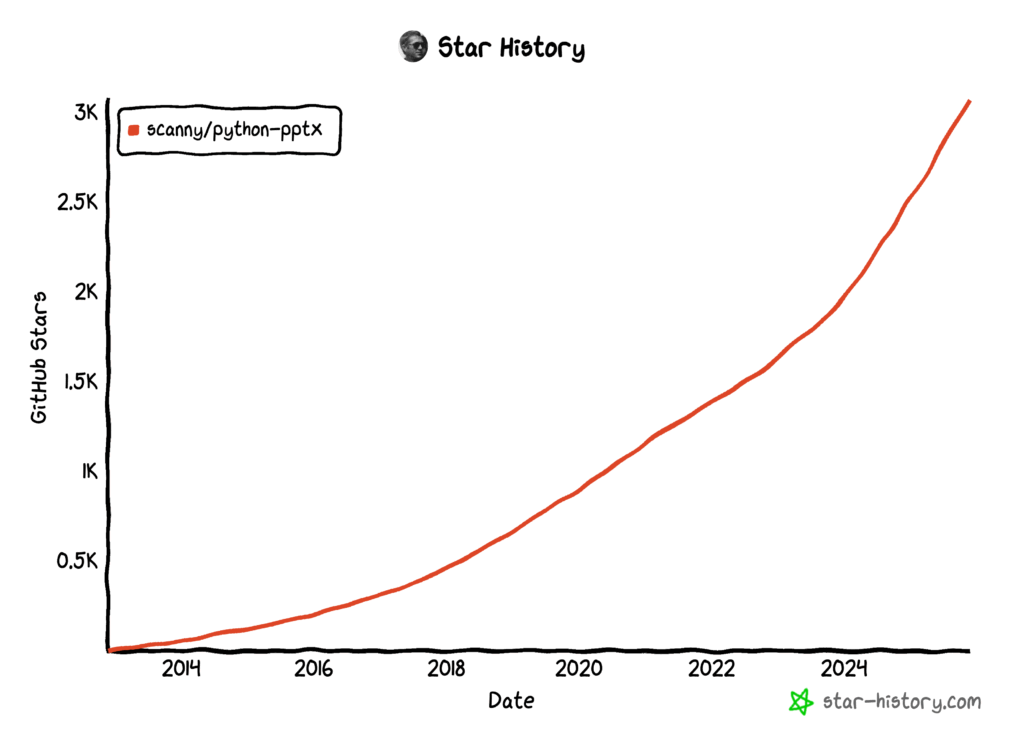
python-pptxのStar Historyです。こちらの図は2025年11月時点のものです。
主な特徴
- 新規作成と編集: ゼロからのファイル作成だけでなく、既存の
.pptxファイルをテンプレートとして読み込み、特定の部分だけ書き換えることができます。 - 豊富な要素: テキストボックス、図形、画像、表(Table)、グラフ(Chart)など、PowerPointの主要な機能を操作できます。
ライセンスについて
このライブラリは MIT License で公開されています。
MITライセンスは非常に寛容なライセンスであり、著作権表示など条件を守れば、商用・非商用を問わず、誰でも無償で自由に使用、改変、再配布することができます。企業のプロジェクトでも安心して導入しやすいライブラリです。
概念図:オブジェクトの階層構造
コーディングに入る前に、python-pptxがどのようにファイルを認識しているか、メンタルモデルを持っておきましょう。
Presentation(プレゼンテーション全体)
└ Slides(スライドのリスト)
└ Slide(個別のスライド)
└ Shapes(図形、テキスト、画像、表などの要素)
コードを書く際は、まず「プレゼンテーション」を作り、そこに「スライド」を追加し、さらにそのスライドの上に「シェイプ(要素)」を乗せていく、という手順になります。
2. 環境構築
まずはライブラリをインストールしましょう。今回はデータ処理用にpandasも使用するため、併せてインストールします。
pip install python-pptx pandas3. 【実践】基本的なスライドの作成
それでは、実際にコードを書いてみましょう。
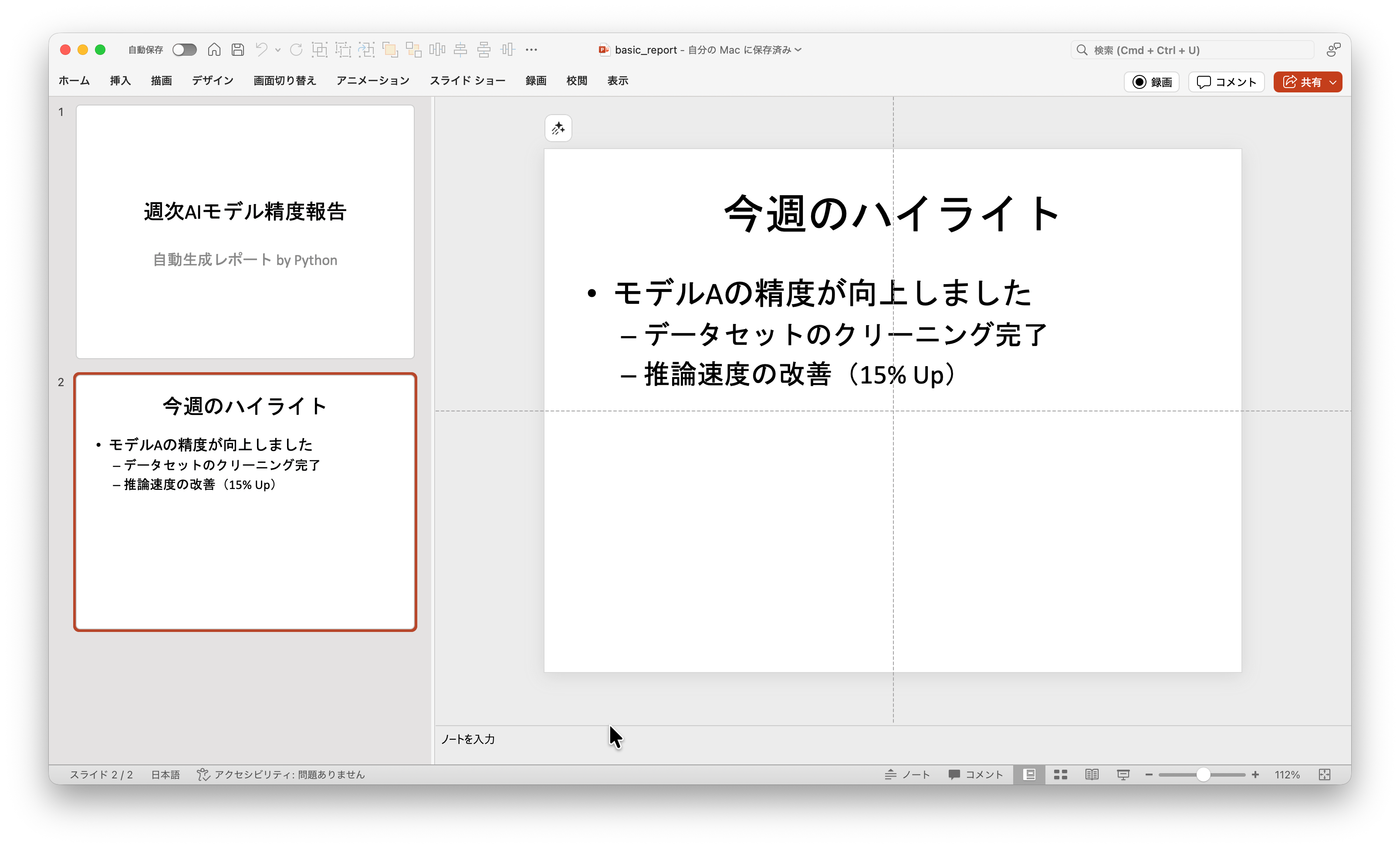
まずは、「タイトルスライド」と「箇条書きのあるスライド」を含むシンプルなPowerPointファイルを生成します。
基本実装コード
from pptx import Presentation
from pptx.util import Inches, Pt
def create_basic_presentation(output_filename):
"""
基本的なPowerPointファイルを作成する関数
"""
# 1. Presentationオブジェクト(パワポ全体)の生成
prs = Presentation()
# --- 1枚目:タイトルスライド ---
# slide_layouts[0] は通常「タイトルスライド」のレイアウト
title_slide_layout = prs.slide_layouts[0]
slide1 = prs.slides.add_slide(title_slide_layout)
