
こんにちはJS2IIUです。
日々のデータ分析やAIプロトタイピングにPythonを活用している皆さん、Streamlitを使っていますか?
数行のPythonコードでインタラクティブなWebアプリを作成できるStreamlitは、我々エンジニアにとって手放せないツールです。しかし、機能が増えるにつれて、「UI(ユーザーインターフェース)が少し野暮ったい」「画面がボタンだらけで見づらい」と感じたことはないでしょうか。
特に、設定項目やフィルタリング条件が増えると、ラジオボタン(st.radio)やマルチセレクト(st.multiselect)が画面を占領しがちです。
そこで今回紹介するのが、Streamlitの新しいウィジェット st.pills です。
これは、カプセル(錠剤)型のボタンを水平に並べるモダンなUIコンポーネントです。直感的で省スペース、かつスタイリッシュなこのウィジェットを使えば、あなたの作成するAIデモアプリやダッシュボードの品質が一段階上がること間違いありません。
本記事では、基本的な使い方から、実務で役立つデータフィルタリングへの応用まで、具体的なコードを交えて徹底解説します。今回もよろしくお願いします。
st.pillsとは何か?
st.pills は、一連の選択肢を「ピル(Pill)」と呼ばれる楕円形のボタンとして表示するウィジェットです。
これまでのStreamlitでは、選択肢を提示する場合、主に以下の2つが使われていました。
- st.radio: 選択肢が縦に並ぶため、場所を取る。
- st.multiselect: ドロップダウン形式なので場所は取らないが、選択肢が隠れており、ワンクリックで切り替えができない。
st.pills はこれらの中間に位置するような特性を持ちます。選択肢が常に表示されており(視認性が高い)、かつ水平に配置されるため縦方向のスペースを節約できます。特に、カテゴリのフィルタリングや、モードの切り替えといった操作に最適です。
基本的な使い方:単一選択(Single Selection)
まずは、最も基本的な「単一選択」の実装を見てみましょう。デフォルトでは、st.pills はラジオボタンのように、複数の選択肢から1つだけを選ぶ挙動になります。
以下のコードは、AIモデルの実行モードを選択させるシンプルな例です。
import streamlit as st
def main():
st.title("st.pills 基本的な使い方")
st.subheader("1. 単一選択モード")
# 選択肢のリストを定義
modes = ["高速モード", "高精度モード", "バランスモード"]
# st.pillsの配置
# label: ウィジェットのラベル(アクセシビリティのため設定推奨)
# options: 選択肢のリスト
selected_mode = st.pills(
label="実行モードを選択してください",
options=modes,
default="バランスモード" # 初期選択値を設定
)
# 選択された値の確認
st.write(f"現在の選択: **{selected_mode}**")
# 選択に応じた処理の分岐例
if selected_mode == "高速モード":
