



こんにちは、JS2IIUです。
今回は時系列データの処理に欠かせない移動平均の計算です。Pandasを使えば簡単に計算することができます。今回もよろしくお願いします。
# 単純移動平均(5日間)
df["SMA_5"] = df["Value"].rolling(window=5).mean()

はじめに
時系列データを扱う際、データの変動を平滑化するために移動平均(Moving Average)を計算することは非常に有用です。移動平均は、データのノイズを取り除き、全体的なトレンドを把握するのに役立ちます。Pandasでは、時系列データを簡単に操作できる便利なメソッドが提供されており、その中でもrollingメソッドを使うことで移動平均の計算が可能です。
この記事では、移動平均の基本的な仕組みを解説した後、Pandasを用いて次の内容を実現する方法を説明します:
- シンプルな移動平均の計算
- 加重移動平均の計算
- 移動平均を可視化してトレンドを確認する方法
これにより、株価や気象データなどの時系列データをより深く理解するためのスキルを習得できます。
移動平均とは?
移動平均は、時系列データにおける一定期間の平均値を計算し、それを時系列に沿って更新していく手法です。これにより、データの短期的な変動を平滑化し、長期的なトレンドを抽出できます。
移動平均にはいくつかの種類がありますが、この記事では以下を取り上げます:
- 単純移動平均(Simple Moving Average, SMA): 一定期間のデータの単純な平均。
- 加重移動平均(Weighted Moving Average, WMA): 最近のデータに高い重みを与える平均。
移動平均を計算する方法
必要なライブラリのインポートとデータの準備
まず、Pandasをインポートし、サンプルの時系列データを準備します。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# サンプルデータの生成
np.random.seed(42)
date_range = pd.date_range(start="2024-01-01", periods=100, freq="D")
data = np.random.randn(100).cumsum() # ランダムウォークを生成
df = pd.DataFrame({"Date": date_range, "Value": data})
df.set_index("Date", inplace=True)
# データの確認
print(df.head())
このコードでは、ランダムな時系列データを生成し、DataFrameに格納しています。
データをプロットすると下図のようになります。

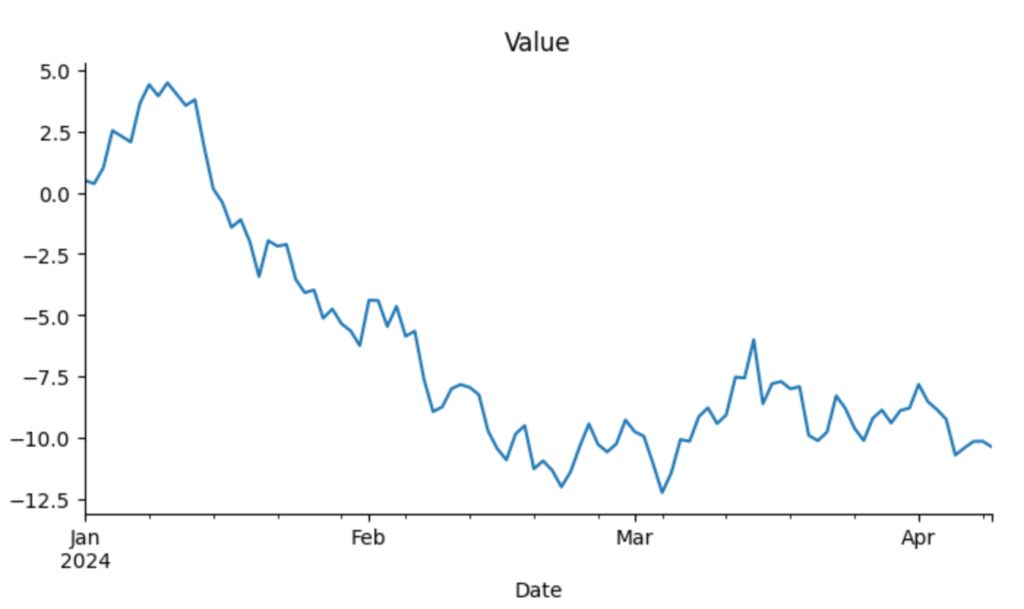
プロット用のコードです。短いコードでパッと確認したいときはPandasのplot()を使います。記事の後半で、まとめて綺麗にプロットするためのコードを紹介しています。
from matplotlib import pyplot as plt
df['Value'].plot(kind='line', figsize=(8, 4), title='Value')
plt.gca().spines[['top', 'right']].set_visible(False)
単純移動平均の計算
rollingメソッドを使用して単純移動平均を計算します。
# 単純移動平均(5日間)
df["SMA_5"] = df["Value"].rolling(window=5).mean()
# 結果の確認
print(df.head(10))
元のデータと移動平均を重ねてプロットしてみました。