# タイトルとサブタイトルのプレースホルダーを取得して書き込み
title = slide1.shapes.title
subtitle = slide1.placeholders[1]
title.text = "週次AIモデル精度報告"
subtitle.text = "自動生成レポート by Python"
# --- 2枚目:コンテンツスライド(タイトル+コンテンツ) ---
# slide_layouts[1] は通常「タイトルとコンテンツ」のレイアウト
bullet_slide_layout = prs.slide_layouts[1]
slide2 = prs.slides.add_slide(bullet_slide_layout)
# タイトルの設定
slide2.shapes.title.text = "今週のハイライト"
# 本文(プレースホルダー)への書き込み
body_shape = slide2.placeholders[1]
tf = body_shape.text_frame
tf.text = "モデルAの精度が向上しました" # 1行目
# 箇条書きの追加
p = tf.add_paragraph()
p.text = "データセットのクリーニング完了"
p.level = 1 # インデントレベル(1段下げる)
p = tf.add_paragraph()
p.text = "推論速度の改善(15% Up)"
p.level = 1
# --- ファイルの保存 ---
prs.save(output_filename)
print(f"Saved: {output_filename}")
if __name__ == "__main__":
create_basic_presentation("basic_report.pptx")コードの詳細解説
Presentation(): これがPowerPointファイルそのものです。既存のファイルを読み込む場合はPresentation('existing_file.pptx')とします。slide_layouts: PowerPointには「タイトルスライド」「白紙」などのレイアウトテンプレートがあります。python-pptxではインデックス番号で指定します。0: タイトルスライド1: タイトルとコンテンツ6: 白紙- ※テンプレートによって順番が異なる場合があるため、実務ではテンプレートを確認する必要があります。
placeholders: レイアウトにあらかじめ用意されている枠(タイトル枠や本文枠)です。これらを取得して.textプロパティに文字列を代入することで文字を表示させます。
このコードを実行すると、カレントディレクトリに basic_report.pptx が生成されます。これだけでも、定型文の流し込み作業は自動化できますね。