st.info("計算速度を優先して処理を行います。")
elif selected_mode == "高精度モード":
st.warning("処理に時間がかかりますが、最高精度で計算します。")
if __name__ == "__main__":
main()コード解説
st.pills(label, options, ...): ここが核心部分です。optionsにリストを渡すだけで、自動的にピル型のボタンが生成されます。- 戻り値: ユーザーがクリックしたボタンの文字列(例:”高速モード”)がそのまま返されます。何も選択されていない場合は
Noneが返ることもありますが、defaultパラメータを設定しておけば、初期状態でのNoneを防ぐことができます。 - UIの挙動: ユーザーが別の選択肢をクリックすると、前の選択は自動的に解除されます。直感的ですね。

応用的な使い方1:複数選択モード(selection_mode=”multi”)
データのフィルタリングなどを行う際、「複数のカテゴリを同時に選択したい」という要望は頻繁にあります。従来は st.multiselect を使っていましたが、st.pills でも selection_mode="multi" を指定することで同様のことが可能です。
import streamlit as st
def multi_select_demo():
st.subheader("2. 複数選択モード")
# 分析対象のタグリスト
tags = ["自然言語処理", "画像認識", "音声認識", "強化学習", "時系列分析"]
# selection_mode="multi" を指定することで複数選択が可能になる
selected_tags = st.pills(
label="興味のある分野を選択(複数可)",
options=tags,
selection_mode="multi",
default=["自然言語処理", "画像認識"] # 複数の初期値をリストで指定可能
)
# 戻り値の確認
st.write("選択されたタグリスト:")
st.code(selected_tags)
# ロジックへの応用例
if not selected_tags:
st.error("少なくとも1つの分野を選択してください。")
else:
st.success(f"{len(selected_tags)} 個の分野が選択されています。分析を開始します。")
if __name__ == "__main__":
multi_select_demo()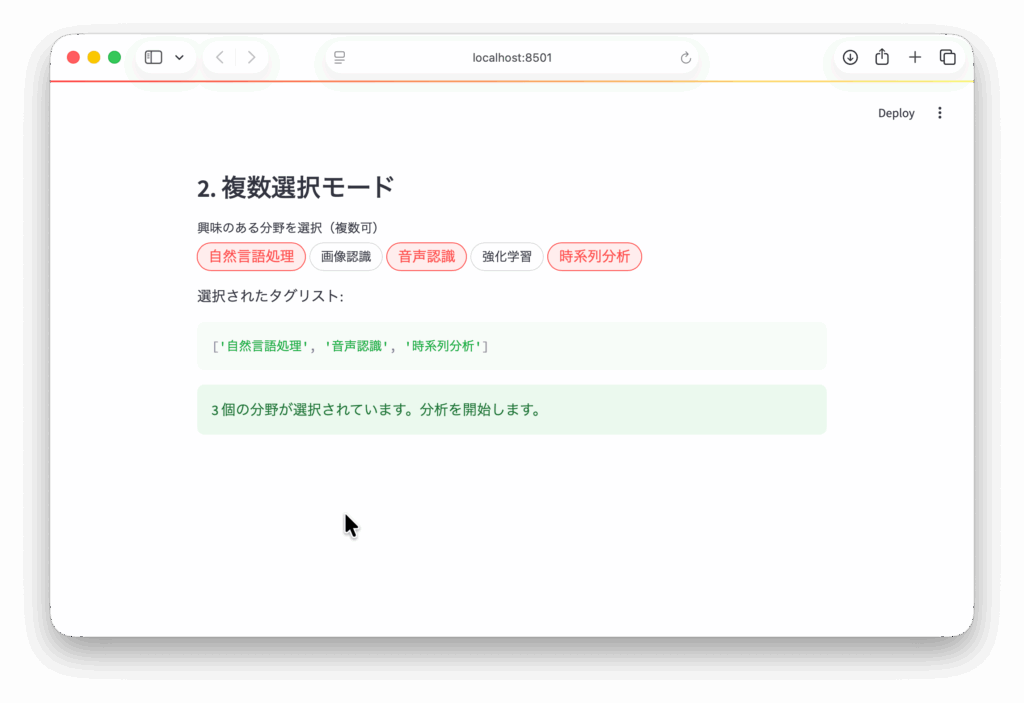
コード解説
selection_mode="multi": このパラメータを追加するだけで、挙動が大きく変わります。クリックしても他の選択が解除されず、トグル(ON/OFF)のような動作になります。- 戻り値の変化: 単一選択の時は「文字列」が返ってきましたが、複数選択モードでは「選択された文字列のリスト」が返ってきます(例:
['自然言語処理', '強化学習'])。 - 条件分岐: リストが空(誰も何も選択していない状態)の場合のハンドリングを忘れずに行いましょう。