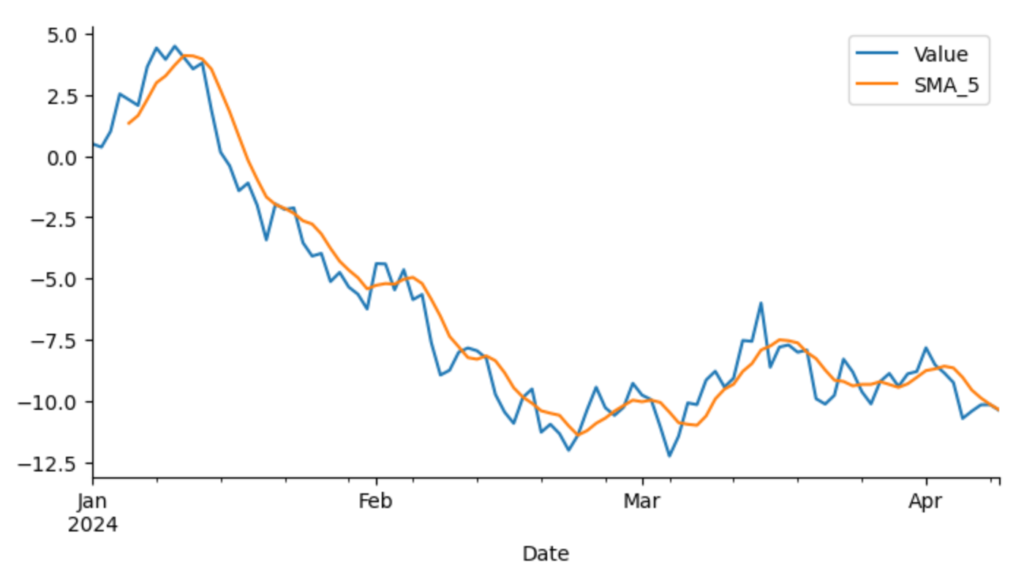
プロット用のコードです。
from matplotlib import pyplot as plt
df['Value'].plot(kind='line', figsize=(8, 4), label='Value')
df['SMA_5'].plot(kind='line', figsize=(8, 4), label='SMA_5')
plt.legend()
plt.gca().spines[['top', 'right']].set_visible(False)
解説
rolling(window=5): 過去5日間のデータを基に計算を行います。.mean(): ローリングウィンドウ内のデータの平均を算出します。
加重移動平均の計算
Pandasには直接加重移動平均を計算するメソッドはありませんが、applyを用いることでカスタム計算が可能です。
# 重みを定義
weights = np.array([0.1, 0.2, 0.3, 0.4]) # 最近のデータに高い重みを与える
# 加重移動平均(4日間)
df["WMA_4"] = df["Value"].rolling(window=4).apply(
lambda x: np.dot(x, weights) / weights.sum(), raw=True
)
# 結果の確認
print(df.head(10))
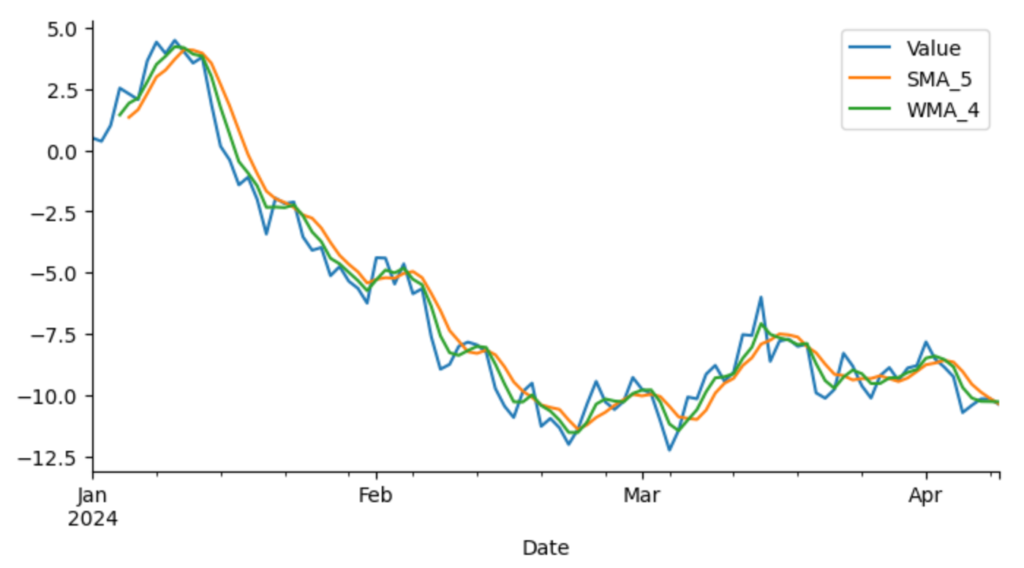
from matplotlib import pyplot as plt
df['Value'].plot(kind='line', figsize=(8, 4), label='Value')
df['SMA_5'].plot(kind='line', figsize=(8, 4), label='SMA_5')
df['WMA_4'].plot(kind='line', figsize=(8, 4), label='WMA_4')
plt.legend()
plt.gca().spines[['top', 'right']].set_visible(False)