4. 【応用】Pandas データフレームをPowerPointの表に出力する
ここからがテックブログ読者の皆様にとっての本題です。
AI開発やデータ分析では、Pandasで作った集計表(DataFrame)をスライドに貼る作業が頻繁に発生します。これを自動化しましょう。
python-pptxには表を作成する機能がありますが、セル一つひとつに値をセットしていく必要があり、少し記述が冗長になりがちです。そこで、DataFrameを渡すと自動的にPowerPointの表に変換する関数を作成します。
Pandas連携の実装コード
import pandas as pd
from pptx import Presentation
from pptx.util import Inches
from pptx.enum.text import PP_ALIGN
def df_to_pptx_table(slide, df, left, top, width, height):
"""
Pandas DataFrameをPowerPointのスライド上にテーブルとして描画する関数
Args:
slide: 追加対象のスライドオブジェクト
df: データを含むPandas DataFrame
left, top: テーブルの左上の位置
width, height: テーブル全体のサイズ
"""
# 行数と列数を計算(ヘッダー分として行数に+1)
rows, cols = df.shape
rows += 1
# テーブルシェイプの追加
table_shape = slide.shapes.add_table(rows, cols, left, top, width, height)
table = table_shape.table
# --- ヘッダーの書き込み ---
for col_idx, col_name in enumerate(df.columns):
cell = table.cell(0, col_idx)
cell.text = str(col_name)
# デザイン調整(任意):太字にするなど
cell.text_frame.paragraphs[0].font.bold = True
cell.text_frame.paragraphs[0].alignment = PP_ALIGN.CENTER
# --- データの中身(ボディ)の書き込み ---
for row_idx in range(df.shape[0]):
for col_idx in range(df.shape[1]):
# tableの行インデックスはヘッダーの分だけ +1 ズレることに注意
cell = table.cell(row_idx + 1, col_idx)