応用的な使い方2:視認性の向上(IconsとFormat_func)
ただ文字が並んでいるだけでは、ユーザーの目には留まりにくいことがあります。st.pills には、各選択肢にアイコンを付与したり、表示テキストを加工したりする機能が備わっています。
アイコン(Icons)の追加
icons パラメータを使用すると、各オプションに対応するアイコン(絵文字やMaterial Iconsの名前)を表示できます。
表示形式の変換(Format_func)
format_func は、プログラム内部で扱う値(IDなど)と、ユーザーに表示する値(日本語ラベルなど)を分離したい場合に非常に便利です。
import streamlit as st
def advanced_ui_demo():
st.subheader("3. アイコンとフォーマット関数の活用")
# 内部的なキー(モデルID)のリスト
model_ids = ["gpt-4", "claude-3", "gemini-pro", "llama-3"]
# 表示用のマッピング辞書
display_names = {
"gpt-4": "GPT-4 (OpenAI)",
"claude-3": "Claude 3 (Anthropic)",
"gemini-pro": "Gemini Pro (Google)",
"llama-3": "Llama 3 (Meta)"
}
# アイコンのマッピング(ストリームリットの `pills` が `icons` を受け取らない
# 環境があるため、表示用ラベルに絵文字を含める方式に変更します)
model_icons = {
"gpt-4": "🤖",
"claude-3": "🧠",
"gemini-pro": "✨",
"llama-3": "🦙",
}
# `icons` 引数が使えない Streamlit バージョン向けに、format_func で絵文字を付加する
selected_model = st.pills(
label="使用するLLMを選択",
options=model_ids,
selection_mode="single",
format_func=lambda x: f"{model_icons.get(x, '')} {display_names.get(x, x)}",
default="gpt-4",
)
st.write("---")
st.write(f"内部処理用の値(ID): `{selected_model}`")
st.write(f"ユーザーに見えている値: **{display_names[selected_model]}**")
if __name__ == "__main__":
advanced_ui_demo()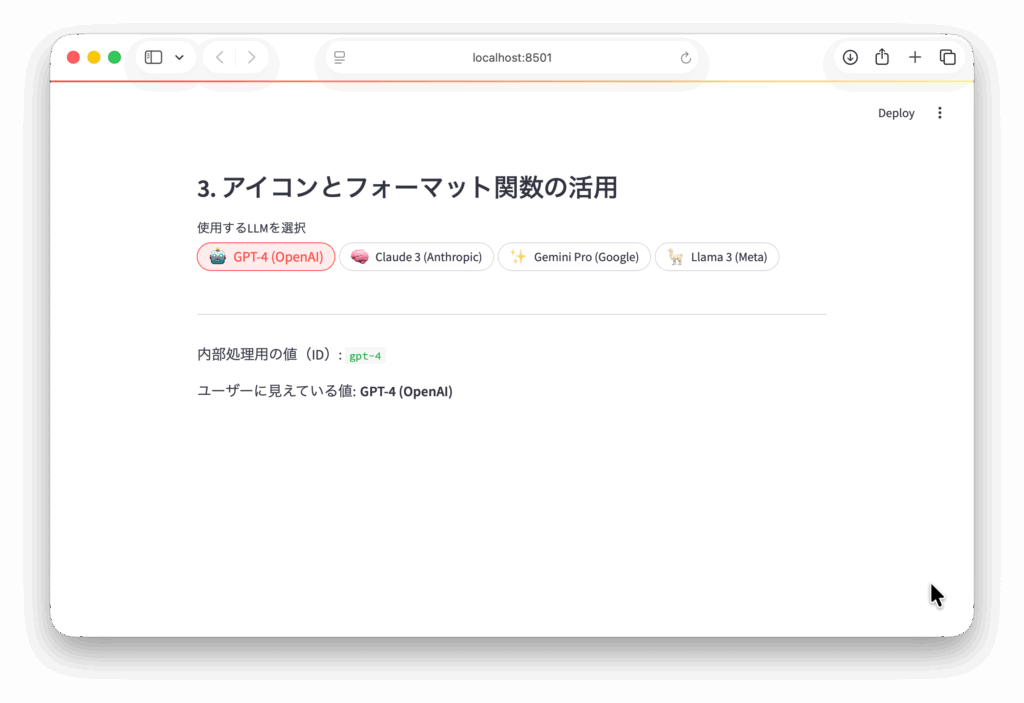
コード解説
icons:optionsのリストと同じ順序、同じ長さでアイコン文字列のリストを渡します。これにより、視覚的にどのボタンが何を表しているかが一瞬で伝わります。format_func:lambda x: ...のように関数を渡します。引数xにはoptionsの各要素(ここではmodel_idsの中身)が入ります。戻り値として「画面に表示したい文字列」を返します。- この機能のおかげで、コード内部では扱いやすい英語のIDを使いつつ、UI上では親切な日本語説明を表示するという構成が簡単に実現できます。