解説
apply(lambda x: ...): ローリングウィンドウ内のデータに対してカスタム計算を適用します。np.dot(x, weights): 各データと重みの内積を計算します。
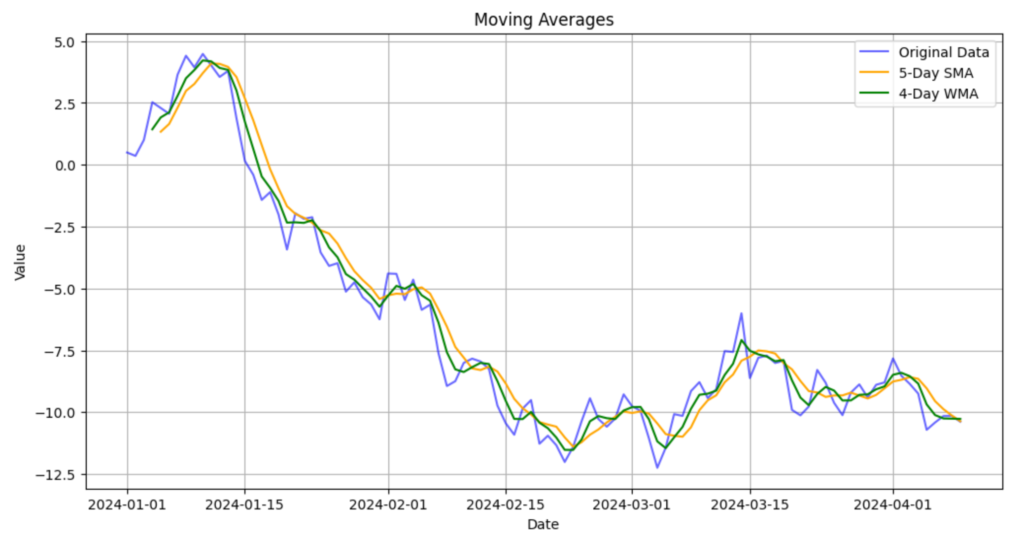
移動平均の可視化
移動平均をグラフで表示して、トレンドを視覚的に確認します。
# 可視化
plt.figure(figsize=(12, 6))
plt.plot(df.index, df["Value"], label="Original Data", color="blue", alpha=0.6)
plt.plot(df.index, df["SMA_5"], label="5-Day SMA", color="orange")
plt.plot(df.index, df["WMA_4"], label="4-Day WMA", color="green")
plt.title("Moving Averages")
plt.xlabel("Date")
plt.ylabel("Value")
plt.legend()
plt.grid()
plt.show()
解説
- オリジナルデータと移動平均をプロットすることで、データの変動とトレンドを比較できます。
alpha=0.6: データの透明度を調整し、重なりを見やすくしています。
まとめ
この記事では、Pandasを使用して時系列データに対する移動平均を計算する方法を紹介しました。単純移動平均はノイズの平滑化に役立ち、加重移動平均はより最近のデータに重きを置いたトレンド分析が可能です。移動平均は、株式や気象データなど多くの分野でデータの分析やモデリングに広く応用されています。ぜひご自身のデータ分析でも活用してください!
参考リンク
今回も少しだけPRです。
Pandasについて詳しく知りたいかた、もっと使いこなしたい方におすすめの本です。数年前に購入しましたが、今も手元に置いて時々見返しています。
「pandasクックブック Pythonによるデータ処理のレシピ」Theodore Petrou著、黒川利明訳。

最後まで読んでいただきありがとうございます。73