# DataFrameの値を文字列に変換してセット
val = df.iloc[row_idx, col_idx]
# 数値のフォーマット調整(例:小数は丸める)
if isinstance(val, float):
cell.text = f"{val:.2f}"
else:
cell.text = str(val)
# 中央揃え
cell.text_frame.paragraphs[0].alignment = PP_ALIGN.CENTER
def create_data_report(output_filename):
# サンプルデータの作成(PyTorchなどの実験結果を想定)
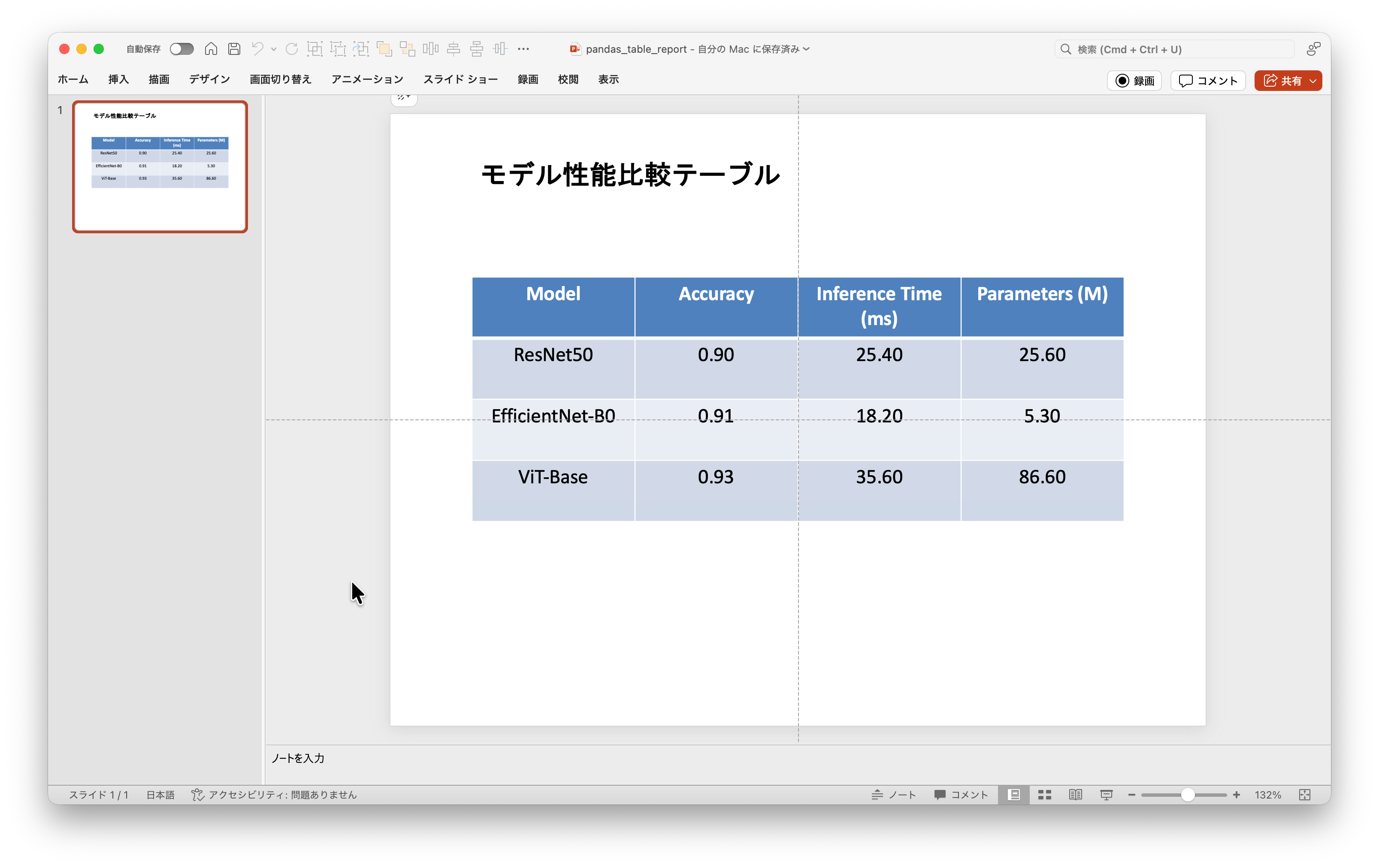
data = {
'Model': ['ResNet50', 'EfficientNet-B0', 'ViT-Base'],
'Accuracy': [0.8954, 0.9120, 0.9345],
'Inference Time (ms)': [25.4, 18.2, 35.6],
'Parameters (M)': [25.6, 5.3, 86.6]
}
df = pd.DataFrame(data)
# プレゼンテーション作成
prs = Presentation()
# 白紙のスライドを追加 (レイアウト6番)
blank_slide_layout = prs.slide_layouts[6]
slide = prs.slides.add_slide(blank_slide_layout)
# タイトルをテキストボックスとして追加
title_box = slide.shapes.add_textbox(Inches(1), Inches(0.5), Inches(8), Inches(1))
title_box.text_frame.text = "モデル性能比較テーブル"
title_box.text_frame.paragraphs[0].font.size = Pt(24)
title_box.text_frame.paragraphs[0].font.bold = True
# DataFrameをテーブルとして出力
# 位置とサイズを指定 (Inchesで指定すると直感的)
df_to_pptx_table(
slide,
df,
left=Inches(1),
top=Inches(2),
width=Inches(8),
height=Inches(3)
)
prs.save(output_filename)
print(f"Saved: {output_filename}")
if __name__ == "__main__":
create_data_report("pandas_table_report.pptx")解説とポイント