実践:機械学習データのフィルタリングアプリ
最後に、これまでの知識を総動員して、データサイエンスの現場でよくある「実験結果のフィルタリング」を行うアプリを作ってみましょう。Pandas DataFrameと組み合わせた実践的な例です。
ここでは、架空の機械学習モデルの評価データがあり、それを「モデルの種類」でフィルタリングしてテーブル表示するシーンを想定します。
import streamlit as st
import pandas as pd
import numpy as np
def data_app_demo():
st.title("📊 モデル評価ダッシュボード")
st.write("st.pillsを使ってデータを直感的にフィルタリングします。")
# 1. ダミーデータの作成
# 実際の開発ではCSVの読み込みやデータベース接続に相当します
data = pd.DataFrame({
"Model_Name": [f"Model_{i}" for i in range(1, 11)],
"Type": ["CNN", "Transformer", "CNN", "RNN", "Transformer",
"Transformer", "RNN", "CNN", "RNN", "Transformer"],
"Accuracy": np.random.uniform(0.75, 0.99, 10).round(3),
"Latency_ms": np.random.randint(20, 150, 10)
})
# 2. フィルタリングUIの構築
st.subheader("フィルタリング設定")
# データフレームからユニークなモデルタイプを取得
available_types = data["Type"].unique().tolist()
# アイコンの自動割り当て(簡易的なロジック)
def get_icon(model_type):
if model_type == "CNN": return "🖼️"
if model_type == "RNN": return "🌊"
if model_type == "Transformer": return "🚀"
return "❓"
# アイコン辞書を作成し、古い `icons=` 引数が未サポートな環境に備えて
# 表示ラベルに絵文字を付加する方式に切り替えます。
type_icons_map = {t: get_icon(t) for t in available_types}
# st.pillsによる複数選択フィルタ
selected_types = st.pills(
label="表示するモデルタイプを選択",
options=available_types,
selection_mode="multi",
default=available_types, # デフォルトは全選択
format_func=lambda x: f"{type_icons_map.get(x, '')} {x}",
)
# 3. データのフィルタリング処理
if not selected_types:
st.warning("表示するデータがありません。タイプを選択してください。")
filtered_df = pd.DataFrame() # 空のDF
else:
# 選択されたタイプに含まれる行だけを抽出
filtered_df = data[data["Type"].isin(selected_types)]
# 4. 結果の表示
st.divider()
# 2カラムレイアウトで見やすく表示
col1, col2 = st.columns([1, 1])
with col1:
st.caption(f"データ一覧 ({len(filtered_df)} 件)")
st.dataframe(filtered_df, use_container_width=True)
with col2:
if not filtered_df.empty:
st.caption("精度(Accuracy)の比較")
# Streamlit内蔵の簡易チャート機能
st.bar_chart(filtered_df.set_index("Model_Name")["Accuracy"])
if __name__ == "__main__":
data_app_demo()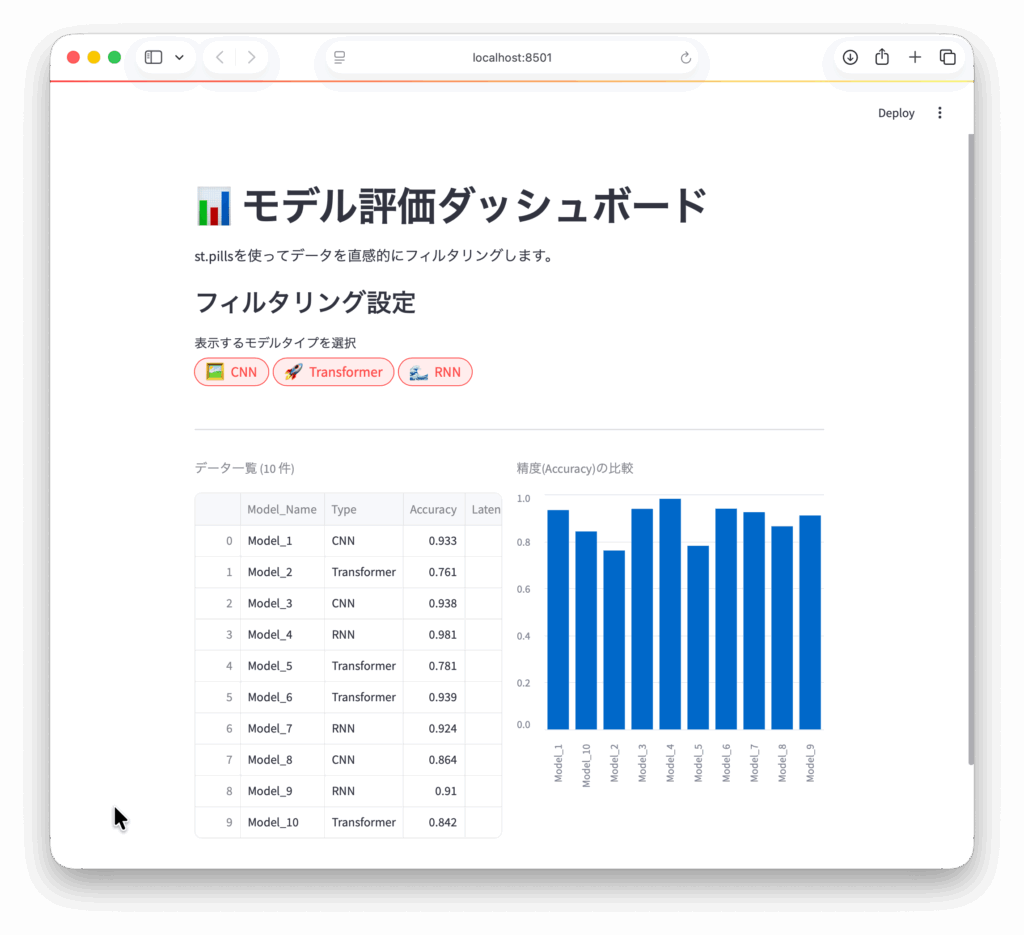
この実装のポイント
- 動的な選択肢の生成:
data["Type"].unique()を使うことで、データセットに含まれるカテゴリが自動的にst.pillsの選択肢になります。データが更新されてもコードを書き換える必要がありません。 isin()によるフィルタリング:selection_mode="multi"で得られたリスト(selected_types)を、Pandasのisin()メソッドにそのまま渡すことができます。これが非常に強力で、簡潔なコードで複雑なフィルタリングを実現できます。- インタラクティブな体験: ユーザーが「Transformer」のボタンをポチッと外せば、即座に表とグラフからTransformerモデルが消えます。このサクサク動く体験こそが、モダンなデータアプリの醍醐味です。
まとめ
本記事では、Streamlitの新しいウィジェット st.pills について解説しました。
- st.pills は、水平配置で視認性の高い、モダンな選択ウィジェットです。
- selection_mode=”multi” を使うことで、マルチセレクトの代替として強力に機能します。
- icons や format_func を活用すれば、ユーザーフレンドリーな表現が可能です。
- Pandasと組み合わせることで、直感的なデータフィルタリング機能を簡単に実装できます。
UIは単なる「見た目」ではありません。特にAIやデータ分析の分野では、複雑な結果をいかに人間に分かりやすく伝えるかが、プロジェクトの成功を左右します。st.radio で画面が埋め尽くされているアプリがあれば、ぜひ st.pills への置き換えを検討してみてください。
最後まで読んでいただきありがとうございます。


コメント