df_to_pptx_table関数: この関数が肝です。table.cell(row, col)で特定のセルにアクセスし、.textで値を入れます。- インデックスの管理: PowerPointのテーブルには「ヘッダー行」を含める必要があるため、ループ処理の際はDataFrameの行インデックスと、PowerPointテーブルの行インデックスが1つずれる点(
row_idx + 1)に注意が必要です。 InchesとPt: PowerPoint上の位置やサイズは、ピクセルではなくインチ(Inches)やポイント(Pt)で指定するのが一般的です。これにより、印刷時やプロジェクター投影時のレイアウト崩れを防ぎやすくなります。
このスクリプトを使えば、実験が終わるたびにCSVを手動でコピペする必要はなくなります。実験スクリプトの最後にこのコードを呼び出せば、朝起きたときにはレポートが完成している状態を作れます。
5. python-pptx の活用事例
単にスライドを作るだけでなく、以下のような応用が考えられます。
定型レポートの完全自動化
週次、月次のKPI報告など、フォーマットが決まっているものは自動化の絶好の対象です。SQLでデータを取得し、Pandasで整形し、python-pptxで出力まで一気通貫で行えます。
テンプレートファイルの活用(おすすめ!)
コードだけで美しいデザイン(フォント、色、ロゴ配置)を作るのは大変です。
実務では、デザイナーや広報部門が作成した「会社指定のPowerPointテンプレート(.pptx)」を読み込み、その中の特定のプレースホルダーだけにデータを流し込む方法が最も効率的です。
# 既存のデザインテンプレートを読み込む
prs = Presentation("company_template.pptx")こうすることで、デザインの変更があった場合もPythonコードを修正する必要がなくなり、メンテナンス性が向上します。
まとめ
今回は、PythonでPowerPointを作成するpython-pptxについて、基本操作からPandas連携まで解説しました。
今回のポイント:
python-pptxを使えば、サーバーサイドでもPowerPoint生成が可能。- オブジェクト構造(Presentation > Slide > Shape)を理解することが重要。
- Pandas DataFrameをテーブルに変換するヘルパー関数を作ると、AI開発のレポーティングが捗る。
- デザインはコードで頑張らず、テンプレートファイルを読み込むのがプロのコツ。
プログラミングの力は、高度なアルゴリズムを実装するためだけでなく、こういった「日々の定型業務」をハックするためにも大いに役立ちます。空いた時間で、より本質的な分析やモデルの改善に取り組みましょう。
最後まで読んでいただきありがとうございました。


コメント